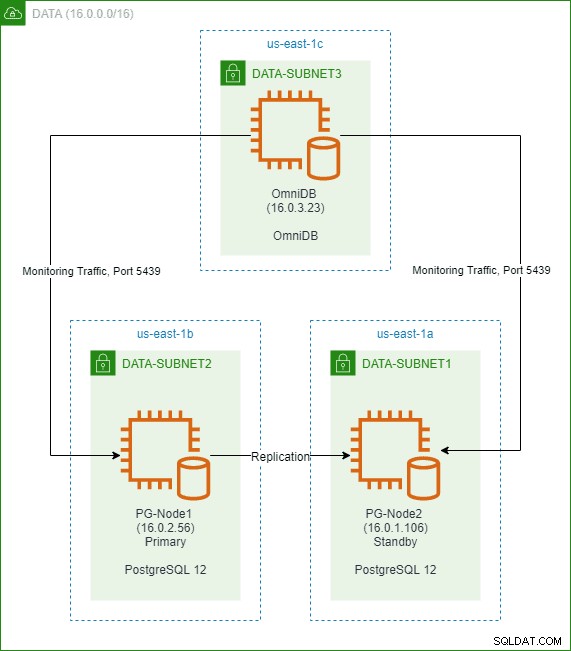
Dans un article précédent de cette série, nous avons créé un cluster PostgreSQL 12 à deux nœuds dans le cloud AWS. Nous avons également installé et configuré 2ndQuadrant OmniDB dans un troisième nœud. L'image ci-dessous montre l'architecture :
Nous pourrions nous connecter à la fois au nœud principal et au nœud de secours à partir de l'interface utilisateur Web d'OmniDB. Nous avons ensuite restauré un exemple de base de données appelé "dvdrental" dans le nœud principal qui a commencé à se répliquer sur le serveur de secours.
Dans cette partie de la série, nous apprendrons à créer et à utiliser un tableau de bord de surveillance dans OmniDB. Les administrateurs de base de données et les équipes d'exploitation préfèrent souvent les outils graphiques plutôt que les requêtes complexes pour inspecter visuellement la santé de la base de données. OmniDB est livré avec un certain nombre de widgets importants qui peuvent être facilement utilisés dans un tableau de bord de surveillance. Comme nous le verrons plus tard, il permet également aux utilisateurs d'écrire leurs propres widgets de surveillance.
Création d'un tableau de bord de suivi des performances
Commençons par le tableau de bord par défaut fourni par OmniDB.
Dans l'image ci-dessous, nous sommes connectés au nœud principal (PG-Node1). Nous faisons un clic droit sur le nom de l'instance, puis dans le menu contextuel, choisissez "Moniteur", puis sélectionnez "Tableau de bord".
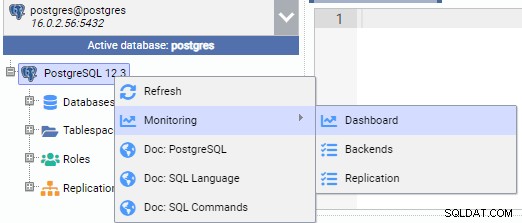
Cela ouvre un tableau de bord avec quelques widgets.
En termes OmniDB, les widgets rectangulaires du tableau de bord sont appelés Unités de surveillance . Chacune de ces unités affiche une métrique spécifique de l'instance PostgreSQL à laquelle elle est connectée et actualise dynamiquement ses données.
