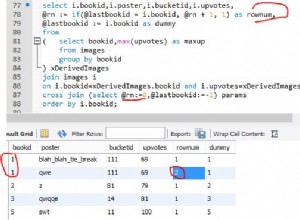
La limite de longueur imposée par varchar(N) types et calculés par la length la fonction est en caractères, pas en octets. Donc 'abcdef'::char(3) est tronqué en 'abc' mais 'a€cdef'::char(3) est tronqué en 'a€c' , même dans le contexte d'une base de données encodée en UTF-8, où 'a€c' est encodé sur 5 octets.
Si la restauration d'un fichier de vidage s'est plaint que 'Mér' n'irait pas dans un varchar(3) colonne, qui suggère que vous restaurez un fichier de vidage codé UTF-8 dans une base de données SQL_ASCII.
Par exemple, j'ai fait ceci dans une base de données UTF-8 :
create schema so4249745;
create table so4249745.t(key varchar(3) primary key);
insert into so4249745.t values('Mér');
Et ensuite vidé ceci et essayé de le charger dans une base de données SQL_ASCII :
pg_dump -f dump.sql --schema=so4249745 --table=t
createdb -E SQL_ASCII -T template0 enctest
psql -f dump.sql enctest
Et bien sûr :
psql:dump.sql:34: ERROR: value too long for type character varying(3)
CONTEXT: COPY t, line 1, column key: "Mér"
En revanche, si je crée la base de données enctest en encodant LATIN1 ou UTF8, elle se charge correctement.
Ce problème se produit en raison d'une combinaison de vidage d'une base de données avec un codage de caractères multi-octets et d'une tentative de restauration dans une base de données SQL_ASCII. L'utilisation de SQL_ASCII désactive essentiellement le transcodage des données client en données serveur et suppose un octet par caractère, laissant aux clients la responsabilité d'utiliser la bonne table de caractères. Étant donné que le fichier de vidage contient la chaîne stockée au format UTF-8, c'est-à-dire quatre octets, une base de données SQL_ASCII considère cela comme quatre caractères et la considère donc comme une violation de la contrainte. Et il imprime la valeur, que mon terminal réassemble ensuite en trois caractères.