Ansible est tout simplement génial et PostgreSQL est sûrement génial, voyons comment ils fonctionnent étonnamment ensemble !

====================Annonce en prime time ! ====================
PGConf Europe 2015 aura lieu du 27 au 30 octobre à Vienne cette année.
Je suppose que vous êtes peut-être intéressé par la gestion de la configuration, l'orchestration des serveurs, le déploiement automatisé (c'est pourquoi vous lisez cet article de blog, n'est-ce pas ?) et que vous aimez travailler avec PostgreSQL (bien sûr) sur AWS (en option), alors vous voudrez peut-être participer à mon exposé "Gérer PostgreSQL avec Ansible" le 28 octobre, de 15 à 15h50.
Veuillez consulter le calendrier incroyable et ne manquez pas l'occasion d'assister au plus grand événement PostgreSQL d'Europe !
J'espère vous y voir, oui j'aime boire du café après les discussions 🙂
====================Annonce en prime time ! ====================
Qu'est-ce qu'Ansible et comment ça marche ?
La devise d'Ansible est "une automatisation informatique open source simple, sans agent et puissante ” en citant des documents Ansible.
Comme le montre la figure ci-dessous, la page d'accueil d'Ansible indique que les principaux domaines d'utilisation d'Ansible sont :l'approvisionnement, la gestion de la configuration, le déploiement d'applications, la livraison continue, la sécurité et la conformité, l'orchestration. Le menu de présentation indique également sur quelles plates-formes nous pouvons intégrer Ansible, c'est-à-dire AWS, Docker, OpenStack, Red Hat, Windows.
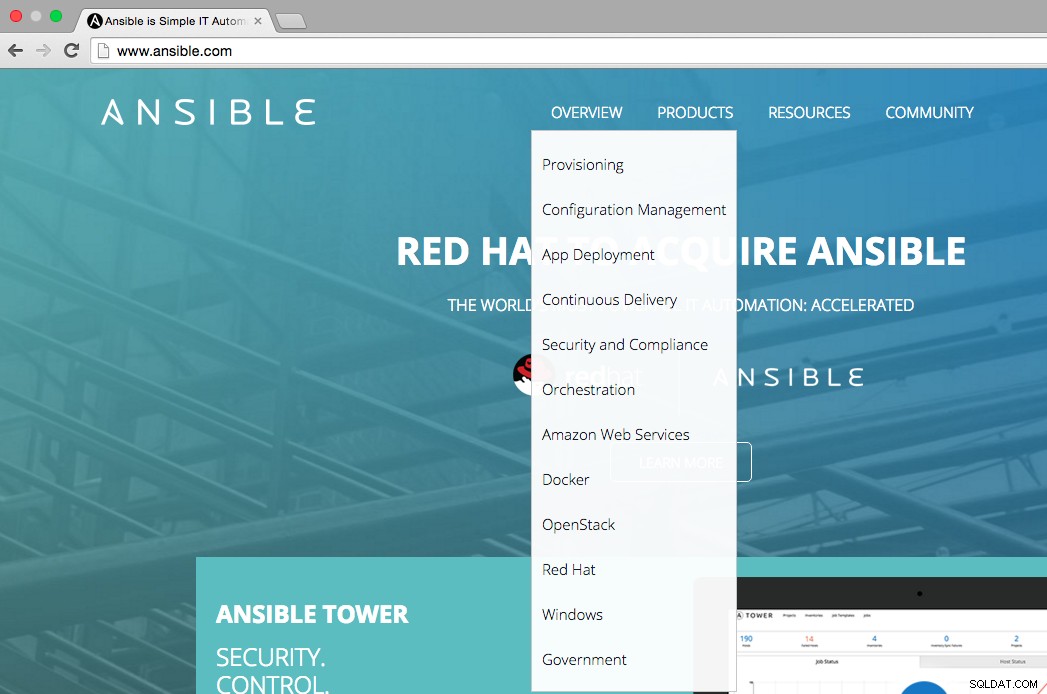
Examinons les principaux cas d'utilisation d'Ansible pour comprendre son fonctionnement et son utilité pour les environnements informatiques.