Comprendre les unités de surveillance
OmniDB est fourni avec quatre types d'unités de surveillance :
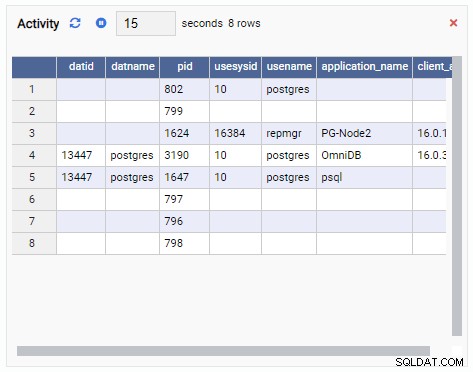
- Une grille est une structure tabulaire qui affiche le résultat d'une requête. Par exemple, cela peut être la sortie de SELECT * FROM pg_stat_replication. Une grille ressemble à ceci :
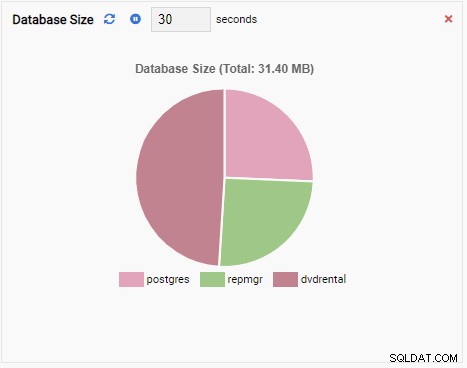
- Un graphique affiche les données sous forme graphique, comme des lignes ou des camemberts. Lorsqu'il est actualisé, l'ensemble du graphique est redessiné à l'écran avec une nouvelle valeur et l'ancienne valeur a disparu. Avec ces unités de surveillance, nous ne pouvons voir que la valeur actuelle de la métrique. Voici un exemple de graphique :
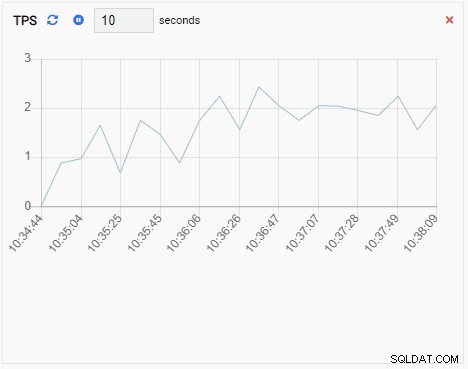
- Un ajout de graphique est également une unité de surveillance de type graphique, sauf lorsqu'elle est actualisée, elle ajoute la nouvelle valeur à la série existante. Avec Chart-Append, nous pouvons facilement voir les tendances au fil du temps. Voici un exemple :
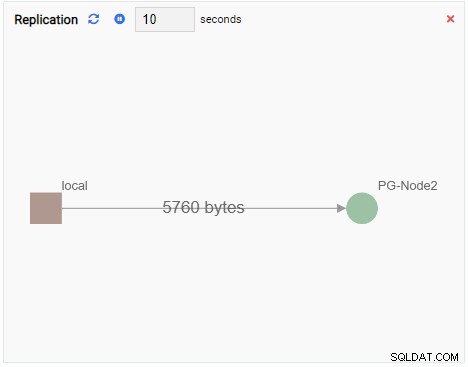
- Un graphique montre les relations entre les instances de cluster PostgreSQL et une métrique associée. Comme l'unité de surveillance graphique, une unité de surveillance graphique actualise également son ancienne valeur avec une nouvelle. L'image ci-dessous montre que le nœud actuel (PG-Node1) se réplique sur le PG-Node2 :
Chaque unité de surveillance a un certain nombre d'éléments communs :
- Le nom de l'unité de surveillance
- Un bouton "Actualiser" pour actualiser manuellement l'unité
- Un bouton "pause" pour arrêter temporairement l'actualisation de l'unité de surveillance
- Une zone de texte indiquant l'intervalle d'actualisation actuel. Cela peut être changé
- Un bouton "fermer" (croix rouge) pour supprimer l'unité de surveillance du tableau de bord
- La zone de dessin réelle de la surveillance
Unités de surveillance pré-construites
OmniDB est livré avec un certain nombre d'unités de surveillance pour PostgreSQL que nous pouvons ajouter à notre tableau de bord. Pour accéder à ces unités, nous cliquons sur le bouton "Gérer les unités" en haut du tableau de bord :
Cela ouvre la liste "Gérer les unités" :
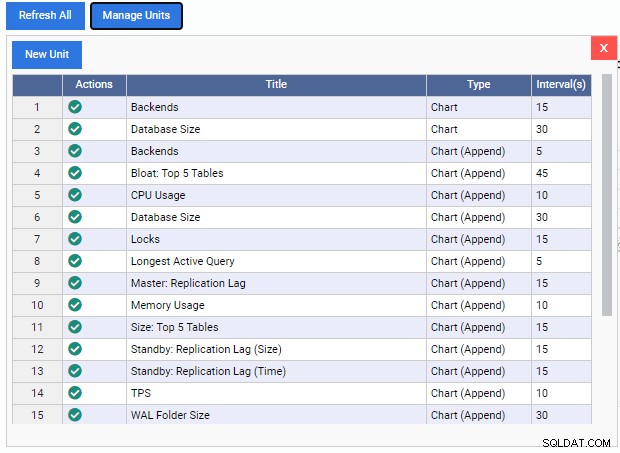
Comme nous pouvons le voir, il y a peu d'unités de surveillance pré-construites ici. Les codes de ces unités de surveillance sont téléchargeables gratuitement à partir du référentiel GitHub de 2ndQuadrant. Chaque unité répertoriée ici affiche son nom, son type (Chart, Chart Append, Graph ou Grid) et le taux de rafraîchissement par défaut.
