Après clarification en commentaire.
Votre tâche telle que je la comprends :
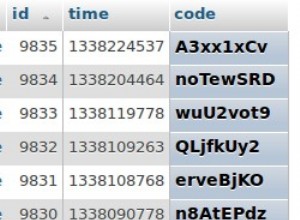
Vérifier tous les individuels fournis plages de dates (filter ) s'ils sont couverts par le combiné plages de dates des ensembles de codes de votre tableau (invoice ).
Cela peut être fait avec du SQL simple, mais ce n'est pas une tâche triviale . Les étapes pourraient être :
-
Fournissez des plages de dates comme filtres.
-
Combiner les plages de dates dans
invoicetableau par code.Peut entraîner une ou plusieurs plages par code. -
Recherchez les chevauchements entre les filtres et les factures combinées
-
Classer :entièrement couvert / partiellement couvert.Peut entraîner une couverture complète, une ou deux couvertures partielles ou aucune couverture.Réduire au niveau de couverture maximum.
-
Afficher une ligne pour chaque combinaison de (filtre, code) avec la couverture résultante, dans un ordre de tri raisonnable
Plages de filtres ad hoc
WITH filter(filter_id, startdate, enddate) AS (
VALUES
(1, '2012-05-01'::date, '2012-06-05'::date) -- list filters here.
,(2, '2012-05-01', '2012-05-31')
,(3, '2012-06-01', '2012-06-30')
)
SELECT * FROM filter;
Ou placez-les dans une table (temporaire) et utilisez la table à la place.
Combiner des plages de dates qui se chevauchent/adjacentes par code
WITH a AS (
SELECT code, startdate, enddate
,max(enddate) OVER (PARTITION BY code ORDER BY startdate) AS max_end
-- Calculate the cumulative maximum end of the ranges sorted by start
FROM invoice
), b AS (
SELECT *
,CASE WHEN lag(max_end) OVER (PARTITION BY code
ORDER BY startdate) + 2 > startdate
-- Compare to the cumulative maximum end of the last row.
-- Only if there is a gap, start a new group. Therefore the + 2.
THEN 0 ELSE 1 END AS step
FROM a
), c AS (
SELECT code, startdate, enddate, max_end
,sum(step) OVER (PARTITION BY code ORDER BY startdate) AS grp
-- Members of the same date range end up in the same grp
-- If there is a gap, the grp number is incremented one step
FROM b
)
SELECT code, grp
,min(startdate) AS startdate
,max(enddate) AS enddate
FROM c
GROUP BY 1, 2
ORDER BY 1, 2
SELECT final alternatif (peut-être plus rapide ou pas, il faudra tester) :
SELECT DISTINCT code, grp
,first_value(startdate) OVER w AS startdate
,last_value(enddate) OVER w AS enddate
FROM c
WINDOW W AS (PARTITION BY code, grp ORDER BY startdate
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
ORDER BY 1, 2;
Combiner en une seule requête
WITH
-- supply one or more filter values
filter(filter_id, startdate, enddate) AS (
VALUES
(1, '2012-05-01'::date, '2012-06-05'::date) -- cast values in first row
,(2, '2012-05-01', '2012-05-31')
,(3, '2012-06-01', '2012-06-30')
)
-- combine date ranges per code
,a AS (
SELECT code, startdate, enddate
,max(enddate) OVER (PARTITION BY code ORDER BY startdate) AS max_end
FROM invoice
), b AS (
SELECT *
,CASE WHEN (lag(max_end) OVER (PARTITION BY code ORDER BY startdate)
+ 2) > startdate THEN 0 ELSE 1 END AS step
FROM a
), c AS (
SELECT code, startdate, enddate, max_end
,sum(step) OVER (PARTITION BY code ORDER BY startdate) AS grp
FROM b
), i AS ( -- substitutes original invoice table
SELECT code, grp
,min(startdate) AS startdate
,max(enddate) AS enddate
FROM c
GROUP BY 1, 2
)
-- match filters
, x AS (
SELECT f.filter_id, i.code
,bool_or(f.startdate >= i.startdate
AND f.enddate <= i.enddate) AS full_cover
FROM filter f
JOIN i ON i.enddate >= f.startdate
AND i.startdate <= f.enddate -- only overlapping
GROUP BY 1,2
)
SELECT f.*, i.code
,CASE x.full_cover
WHEN TRUE THEN 'fully covered'
WHEN FALSE THEN 'partially covered'
ELSE 'invoice missing'
END AS covered
FROM (SELECT DISTINCT code FROM i) i
CROSS JOIN filter f -- all combinations of filter and code
LEFT JOIN x USING (filter_id, code) -- join in overlapping
ORDER BY filter_id, code;
Testé et fonctionne pour moi sur PostgreSQL 9.1.