PostgreSQL a également introduit de nombreuses autres fonctionnalités révolutionnaires dans les versions 10 à 11, 12 et 13 qui en font un véritable concurrent d'Oracle, telles que les améliorations de partitionnement, les requêtes parallèles et la réplication logique. Dans cet article de blog, nous présenterons certaines des nouvelles fonctionnalités notables de PostgreSQL incluses dans les versions plus récentes de PostgreSQL.
Fonctionnalités de partitionnement
Partitionnement déclaratif
Jusqu'à la version 9.4 de PostgreSQL, il n'y avait pas de partitionnement réel dans PostgreSQL. Cela n'a été réalisé que par l'héritage de table, qui offrait des fonctionnalités et des performances très limitées. Une grande partie de la fonctionnalité est gérée manuellement via des déclencheurs ou des commandes SQL. Par exemple, nous avons dû utiliser des déclencheurs pour diriger une ligne avant INSERT vers la bonne partition. Nous devons créer des index pour chaque partition séparément. PostgreSQL version 10 a donné naissance au partitionnement déclaratif, mais nous avons tout de même dû créer des contraintes et des index pour chaque partition.
PostgreSQL 11 est livré avec un ensemble très impressionnant de nouvelles fonctionnalités de partitionnement pour aider à la fois à améliorer les performances et à rendre les tables partitionnées plus transparentes pour les applications.
Réplication logique des tables partitionnées
Avec PostgreSQL 13, ils ont introduit la prise en charge de la réplication logique des tables partitionnées. Auparavant, vous étiez obligé de répliquer individuellement les partitions sur vos disques de secours. Maintenant, cependant, vous pouvez répliquer automatiquement toutes vos partitions en même temps
Méthodes de partitionnement
Les méthodes de partitionnement actuellement prises en charge sont la plage, la liste et le hachage.
Clés et index
La prise en charge complète des clés étrangères sur les tables partitionnées a été ajoutée dans PostgreSQL 12. PostgreSQL prend également en charge les clés primaires, les index et les déclencheurs sur les tables partitionnées.
Partition par défaut
PostgreSQL permet la création d'une partition « par défaut » pour stocker les données qui ne correspondent à aucune des partitions restantes. Les utilisateurs d'Oracle vont adorer cette fonctionnalité car elle n'est pas disponible dans Oracle Database.
Mouvement de ligne
Les instructions UPDATE qui modifient une colonne de clé de partition entraînent désormais le déplacement des lignes affectées vers les partitions appropriées.
Élagage des partitions
Améliorez les performances de SELECT grâce à des stratégies d'élimination de partition améliorées lors de la planification et de l'exécution des requêtes. Une nouvelle méthode d'élimination des partitions a été ajoutée. Ce nouvel algorithme est capable de déterminer les partitions correspondantes en examinant la clause WHERE de la requête. L'algorithme précédent vérifiait tour à tour chaque partition pour voir si elle pouvait correspondre à la clause WHERE de la requête. Cela a entraîné une augmentation supplémentaire du temps de planification à mesure que le nombre de partitions augmentait.
Élagage des partitions pendant l'exécution de la requête
Comme pour les instructions préparées, les paramètres de la requête ne sont pas connus avant l'exécution. Query Planner ne peut pas éliminer les partitions pendant la phase de planification car les paramètres ne sont pas connus. Ainsi, l'exécuteur effectue l'élagage des partitions pendant l'exécution pour accéder uniquement aux partitions qui correspondent aux paramètres.
Nouvelles fonctionnalités évolutives de PostgreSQL Enterprise avec les versions récentesCliquez pour tweeterFonctionnalités d'indexation
Indice de couverture
PostgreSQL vous permet désormais d'ajouter des colonnes non clés dans l'index btree. Étant donné que les requêtes doivent généralement récupérer plus de colonnes que celles sur lesquelles elles recherchent, PostgreSQL vous permet de créer un index dans lequel certaines colonnes ne sont que des "charges utiles" et ne font pas partie de la clé de recherche. Cela aide à effectuer uniquement des analyses d'index uniquement pour récupérer les lignes requises.