Provisionnement
Ansible est votre fidèle ami lorsque vous souhaitez tout automatiser dans votre système. C'est sans agent et vous pouvez simplement gérer vos choses (c'est-à-dire les serveurs, les équilibreurs de charge, les commutateurs, les pare-feu) via SSH. Que vos systèmes fonctionnent sur des serveurs bare metal ou cloud, Ansible sera là pour vous aider à provisionner vos instances. Ses caractéristiques idempotentes garantissent que vous serez toujours dans l'état que vous avez souhaité (et attendu).
Gestion des configurations
L'une des choses les plus difficiles est de ne pas se répéter dans des tâches opérationnelles répétitives et ici Ansible revient à l'esprit comme un sauveur. Au bon vieux temps, quand les temps étaient durs, les administrateurs système écrivaient de nombreux scripts et se connectaient à de nombreux serveurs pour les appliquer et ce n'était évidemment pas la meilleure chose de leur vie. Comme nous le savons tous, les tâches manuelles sont sujettes aux erreurs et conduisent à un environnement hétérogène au lieu d'un environnement homogène et plus gérable, ce qui rend notre vie plus stressante.
Avec Ansible, vous pouvez écrire des playbooks simples (avec l'aide d'une documentation très informative et le soutien de son immense communauté) et une fois que vous écrivez vos tâches, vous pouvez appeler un large éventail de modules (c'est-à-dire AWS, Nagios, PostgreSQL, SSH, APT, File modules). Par conséquent, vous pouvez vous concentrer sur des activités plus créatives que sur la gestion manuelle des configurations.
Déploiement d'applications
Une fois les artefacts prêts, il est très facile de les déployer sur plusieurs serveurs. Étant donné qu'Ansible communique via SSH, il n'est pas nécessaire d'extraire d'un référentiel sur chaque serveur ou de se soucier d'anciennes méthodes telles que la copie de fichiers via FTP. Ansible peut synchroniser les artefacts et garantir que seuls les fichiers nouveaux ou mis à jour sont transférés et que les fichiers obsolètes sont supprimés. Cela accélère également les transferts de fichiers et économise beaucoup de bande passante.
Outre le transfert de fichiers, Ansible aide également à préparer les serveurs pour une utilisation en production. Avant le transfert, il peut suspendre la surveillance, supprimer les serveurs des équilibreurs de charge et arrêter les services. Après le déploiement, il peut démarrer des services, ajouter des serveurs aux équilibreurs de charge et reprendre la surveillance.
Tout cela ne doit pas nécessairement se produire en même temps pour tous les serveurs. Ansible peut fonctionner sur un sous-ensemble de serveurs à la fois pour fournir des déploiements sans temps d'arrêt. Par exemple, en une seule fois, il peut déployer 5 serveurs à la fois, puis il peut se déployer sur les 5 serveurs suivants lorsqu'ils ont terminé.
Après avoir implémenté ce scénario, il peut être exécuté n'importe où. Les développeurs ou les membres de l'équipe QA peuvent effectuer des déploiements sur leurs propres machines à des fins de test. De plus, pour annuler un déploiement pour quelque raison que ce soit, tout ce dont Ansible a besoin est l'emplacement des derniers artefacts de travail connus. Il peut ensuite facilement les redéployer sur des serveurs de production pour remettre le système dans un état stable.
Livraison continue
La livraison continue signifie adopter une approche simple et rapide pour les versions. Pour atteindre cet objectif, il est crucial d'utiliser les meilleurs outils qui permettent des versions fréquentes sans temps d'arrêt et nécessitent le moins d'intervention humaine possible. Depuis que nous avons appris les capacités de déploiement d'applications d'Ansible ci-dessus, il est assez facile d'effectuer des déploiements sans temps d'arrêt. L'autre exigence pour une livraison continue est moins de processus manuels et cela signifie l'automatisation. Ansible peut automatiser n'importe quelle tâche, du provisionnement des serveurs à la configuration des services pour qu'ils soient prêts pour la production. Après avoir créé et testé des scénarios dans Ansible, il devient trivial de les placer devant un système d'intégration continue et de laisser Ansible faire son travail.
Sécurité et conformité
La sécurité est toujours considérée comme la chose la plus importante, mais la sécurisation des systèmes est l'une des choses les plus difficiles à réaliser. Vous devez être sûr de la sécurité de vos données ainsi que de la sécurité des données de vos clients. Pour être sûr de la sécurité de vos systèmes, définir la sécurité ne suffit pas, vous devez être en mesure d'appliquer cette sécurité et de surveiller en permanence vos systèmes pour vous assurer qu'ils restent conformes à cette sécurité.
