Si vous avez besoin d'un million de tables dans votre base de données, vous vous trompez.
Les tableaux sont destinés à représenter des données structurellement et conceptuellement différentes. Et je refuse de croire que vous travaillez avec un million de concepts différents dans votre application.
Parfois, les débutants pensent qu'ils devraient créer une table par utilisateur, par exemple. Mais "un utilisateur" est un concept, et vous stockez les mêmes informations pour chaque utilisateur (nom, e-mail, nom d'utilisateur, mot de passe, par exemple), il devrait donc en être un table, où chaque utilisateur est juste une ligne distincte.
Il semble que vous fassiez une erreur similaire, peut-être pas avec les utilisateurs, mais avec une autre abstraction dont vous avez beaucoup d'instances. Chaque instance doit être une ligne dans une seule table.
Si vous nous décrivez ce que vous essayez de stocker dans une base de données, nous pouvons presque certainement vous aider à comprendre comment cela devrait être mappé à des tables.
Modifier
après avoir lu vos commentaires (qui devraient vraiment être intégrés à la question elle-même), voici mes réflexions :
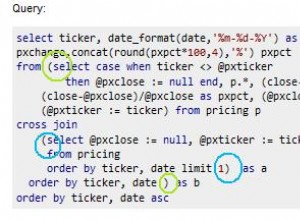
Si toutes les données sont structurées de la même manière (sous forme de triplets), vous pouvez simplement tout stocker dans une seule table à trois colonnes, puis ajouter les index nécessaires pour des recherches efficaces.
Si tous les prédicats sont connus à l'avance, vous pourriez faire une table par prédicat, mais je ne sais pas vraiment à quel point cela aurait du sens, même.
L'option la plus propre serait probablement d'avoir 4 tables :(id, subject) , (id, predicate) , (id, object) ,(subjectid, predicateid, objectid) .