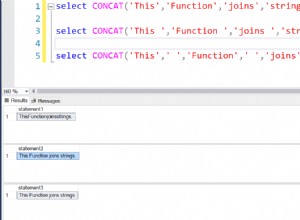
Le concept de similarité de trigramme repose sur le fait de diviser toute phrase en "trigrammes" (séquences de trois lettres consécutives) et de traiter le résultat comme un SET (c'est-à-dire que l'ordre n'a pas d'importance et que vous n'avez pas de valeurs répétées). Avant que la phrase ne soit considérée, deux espaces blancs sont ajoutés au début et un à la fin, et les espaces simples sont remplacés par des doubles.
Trigrammes sont un cas particulier de N-grammes .
L'ensemble de trigrammes correspondant à "Château blanc" se trouve en trouvant toutes les séquences de trois lettres qui y figurent :
chateau blanc
--- => ' c'
--- => ' ch'
--- => 'cha'
--- => 'hat'
--- => 'ate'
--- => 'tea'
--- => 'eau'
--- => 'au '
--- => 'u '
--- => ' b'
--- => ' bl'
--- => 'bla'
--- => 'lan'
--- => 'anc'
--- => 'nc '
En les triant et en supprimant les répétitions, vous obtenez :
' b'
' c'
' bl'
' ch'
'anc'
'ate'
'au '
'bla'
'cha'
'eau'
'hat'
'lan'
'nc '
'tea'
Cela peut être calculé par PostgreSQL au moyen de la fonction show_trgm :
SELECT show_trgm('Chateau blanc') AS A
A = [ b, c, bl, ch,anc,ate,au ,bla,cha,eau,hat,lan,nc ,tea]
... qui a 14 trigrammes. (Vérifiez pg_trgm ).
Et le trigramme correspondant à "Chateau Cheval Blanc" est :
SELECT show_trgm('Chateau Cheval Blanc') AS B
B = [ b, c, bl, ch,anc,ate,au ,bla,cha,che,eau,evl,hat,hev,la ,lan,nc ,tea,vla]
... qui a 19 trigrammes
Si vous comptez combien de trigrammes ont les deux ensembles en commun, vous trouvez qu'ils ont les suivants :
A intersect B =
[ b, c, bl, ch,anc,ate,au ,bla,cha,eau,hat,lan,nc ,tea]
et ceux qu'ils ont au total sont :
A union B =
[ b, c, bl, ch,anc,ate,au ,bla,cha,che,eau,evl,hat,hev,la ,lan,nc ,tea,vla]
Autrement dit, les deux phrases ont 14 trigrammes en commun, et 19 au total.
La similarité est calculée comme suit :
similarity = 14 / 19
Vous pouvez le vérifier avec :
SELECT
cast(14.0/19.0 as real) AS computed_result,
similarity('Chateau blanc', 'chateau cheval blanc') AS function_in_pg
et vous verrez que vous obtenez :0.736842
... qui explique comment la similarité est calculée, et pourquoi vous obtenez les valeurs que vous obtenez.
REMARQUE :Vous pouvez calculer l'intersection et l'union au moyen de :
SELECT
array_agg(t) AS in_common
FROM
(
SELECT unnest(show_trgm('Chateau blanc')) AS t
INTERSECT
SELECT unnest(show_trgm('chateau chevla blanc')) AS t
ORDER BY t
) AS trigrams_in_common ;
SELECT
array_agg(t) AS in_total
FROM
(
SELECT unnest(show_trgm('Chateau blanc')) AS t
UNION
SELECT unnest(show_trgm('chateau chevla blanc')) AS t
) AS trigrams_in_total ;
Et c'est une façon d'explorer la similarité de différentes paires de phrases :
WITH p AS
(
SELECT
'This is just a sentence I''ve invented'::text AS f1,
'This is just a sentence I''ve also invented'::text AS f2
),
t1 AS
(
SELECT unnest(show_trgm(f1)) FROM p
),
t2 AS
(
SELECT unnest(show_trgm(f2)) FROM p
),
x AS
(
SELECT
(SELECT count(*) FROM
(SELECT * FROM t1 INTERSECT SELECT * FROM t2) AS s0)::integer AS same,
(SELECT count(*) FROM
(SELECT * FROM t1 UNION SELECT * FROM t2) AS s0)::integer AS total,
similarity(f1, f2) AS sim_2
FROM
p
)
SELECT
same, total, same::real/total::real AS sim_1, sim_2
FROM
x ;
Vous pouvez le vérifier sur Rextester