Ansible est facile à utiliser, qu'il s'agisse de configurer des règles de pare-feu, de verrouiller des utilisateurs et des groupes ou d'appliquer des politiques de sécurité personnalisées. Il est sûr par nature puisque vous pouvez appliquer à plusieurs reprises la même configuration, et il n'apportera que les modifications nécessaires pour remettre le système en conformité.
Orchestration
Ansible s'assure que toutes les tâches données sont dans le bon ordre et établit une harmonie entre toutes les ressources qu'il gère. L'orchestration de déploiements complexes à plusieurs niveaux est plus facile grâce aux capacités de gestion de la configuration et de déploiement d'Ansible. Par exemple, si l'on considère le déploiement d'une pile logicielle, les préoccupations telles que s'assurer que tous les serveurs de base de données sont prêts avant d'activer les serveurs d'application ou configurer le réseau avant d'ajouter des serveurs à l'équilibreur de charge ne sont plus des problèmes compliqués.
Ansible aide également à l'orchestration d'autres outils d'orchestration tels que CloudFormation d'Amazon, OpenStack's Heat, Docker's Swarm, etc. De cette façon, au lieu d'apprendre différentes plateformes, langages et règles; les utilisateurs ne peuvent se concentrer que sur la syntaxe YAML et les modules puissants d'Ansible.
Qu'est-ce qu'un module Ansible ?
Les modules ou bibliothèques de modules fournissent à Ansible des moyens de contrôler ou de gérer des ressources sur des serveurs locaux ou distants. Ils remplissent diverses fonctions. Par exemple, un module peut être responsable du redémarrage d'une machine ou il peut simplement afficher un message à l'écran.
Ansible permet aux utilisateurs d'écrire leurs propres modules et fournit également des modules de base ou des modules supplémentaires prêts à l'emploi.
Qu'en est-il des playbooks Ansible ?
Ansible nous permet d'organiser notre travail de différentes manières. Dans sa forme la plus directe, nous pouvons travailler avec des modules Ansible en utilisant le "ansible ” outil de ligne de commande et le fichier d'inventaire.
Inventaire
L'un des concepts les plus importants est l'inventaire . Nous avons besoin d'un fichier d'inventaire pour permettre à Ansible de savoir quels serveurs il doit se connecter en utilisant SSH, quelles informations de connexion il a besoin et éventuellement quelles variables sont associées à ces serveurs.
Le fichier d'inventaire est dans un format de type INI. Dans le fichier d'inventaire, nous pouvons spécifier plusieurs hôtes et les regrouper sous plusieurs groupes d'hôtes.
Notre exemple de fichier d'inventaire hosts.ini ressemble à ceci :
[dbservers]
db.example.com
Ici, nous avons un seul hôte appelé "db.example.com" dans un groupe d'hôtes appelé "dbservers". Dans le fichier d'inventaire, nous pouvons également inclure des ports SSH personnalisés, des noms d'utilisateur SSH, des clés SSH, des informations de proxy, des variables, etc.
Puisque nous avons un fichier d'inventaire prêt, afin de voir les temps de disponibilité de nos serveurs de base de données, nous pouvons invoquer la "commande d'Ansible » et exécutez le module « uptime ” commande sur ces serveurs :
ansible dbservers -i hosts.ini -m command -a "uptime"
Ici, nous avons demandé à Ansible de lire les hôtes à partir du fichier hosts.ini, de les connecter à l'aide de SSH, d'exécuter le "uptime ” sur chacun d'eux, puis imprimez leur sortie à l'écran. Ce type d'exécution de module est appelé une commande ad-hoc .
La sortie de la commande ressemblera à :
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
Cependant, si notre solution contient plus d'une étape, il devient difficile de les gérer uniquement en utilisant des commandes ad-hoc.
Voici les playbooks Ansible. Il nous permet d'organiser notre solution dans un fichier playbook en intégrant toutes les étapes au moyen de tâches, de variables, de rôles, de modèles, de gestionnaires et d'un inventaire.
Examinons brièvement certains de ces termes pour comprendre comment ils peuvent nous aider.
Tâches
Un autre concept important est celui des tâches. Chaque tâche Ansible contient un nom, un module à appeler, des paramètres de module et éventuellement des pré/post-conditions. Ils nous permettent d'appeler des modules Ansible et de transmettre des informations à des tâches consécutives.