Pour ajouter une unité de surveillance au tableau de bord, il suffit de cliquer sur la coche verte sous la colonne « Actions » pour cette unité. Nous pouvons mélanger et assortir différentes unités de surveillance pour créer le tableau de bord que nous voulons.
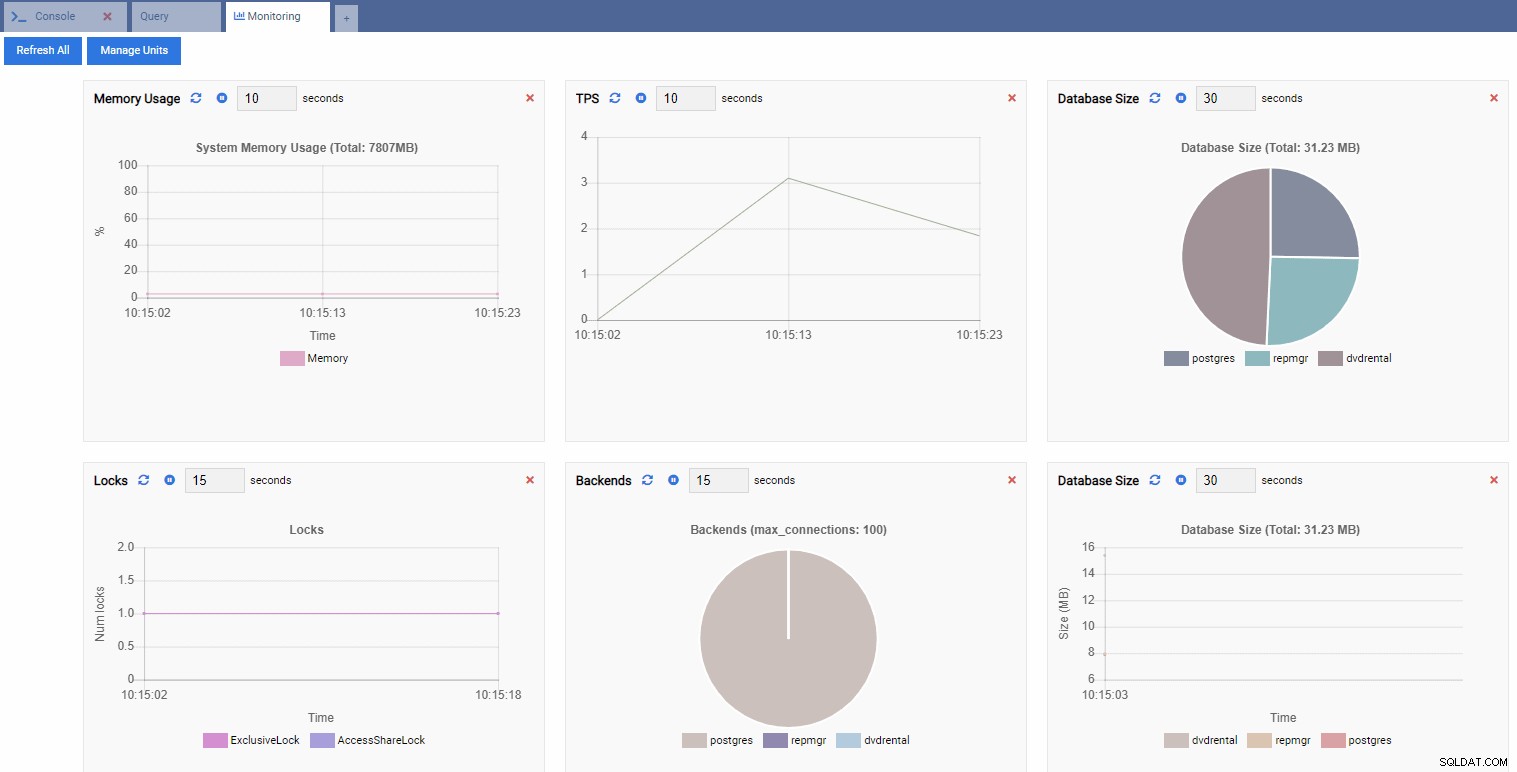
Dans l'image ci-dessous, nous avons ajouté les unités suivantes pour notre tableau de bord de suivi des performances et supprimé tout le reste :
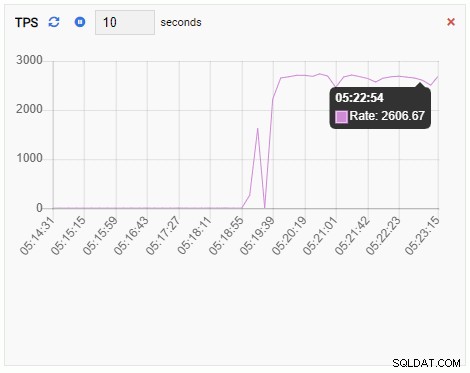
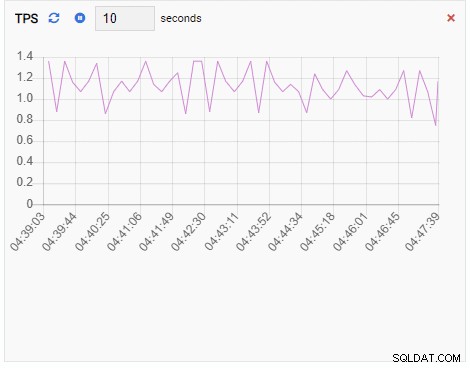
TPS (transaction par seconde) :
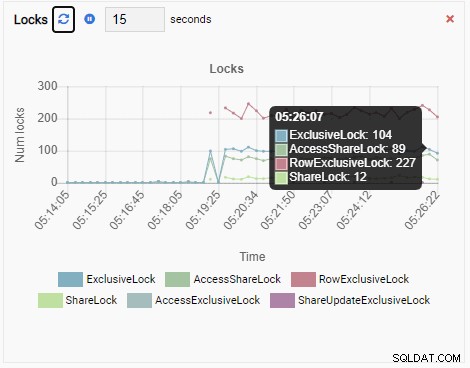
Nombre de serrures :
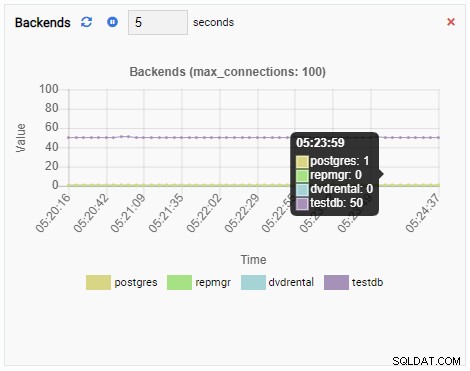
Nombre de backend :
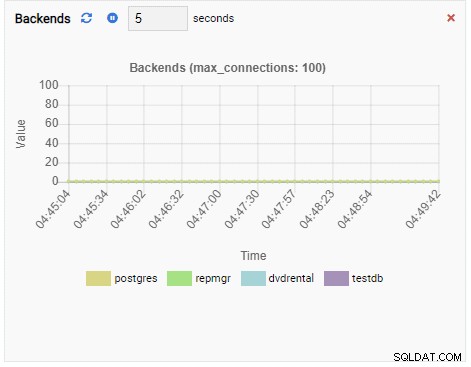
Étant donné que notre instance est inactive, nous pouvons voir que les valeurs TPS, Locks et Backends sont minimales.
Tester le tableau de bord de surveillance
Nous allons maintenant exécuter pgbench dans notre nœud principal (PG-Node1). pgbench est un outil d'analyse comparative simple fourni avec PostgreSQL. Comme la plupart des autres outils de ce type, pgbench crée un exemple de schéma et de tables de systèmes OLTP dans une base de données lors de son initialisation. Après cela, il peut émuler plusieurs connexions client, chacune exécutant un certain nombre de transactions sur la base de données. Dans ce cas, nous n'évaluerons pas le nœud principal de PostgreSQL ; nous ne créerons que la base de données pour pgbench et verrons si nos unités de surveillance du tableau de bord détectent le changement dans la santé du système.
