Sidenote/AVIS DE NON-RESPONSABILITÉ :
C'est une mauvaise idée, car le temps de création de la table n'est pas fiable à 100 %, car la table peut avoir été supprimée en interne et recréée en raison d'opérations sur la table, telles que CLUSTER.
En dehors de cela, vous pouvez obtenir l'heure de création comme celle-ci (en supposant que example-table-name of t_benutzer ):
--select datname, datdba from pg_database;
--select relname, relfilenode from pg_class where relname ilike 't_benutzer';
-- (select relfilenode::text from pg_class where relname ilike 't_benutzer')
SELECT
pg_ls_dir
,
(
SELECT creation
FROM pg_stat_file('./base/'
||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
|| '/' || pg_ls_dir
)
) as createtime
FROM pg_ls_dir(
'./base/' ||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
)
WHERE pg_ls_dir = (SELECT relfilenode::text FROM pg_class WHERE relname ILIKE 't_benutzer')
Le secret est d'utiliser pg_stat_file sur le fichier de table respectif.
-- https://www.greenplumdba.com/greenplum-dba-faq/howtofindtablecreationdateingreenplum
select
pg_ls_dir
,
(
select
--size
--access
--modification
--change
creation
--isdir
from pg_stat_file(pg_ls_dir)
) as createtime
from pg_ls_dir('.');
Selon le commentaire de cet article PostgreSQL :heure de création de la table ce n'est pas fiable à 100 %, car la table peut avoir été supprimée et recréée en interne en raison d'opérations sur la table, telles que CLUSTER.
Aussi le motif
/main/base/<database id>/<table filenode id>
semble être faux, car sur ma machine, toutes les tables de différentes bases de données ont le même identifiant de base de données, et il semble que le dossier a été remplacé par un numéro d'inode arbitraire, vous devez donc trouver le dossier dont le numéro est le plus proche de celui de votre table id d'inode (nom de dossier max où id de dossier <=table_inode_id et nom de dossier est numérique)
La version simplifiée ressemble à ceci :
SELECT creation
FROM pg_stat_file(
'./base/'
||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
|| '/' || (SELECT relfilenode::text FROM pg_class WHERE relname ILIKE 't_benutzer')
)
Ensuite, vous pouvez utiliser information_schema et cte pour simplifier la requête ou créer votre propre vue :
;WITH CTE AS
(
SELECT
table_name
,
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE table_name)
) as folder
,(SELECT relfilenode FROM pg_class WHERE relname ILIKE table_name) filenode
FROM information_schema.tables
WHERE table_type = 'BASE TABLE'
AND table_schema = 'public'
)
SELECT
table_name
,(
SELECT creation
FROM pg_stat_file(
'./base/' || folder || '/' || filenode
)
) as creation_time
FROM CTE
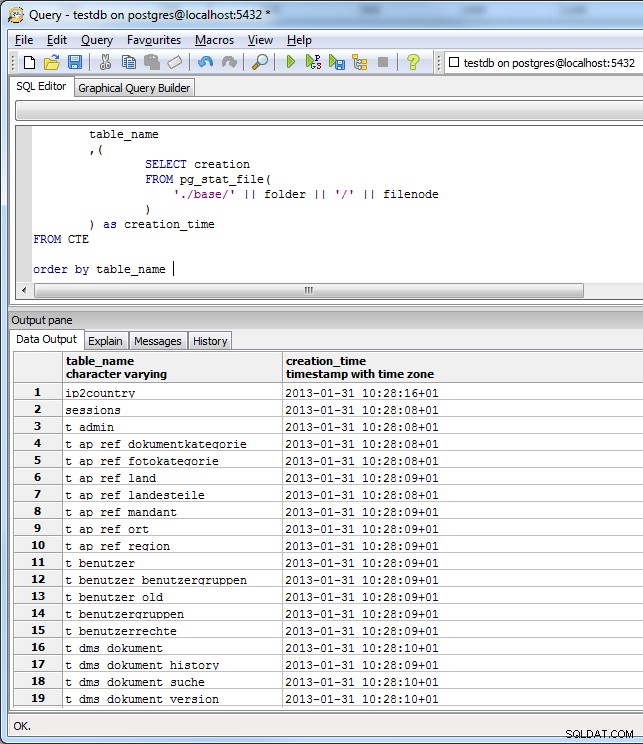
(toutes les tables créées avec le schéma nhibernate créent, donc plus ou moins la même heure sur toutes les tables sur la capture d'écran est correcte).
Pour les risques et les effets secondaires, utilisez votre cerveau et/ou demandez à votre médecin ou votre pharmacien ;)