Variables
Il y a aussi des variables. Ils sont très utiles pour réutiliser les informations que nous avons fournies ou recueillies. Nous pouvons soit les définir dans l'inventaire, dans des fichiers YAML externes ou dans des playbooks.
Livre de jeu
Les playbooks Ansible sont écrits à l'aide de la syntaxe YAML. Il peut contenir plus d'une pièce. Chaque jeu contient le nom des groupes hôtes auxquels se connecter et les tâches qu'il doit effectuer. Il peut également contenir des variables/rôles/gestionnaires, s'ils sont définis.
Nous pouvons maintenant examiner un playbook très simple pour voir comment il peut être structuré :
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeDans ce playbook très simple, nous avons indiqué à Ansible qu'il devait fonctionner sur des serveurs définis dans le groupe d'hôtes "dbservers". Nous avons créé une variable appelée "qui" puis nous avons défini nos tâches. Notez que dans la première tâche où nous imprimons un message de débogage, nous avons utilisé la variable "who" et avons amené Ansible à imprimer "Hello World" à l'écran. Dans la deuxième tâche, nous avons demandé à Ansible de se connecter à chaque hôte, puis d'y exécuter la commande "uptime".
Modules PostgreSQL Ansibles
Ansible fournit un certain nombre de modules pour PostgreSQL. Certains d'entre eux se trouvent sous les modules de base tandis que d'autres se trouvent sous les modules supplémentaires.
Tous les modules PostgreSQL nécessitent que le package Python psycopg2 soit installé sur la même machine que le serveur PostgreSQL. Psycopg2 est un adaptateur de base de données PostgreSQL en langage de programmation Python.
Sur les systèmes Debian/Ubuntu, le package psycopg2 peut être installé à l'aide de la commande suivante :
apt-get install python-psycopg2
Nous allons maintenant examiner ces modules en détail. À titre d'exemple, nous travaillerons sur un serveur PostgreSQL sur l'hôte db.example.com sur le port 5432 avec postgres utilisateur et un mot de passe vide.
postgresql_db
Ce module principal crée ou supprime une base de données PostgreSQL donnée. Dans la terminologie Ansible, il garantit qu'une base de données PostgreSQL donnée est présente ou absente.
L'option la plus importante est le paramètre obligatoire "nom ”. Il représente le nom de la base de données dans un serveur PostgreSQL. Un autre paramètre significatif est "état ”. Il nécessite l'une des deux valeurs :présent ou absent . Cela nous permet de créer ou de supprimer une base de données identifiée par la valeur donnée dans le nom paramètre.
Certains flux de travail peuvent également nécessiter la spécification de paramètres de connexion tels que login_host , port , login_user , et login_password .
Créons une base de données appelée "module_test " sur notre serveur PostgreSQL en ajoutant les lignes ci-dessous à notre fichier playbook :
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Ici, nous nous sommes connectés à notre serveur de base de données de test sur db.example.com avec l'utilisateur ; postgres . Cependant, il n'est pas nécessaire que ce soit le postgres user comme nom d'utilisateur peut être n'importe quoi.
Supprimer la base de données est aussi simple que de la créer :
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Notez la valeur "absent" dans le paramètre "état".
postgresql_ext
PostgreSQL est connu pour avoir des extensions très utiles et puissantes. Par exemple, une extension récente est tsm_system_rows ce qui aide à récupérer le nombre exact de lignes dans tablesampling. (Pour plus d'informations, vous pouvez consulter mon article précédent sur les méthodes d'échantillonnage des tables.)
Ce module supplémentaire ajoute ou supprime des extensions PostgreSQL d'une base de données. Il nécessite deux paramètres obligatoires :db et nom . La db le paramètre fait référence au nom de la base de données et au nom Le paramètre fait référence au nom de l'extension. Nous avons aussi l'état paramètre qui doit être présent ou absent valeurs, et les mêmes paramètres de connexion que dans le module postgresql_db.
Commençons par créer l'extension dont nous avons parlé :
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
postgresql_user
Ce module de base permet d'ajouter ou de supprimer des utilisateurs et des rôles d'une base de données PostgreSQL.
C'est un module très puissant car tout en assurant la présence d'un utilisateur sur la base de données, il permet également la modification de privilèges ou de rôles en même temps.