Tout d'abord, nous créons une base de données pour pgbench dans le nœud principal :
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb";CREATE DATABASE
Ensuite, nous initialisons la base de données "testdb" pour pgbench :
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbsuppression d'anciennes tables...création de tables...génération data...100000 tuples sur 2000000 (5%) fait (0,02 s écoulé, 0,43 s restant)200000 tuples sur 2000000 (10%) fait (0,05 s écoulé, 0,41 s restant)……2000000 tuples sur 2000000 (100%) fait (écoulé 1,84 s, restant 0,00 s)vide...création de clés primaires...fait.
Avec la base de données initialisée, nous commençons maintenant le processus de chargement proprement dit. Dans l'extrait de code ci-dessous, nous demandons à pgbench de démarrer avec 50 connexions client simultanées sur la base de données testdb, chaque connexion exécutant 100 000 transactions sur ses tables. Le test de charge s'exécutera sur deux threads.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbstarting vacuum...end.……Si nous revenons maintenant à notre tableau de bord OmniDB, nous constatons que les unités de surveillance affichent des résultats très différents.
La métrique TPS affiche une valeur assez élevée. Il y a un saut soudain de moins de 2 à plus de 2 000 :
Le nombre de backends a augmenté. Comme prévu, testdb dispose de 50 connexions alors que d'autres bases de données sont inactives :
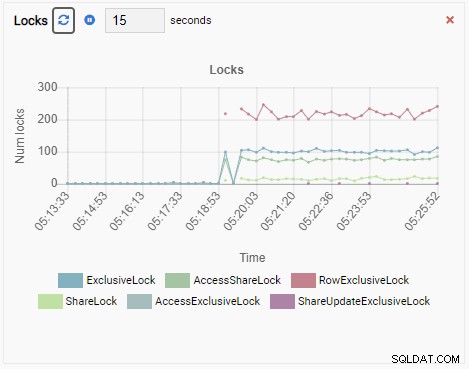
Et enfin, le nombre de verrous exclusifs de ligne dans la base de données testdb est également élevé :
Maintenant imaginez ceci. Vous êtes DBA et vous utilisez OmniDB pour gérer un parc d'instances PostgreSQL. Vous recevez un appel pour enquêter sur le ralentissement des performances dans l'une des instances.
En utilisant un tableau de bord comme celui que nous venons de voir (bien qu'il soit très simple), vous pouvez facilement trouver la cause racine. Vous pouvez vérifier le nombre de backends, de verrous, de mémoire disponible, etc. pour voir ce qui cause le problème.
Et c'est là qu'OmniDB peut être un outil vraiment utile.
Création d'unités de surveillance personnalisées
Parfois, nous aurons besoin de créer nos propres unités de surveillance. Pour écrire une nouvelle unité de surveillance, nous cliquons sur le bouton "Nouvelle unité" dans la liste "Gérer les unités". Cela ouvre un nouvel onglet avec un canevas vide pour écrire du code :
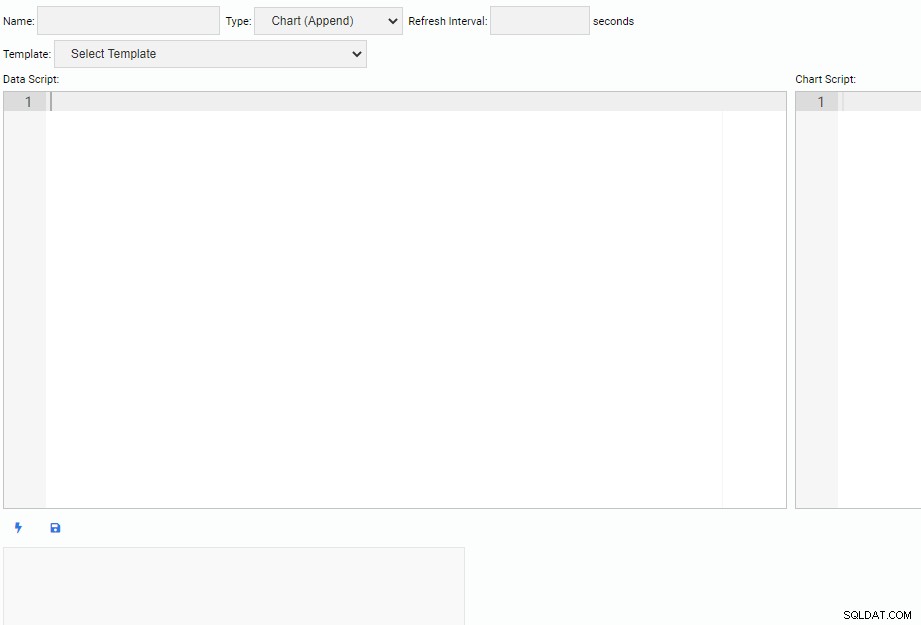
En haut de l'écran, nous devons spécifier un nom pour notre unité de surveillance, sélectionner son type et spécifier son intervalle d'actualisation par défaut. Nous pouvons également sélectionner une unité existante comme modèle.