Réindexer simultanément
À partir de PostgreSQL 12, il est possible de reconstruire un index avec REINDEX CONCURRENTLY sans verrouiller la table en lecture/écriture, tout comme la commande Oracle REBUILD INDEX.
Création d'un index parallèle
Avec la création d'index parallèles (introduite dans PostgreSQL 11, actuellement applicable uniquement pour les index b-tree), les index peuvent être créés plus rapidement jusqu'à la valeur max_parallel_workers et en définissant maintenance_work_mem suffisamment grand pour contenir plusieurs copies de données. La création d'index parallèles peut réduire considérablement votre temps de création d'index.
Déduplication des données dans les index B-Tree
Parfois, il y aura des entrées en double dans un index. Cela signifie qu'un nœud feuille dans un index B-Tree avec au moins deux entrées d'index dans le même index contient les mêmes données pour toutes les colonnes d'index. Avec l'ajout de la déduplication dans PostgreSQL 13, vous pouvez regrouper ces entrées d'index B-Tree en double et les rassembler dans une entrée de groupe. L'avantage est d'économiser de l'espace et de réduire la charge sur le disque et la RAM, car vous n'aurez pas à dupliquer les données de colonne. Les entrées en double provoquent également un gonflement indésirable de l'index.
Authentification
SCRAM-SHA-256
Dans PostgreSQL 11, l'authentification par mot de passe SCRAM-SHA-256 est prise en charge. Cette méthode empêche le reniflage de mot de passe sur les connexions non approuvées et vous permet de stocker vos mots de passe sous une forme hachée de manière cryptographique.
De toutes les méthodes d'authentification par mot de passe actuellement prises en charge, c'est la plus sécurisée.
GSSAPI
GSSAPI permet une authentification sécurisée, ainsi qu'une authentification unique automatique pour les systèmes qui la prennent en charge. Cette méthode d'authentification s'appuie sur une bibliothèque de sécurité compatible GSSAPI. Les données envoyées via la connexion à la base de données ne seront pas chiffrées à moins que SSL ne soit utilisé ; cependant l'authentification elle-même est sécurisée. GSSAPI avec authentification Kerberos est possible avec PostgreSQL selon les normes de l'industrie. Lorsque Kerberos est utilisé, un principal standard est utilisé au format « servicename/hostname@realm ». Tout principal inclus dans le keytab utilisé par le serveur sera accepté par le serveur PostgreSQL.
LDAP
Fonctionnant de la même manière que l'authentification par mot de passe, cette méthode d'authentification utilise LDAP comme méthode de vérification. Il n'est utilisé que pour valider les paires nom d'utilisateur et mot de passe, par conséquent, l'utilisateur doit déjà exister dans la base de données pour que l'authentification fonctionne. L'authentification LDAP fonctionne soit en mode de liaison simple, soit en mode de recherche + liaison. Search+bind vous permet d'utiliser d'autres identifiants par rapport au mode de liaison simple, qui ne permet d'utiliser que le nom distinctif, le nom de domaine ou l'e-mail.
Certificat
La méthode d'authentification par certificat utilise des certificats SSL pour s'authentifier. Par conséquent, il n'est disponible que pour les connexions SSL. Avec l'authentification par certificat, aucun mot de passe n'est requis. Le client doit simplement fournir un certificat valide et approuvé pour pouvoir s'authentifier. Le nom commun du certificat sera mis en correspondance avec le nom d'utilisateur de la base de données, et si une correspondance est trouvée, le client sera connecté.
Autres fonctionnalités notables
Aspirateur parallèle
Avec la sortie de PostgreSQL 13, des améliorations de la commande VACUUM ont été implémentées. L'amélioration en question est l'option de paramètre ajoutée PARALLEL. Avec PARALLEL, vous pouvez effectuer des phases de vide d'index et de nettoyage d'index de VACUUM. Cela vous permet de vider en parallèle plusieurs index correspondant à une seule table.
Requête parallèle
La plupart des requêtes de rapports, qui analysent généralement un grand nombre de données, souffrent d'une dégradation des performances en raison de la nécessité d'analyser ou d'agréger les données de plusieurs lignes, même avec une analyse d'index. Ces requêtes ne peuvent utiliser qu'un seul processeur jusqu'à la version 9.4 et s'exécuter en série.
