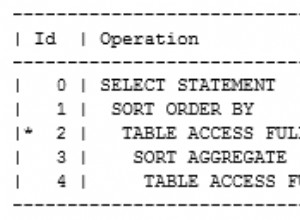
Il existe de nombreuses façons d'y parvenir avec les fonctions existantes. Vous pouvez utiliser le fonctions de fenêtre first_value() et last_value()
, combiné avec DISTINCT ou DISTINCT ON pour l'obtenir sans jointures ni sous-requêtes :
SELECT DISTINCT ON (userid)
userid
, last_value(rank) OVER w
- first_value(rank) OVER w AS rank_delta
FROM rankings
WINDOW w AS (PARTITION BY userid ORDER BY ts
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING);
Notez les cadres personnalisés pour les fonctions de fenêtre !
Ou vous pouvez utiliser des fonctions d'agrégation de base dans une sous-requête et JOIN :
SELECT userid, r2.rank - r1.rank AS rank_delta
FROM (
SELECT userid
, min(ts) AS first_ts
, max(ts) AS last_ts
FROM rankings
GROUP BY 1
) sub
JOIN rankings r1 USING (userid)
JOIN rankings r2 USING (userid)
WHERE r1.ts = first_ts
AND r2.ts = last_ts;
En supposant un (userid, rank) unique , ou vos exigences seraient ambiguës.
Shichinin pas de samouraï
Par demande dans les commentaires, idem uniquement pour les sept dernières lignes par ID utilisateur (ou autant qu'il est possible d'en trouver, s'il y en a moins) :
Encore une fois, l'une des nombreuses façons possibles. Mais je crois que c'est l'un des plus courts :
SELECT DISTINCT ON (userid)
userid
, first_value(rank) OVER w
- last_value(rank) OVER w AS rank_delta
FROM rankings
WINDOW w AS (PARTITION BY userid ORDER BY ts DESC
ROWS BETWEEN CURRENT ROW AND 7 FOLLOWING)
ORDER BY userid, ts DESC;
Notez l'ordre de tri inversé. La première ligne est l'entrée "la plus récente". Je couvre un cadre de (max.) 7 lignes et sélectionne uniquement les résultats de l'entrée la plus récente avec DISTINCT ON .