Sous la section d'en-tête, il y a deux zones de texte. L'éditeur "Data Script" est l'endroit où nous écrivons du code pour obtenir des données pour notre unité de surveillance. Chaque fois qu'une unité est actualisée, le code du script de données s'exécutera. L'éditeur "Chart Script" est l'endroit où nous écrivons le code pour dessiner l'unité réelle. Ceci est exécuté lorsque l'unité est piochée pour la première fois.
Tout le code du script de données est écrit en Python. Pour l'unité de surveillance de type graphique, OmniDB a besoin que le script de graphique soit écrit dans Chart.js.
Nous allons maintenant créer une unité de surveillance pour afficher les 5 tables les plus importantes de la base de données actuelle. En fonction de la base de données sélectionnée dans OmniDB, l'unité de surveillance modifiera son affichage pour refléter les noms des cinq plus grandes tables de cette base de données.
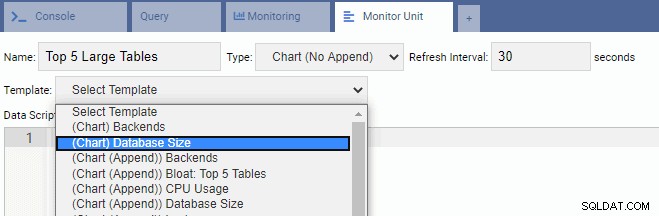
Pour écrire une nouvelle unité, il est préférable de commencer avec un modèle existant et de modifier son code. Cela permettra d'économiser du temps et des efforts. Dans l'image suivante, nous avons nommé notre unité de surveillance "Top 5 Large Tables". Nous l'avons choisi pour être de type graphique (sans ajout) et fourni un taux de rafraîchissement de 30 secondes. Nous avons également basé notre unité de surveillance sur le modèle de taille de la base de données :
La zone de texte Data Script est automatiquement renseignée avec le code de l'unité de surveillance de la taille de la base de données :
from datetime import datetimefrom random import randintdatabases =connection.Query(''' SELECT d.datname AS datname, round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size FROM pg_catalog.pg_database d WHERE d. datname not in ('template0','template1')''')data =[]color =[]label =[]for db in databases.Rows : data.append(db["size"]) color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "labels ":label, "datasets":[ { "data":data, "backgroundColor":color, "label":"Dataset 1" } ], "title":"Taille de la base de données (Total :" + str(total_size) + " Mo)"}Et la zone de texte Chart Script est également renseignée avec le code :
total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "type":"pie" , "data": Aucun, "options":{ "responsive":True, "title":{ "display":True, "text":"Taille de la base de données (Total :" + str(total_size) + " Mo)" } }}Nous pouvons modifier le script de données pour obtenir les 5 premières grandes tables de la base de données. Dans le script ci-dessous, nous avons conservé la majeure partie du code d'origine, à l'exception de l'instruction SQL :
from datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tablename", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid =C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') AND C.relkind <> 'i' AND nspname !~ '^pg_toast' ORDER PAR 2 DESC LIMIT 5 ;''')data =[]color =[]label =[]for table in tables.Rows : data.append(table["table_size"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(table["tablename" ])result ={ "labels":label, "datasets":[ { "data":data, "backgroundColor":color, "label":"Top 5 Large Tables" } ]}Ici, nous obtenons la taille combinée de chaque table et de ses index dans la base de données actuelle. Nous trions les résultats par ordre décroissant et sélectionnons les cinq premières lignes.