Commençons par regarder les paramètres. Le seul paramètre obligatoire ici est "nom ”, qui fait référence à un utilisateur ou à un nom de rôle. De plus, comme dans la plupart des modules Ansible, le "state ” paramètre est important. Il peut avoir l'un des présents ou absent valeurs et sa valeur par défaut est présente .
En plus des paramètres de connexion comme dans les modules précédents, certains autres paramètres facultatifs importants sont :
- db :Nom de la base de données où les permissions seront accordées
- mot de passe :Mot de passe de l'utilisateur
- privé :Privilèges au format « priv1/priv2 » ou privilèges de table au format « table:priv1,priv2,… »
- role_attr_flags :attributs de rôle. Les valeurs possibles sont :
- [AUCUN]SUPERUTILISATEUR
- [NON]CRÉATÉROLE
- [NO]CREATEUSER
- [NO]CREATEDB
- [NON]HÉRITER
- [PAS]CONNEXION
- [PAS] DE RÉPLICATION
Afin de créer un nouvel utilisateur appelé ada avec le mot de passe lovelace et un privilège de connexion à la base de données module_test , nous pouvons ajouter ce qui suit à notre playbook :
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Maintenant que l'utilisateur est prêt, nous pouvons lui attribuer certains rôles. Pour autoriser « ada » à se connecter et à créer des bases de données :
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
Nous pouvons également accorder des privilèges globaux ou basés sur des tables tels que "INSERT ”, “MISE À JOUR ”, “SÉLECTIONNER », et « SUPPRIMER ” en utilisant le priv paramètre. Un point important à considérer est qu'un utilisateur ne peut pas être supprimé tant que tous les privilèges accordés n'ont pas été révoqués.
postgresql_privs
Ce module principal accorde ou révoque des privilèges sur les objets de la base de données PostgreSQL. Les objets pris en charge sont :table , séquence , fonction , base de données , schéma , langue , tablespace , et groupe .
Les paramètres requis sont "base de données"; nom de la base de données sur laquelle accorder/révoquer des privilèges et "rôles"; une liste de noms de rôles séparés par des virgules.
Les paramètres facultatifs les plus importants sont :
- taper :Type d'objet sur lequel définir des privilèges. Peut être l'un des éléments suivants :table, séquence, fonction, base de données, schéma, langue, tablespace, groupe . La valeur par défaut est table .
- objs :Objets de base de données sur lesquels définir des privilèges. Peut avoir plusieurs valeurs. Dans ce cas, les objets sont séparés par une virgule.
- privés :liste de privilèges séparés par des virgules à accorder ou à révoquer. Les valeurs possibles incluent :ALL , SÉLECTIONNER , MISE À JOUR , INSÉRER .
Voyons comment cela fonctionne en accordant tous les privilèges sur le "public ” schéma en “ada ” :
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
L'une des fonctionnalités très puissantes de PostgreSQL est sa prise en charge de pratiquement tous les langages à utiliser comme langage procédural. Ce module supplémentaire ajoute, supprime ou modifie les langages procéduraux avec une base de données PostgreSQL.
Le seul paramètre obligatoire est "lang ”; nom du langage procédural à ajouter ou supprimer. Les autres options importantes sont "db ”; nom de la base de données dans laquelle la langue est ajoutée ou supprimée, et "confiance ”; option pour rendre la langue fiable ou non pour la base de données sélectionnée.
Activons le langage PL/Python pour notre base de données :
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Tout mettre ensemble
Maintenant que nous savons comment un playbook Ansible est structuré et quels modules PostgreSQL sont disponibles pour nous, nous pouvons maintenant combiner nos connaissances dans un playbook Ansible.
La forme finale de notre playbook main.yml ressemble à ceci :
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Nous pouvons maintenant exécuter notre playbook à l'aide de la commande "ansible-playbook" :
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Vous pouvez trouver l'inventaire et le fichier de playbook dans mon référentiel GitHub créé pour cet article de blog. Il existe également un autre playbook appelé "remove.yml" qui annule tout ce que nous avons fait dans le playbook principal.
Pour plus d'informations sur Ansible :
- Consultez leurs documents bien rédigés.
- Regardez la vidéo de démarrage rapide d'Ansible qui est un tutoriel très utile.
- Suivez leur programme de webinaires, il y a quelques webinaires intéressants à venir sur la liste.