Avec la requête parallèle (qui offre une analyse séquentielle parallèle, une jointure par fusion, une jointure par hachage, un agrégat et d'autres fonctionnalités de plan de requête parallèle), ces requêtes peuvent tirer parti de plusieurs travailleurs et les performances peuvent améliorer de 2x à 10x selon la documentation.
Consultez cet article pour savoir quand utiliser des requêtes parallèles.
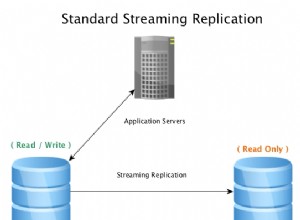
Réplication logique native
PostgreSQL a introduit la réplication logique native dans la version 10 pour fournir une option de réplication plus flexible, contrairement à la réplication en continu et plus comme Oracle Streams, pour répliquer des tables, des colonnes ou des lignes spécifiques. Cela peut être utilisé pour diviser entre plusieurs bases de données ou consolider à partir de plusieurs bases de données. Et peut également répliquer entre différentes versions majeures de PostgreSQL.
Procédures stockées avec transactions intégrées
Encore un autre ajout qui rend PostgreSQL compatible pour les migrations depuis la base de données Oracle.
Nous n'avons aucun contrôle de transaction dans le programme pgsql (bloc ou fonction DO) dans la version 9.4, et devons utiliser une solution de contournement comme dblink pour démarrer et valider/annuler les transactions .
Avec les procédures stockées, qui ont été créées dans la version 11, nous pouvons désormais implémenter le contrôle des transactions dans n'importe quelle structure pgsql, comme une boucle while, une boucle for ou une instruction if else. Bien que les procédures stockées soient similaires aux fonctions, elles doivent être appelées par la commande CALL et peuvent fonctionner comme des programmes indépendants.
Colonnes générées
Comme la base de données Oracle, les colonnes générées dans PostgreSQL peuvent stocker les données automatiquement calculées à partir d'autres colonnes de la ligne. Cela accélère les requêtes en n'ayant pas à calculer la valeur lors de l'exécution de la requête, et à la place, la valeur de la colonne générée est calculée sur INSERT ou UPDATE sur la ligne.
Compilation JIT
PostgreSQL 11, 12 et 13 prennent tous en charge la compilation juste-à-temps (JIT), qui a été ajoutée en 2018. La compilation JIT est le processus de transformation d'une évaluation de programme interprétée en un programme natif. Avec la compilation JIT, ce processus peut être effectué au moment de l'exécution. Un avantage de JIT est la possibilité de générer des fonctions spécifiques à l'expression que le CPU peut exécuter nativement. À son tour, le processus vous donne une accélération.
Sommes de contrôle des pages
Les sommes de contrôle de page sont une fonctionnalité qui vous aide à vérifier l'intégrité des données stockées sur le disque. Auparavant, vous ne pouviez activer les sommes de contrôle de page que lors de l'initialisation d'un cluster PostgreSQL. PostgreSQL 12 a introduit la possibilité d'activer ou de désactiver les sommes de contrôle de page dans un cluster hors ligne via la commande pg_checksums.
Résumé
Comme vous pouvez le voir dans cet article, PostgreSQL est un système de base de données en constante évolution qui apporte de nombreuses fonctionnalités puissantes à la table. Chaque nouvelle version ajoute de nouvelles fonctionnalités intéressantes qui en font un véritable concurrent d'autres bases de données telles qu'Oracle. Ses fonctionnalités de partitionnement et d'indexation reçoivent de nombreuses nouvelles mises à jour qui s'ajoutent à sa boîte à outils déjà étendue.
Si vous recherchez une solution gérée pour votre base de données PostgreSQL, n'hésitez pas à consulter notre service ScaleGrid pour PostgreSQL. Nous fournissons un essai gratuit de 30 jours qui vous permet d'utiliser toutes nos fonctionnalités de gestion sans aucune restriction. Le prix commence à seulement 10 $/mois et vous donne accès à une solution d'hébergement PostgreSQL de niveau entreprise entièrement gérée avec une assistance 24h/24 et 7j/7.