Ensuite, nous remplissons trois tableaux Python en itérant sur le jeu de résultats.
Enfin, nous construisons une chaîne JSON basée sur les valeurs des tableaux.
Dans la zone de texte Chart Script, nous avons modifié le code pour supprimer la commande SQL d'origine. Ici, nous ne précisons que l'aspect cosmétique de la charte. Nous définissons le graphique comme un type de tarte et lui donnons un titre :
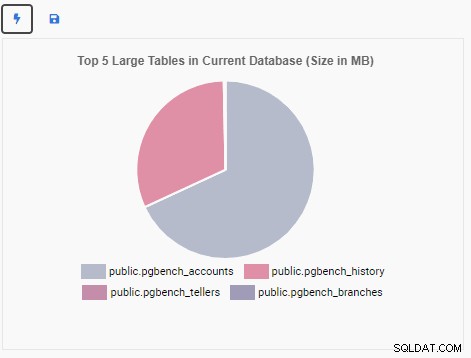
result ={ "type":"pie", "data": Aucun, "options":{ "responsive":Vrai, "title":{ "display":True, "text":"Top 5 Large Tables dans la base de données actuelle (taille en Mo) } }}Nous pouvons maintenant tester l'unité en cliquant sur l'icône de l'éclair. Cela affichera la nouvelle unité de surveillance dans la zone de dessin d'aperçu :
Ensuite, nous sauvegardons l'unité en cliquant sur l'icône du disque. Une boîte de message confirme que l'unité a été enregistrée :
Nous revenons maintenant à notre tableau de bord de surveillance et ajoutons la nouvelle unité de surveillance :
Remarquez comment nous avons deux autres icônes sous la colonne "Actions" pour notre unité de surveillance personnalisée. L'un sert à le modifier, l'autre à le supprimer d'OmniDB.
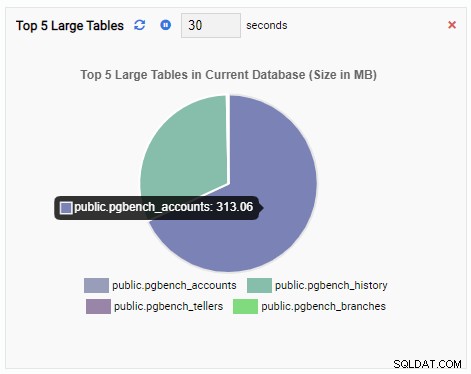
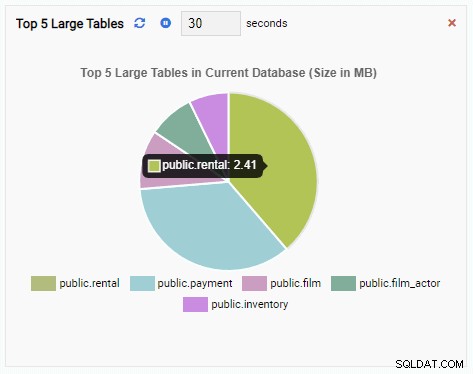
L'unité de surveillance "Top 5 Large Tables" affiche désormais les cinq plus grandes tables de la base de données actuelle :
Si nous fermons le tableau de bord, passons à une autre base de données à partir du volet de navigation et rouvrons le tableau de bord, nous verrons que l'unité de surveillance a changé pour refléter les tables de cette base de données :
Derniers mots
Ceci conclut notre série en deux parties sur OmniDB. Comme nous l'avons vu, OmniDB dispose d'unités de surveillance astucieuses que les DBA PostgreSQL trouveront utiles pour le suivi des performances. Nous avons vu comment nous pouvons utiliser ces unités pour identifier les goulots d'étranglement potentiels dans le serveur. Nous avons également vu comment créer nos propres unités personnalisées. Les lecteurs sont encouragés à créer et à tester des unités de surveillance des performances pour leurs charges de travail spécifiques. 2ndQuadrant accueille toute contribution au référentiel GitHub de l'unité de surveillance OmniDB.