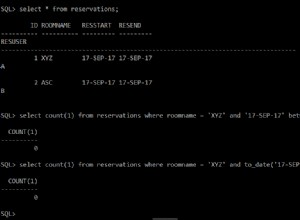
Puisque vous joignez deux grandes tables et qu'aucune condition ne pourrait filtrer les lignes, la seule stratégie de jointure efficace sera une jointure par hachage, et aucun index ne peut vous aider.
Il y aura d'abord un balayage séquentiel de l'une des tables, à partir de laquelle une structure de hachage est construite, puis il y aura un balayage séquentiel sur l'autre table, et le hachage sera sondé pour chaque ligne trouvée. Comment un index pourrait-il aider à cela ?
Vous pouvez vous attendre à ce qu'une telle opération prenne beaucoup de temps, mais il existe plusieurs façons d'accélérer l'opération :
-
Supprimer tous les index et contraintes sur
tx_input1avant que tu commences. Votre requête est l'un des exemples où un index n'aide pas du tout, mais en fait fait mal performances, car les index doivent être mis à jour avec la table. Recréez les index et les contraintes après avoir terminé avec leUPDATE. Selon le nombre d'index sur la table, vous pouvez vous attendre à un gain de performances allant de décent à massif. -
Augmentez la
work_memparamètre pour cette opération avec leSETcommande aussi haut que possible. Plus l'opération de hachage peut utiliser de mémoire, plus elle sera rapide. Avec une table aussi grande, vous finirez probablement par avoir des fichiers temporaires, mais vous pouvez toujours vous attendre à un gain de performances décent. -
Augmenter
checkpoint_segments(oumax_wal_sizeà partir de la version 9.6) à une valeur élevée afin qu'il y ait moins de points de contrôle lors de laUPDATEopération. -
Assurez-vous que les statistiques de table sur les deux tables sont exactes, afin que PostgreSQL puisse proposer une bonne estimation du nombre de compartiments de hachage à créer.
Après la UPDATE , si cela affecte un grand nombre de lignes, vous pouvez envisager d'exécuter VACUUM (FULL) sur tx_input1 pour se débarrasser du gonflement de la table qui en résulte. Cela verrouillera la table plus longtemps, alors faites-le pendant une fenêtre de maintenance. Cela réduira la taille de la table et, par conséquent, accélérera les analyses séquentielles.