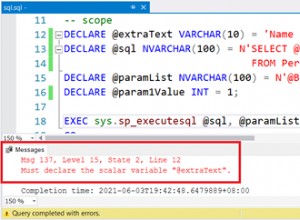
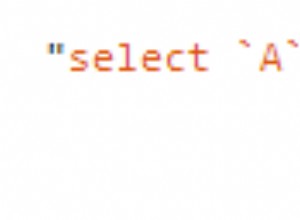
Je pense que j'ai compris cela. La réponse réside dans le fait que le multitraitement en Python est partagé - rien, donc tout l'espace mémoire est copié, fonctions et tout. Ainsi, pour chaque processus, même si le pid est différent, les espaces mémoire sont des copies les uns des autres et l'adresse de la connexion dans l'espace mémoire finit par être la même. La même raison explique pourquoi déclarer un pool de connexions global comme je l'ai fait au départ était inutile, chaque processus se retrouvant avec son propre pool de connexions avec une seule connexion active à la fois.