Tout système de base de données moderne prend en charge un module Query Optimizer pour identifier automatiquement la stratégie la plus efficace pour exécuter les requêtes SQL. La stratégie efficace est appelée "Plan" et elle est mesurée en termes de coût qui est directement proportionnel à "Query Execution/Response Time". Le plan est représenté sous la forme d'une sortie arborescente de l'optimiseur de requête. Les nœuds de l'arborescence du plan peuvent être principalement répartis dans les 3 catégories suivantes :
- Analyser les nœuds :Comme expliqué dans mon blog précédent "Un aperçu des différentes méthodes d'analyse dans PostgreSQL", il indique la manière dont les données d'une table de base doivent être récupérées.
- Joindre des nœuds :Comme expliqué dans mon blog précédent "An Overview of the JOIN Methods in PostgreSQL", il indique comment deux tables doivent être jointes pour obtenir le résultat de deux tables.
- Nœuds de matérialisation :également appelés nœuds auxiliaires. Les deux types de nœuds précédents étaient liés à la manière d'extraire des données d'une table de base et à la manière de joindre des données extraites de deux tables. Les nœuds de cette catégorie sont appliqués au-dessus des données récupérées afin d'analyser plus avant ou de préparer un rapport, etc. Tri des données, agrégat de données, etc.
Prenons un exemple de requête simple tel que...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Supposons un plan généré correspondant à la requête ci-dessous :
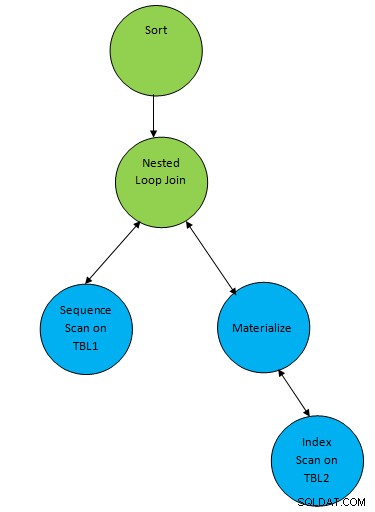
Ainsi, ici, un nœud auxiliaire "Sort" est ajouté au-dessus du résultat de jointure pour trier les données dans l'ordre requis.
Certains des nœuds auxiliaires générés par l'optimiseur de requête PostgreSQL sont les suivants :
- Trier
- Agrégé
- Regrouper par agrégat
- Limite
- Unique
- LockRows
- SetOp
Comprenons chacun de ces nœuds.
Trier
Comme son nom l'indique, ce nœud est ajouté dans le cadre d'un arbre de plan chaque fois qu'il y a un besoin de données triées. Les données triées peuvent être requises explicitement ou implicitement comme ci-dessous dans les deux cas :
Le scénario utilisateur nécessite des données triées en sortie. Dans ce cas, le nœud de tri peut être au-dessus de la récupération de données entières, y compris tous les autres traitements.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Remarque : Même si l'utilisateur a demandé la sortie finale dans l'ordre trié, le nœud de tri peut ne pas être ajouté dans le plan final s'il existe un index sur la table et la colonne de tri correspondantes. Dans ce cas, il peut choisir un balayage d'index qui se traduira par un ordre implicitement trié des données. Par exemple, créons un index sur l'exemple ci-dessus et voyons le résultat :
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Comme expliqué dans mon blog précédent Un aperçu des méthodes JOIN dans PostgreSQL, Merge Join nécessite que les données des deux tables soient triées avant la jointure. Il peut donc arriver que Merge Join soit moins cher que toute autre méthode de jointure, même avec un coût supplémentaire de tri. Ainsi, dans ce cas, le nœud Trier sera ajouté entre la méthode de jointure et la méthode d'analyse de la table afin que les enregistrements triés puissent être transmis à la méthode de jointure.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Agrégat
Le nœud d'agrégation est ajouté dans le cadre d'un arbre de plan s'il existe une fonction d'agrégation utilisée pour calculer des résultats uniques à partir de plusieurs lignes d'entrée. Certaines des fonctions d'agrégation utilisées sont COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) et MIN (MINIMUM).
Un nœud d'agrégation peut venir au-dessus d'un parcours de relation de base ou (et) lors d'une jointure de relations. Exemple :
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Ces types de nœuds sont des extensions du nœud « Aggregate ». Si des fonctions d'agrégation sont utilisées pour combiner plusieurs lignes d'entrée selon leur groupe, ces types de nœuds sont ajoutés à un arbre de plan. Donc, si la requête a une fonction d'agrégation utilisée et qu'il y a une clause GROUP BY dans la requête, alors le nœud HashAggregate ou GroupAggregate sera ajouté à l'arborescence du plan.
Étant donné que PostgreSQL utilise Cost Based Optimizer pour générer un arbre de plan optimal, il est presque impossible de deviner lequel de ces nœuds sera utilisé. Mais comprenons quand et comment il est utilisé.
HashAggregate
HashAggregate fonctionne en construisant la table de hachage des données afin de les regrouper. Ainsi, HashAggregate peut être utilisé par l'agrégat au niveau du groupe si l'agrégat se produit sur un ensemble de données non trié.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Ici, les données du schéma de la table demo1 sont conformes à l'exemple présenté dans la section précédente. Puisqu'il n'y a que 1 000 lignes à regrouper, la ressource requise pour créer une table de hachage est inférieure au coût du tri. Le planificateur de requêtes décide de choisir HashAggregate.
GroupAggregate
GroupAggregate fonctionne sur des données triées et ne nécessite donc aucune structure de données supplémentaire. GroupAggregate peut être utilisé par un agrégat au niveau du groupe si l'agrégation porte sur un ensemble de données triées. Afin de regrouper sur des données triées, il peut soit trier explicitement (en ajoutant un nœud de tri), soit fonctionner sur des données extraites par index, auquel cas elles sont implicitement triées.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Ici, les données du schéma de la table demo2 sont conformes à l'exemple présenté dans la section précédente. Puisqu'il y a ici 100 000 lignes à regrouper, la ressource requise pour créer une table de hachage peut être plus coûteuse que le coût du tri. Le planificateur de requêtes décide donc de choisir GroupAggregate. Observez ici que les enregistrements sélectionnés dans la table "demo2" sont explicitement triés et pour lesquels un nœud est ajouté dans l'arborescence du plan.
Voir ci-dessous un autre exemple, où les données sont déjà récupérées triées en raison de l'analyse de l'index :
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Voir ci-dessous un autre exemple, qui même s'il a Index Scan, doit toujours être trié explicitement car la colonne sur laquelle l'index et la colonne de regroupement ne sont pas les mêmes. Il doit donc toujours trier selon la colonne de regroupement.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Remarque : GroupAggregate/HashAggregate peut être utilisé pour de nombreuses autres requêtes indirectes, même si l'agrégation avec group by n'est pas présente dans la requête. Cela dépend de la façon dont le planificateur interprète la requête. Par exemple. Supposons que nous ayons besoin d'obtenir une valeur distincte de la table, elle peut alors être vue comme un groupe par la colonne correspondante, puis prendre une valeur de chaque groupe.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Ainsi, ici, HashAggregate est utilisé même s'il n'y a pas d'agrégation et de regroupement en cause.
Limite
Les nœuds de limite sont ajoutés à l'arborescence du plan si la clause « limit/offset » est utilisée dans la requête SELECT. Cette clause est utilisée pour limiter le nombre de lignes et éventuellement fournir un décalage pour commencer à lire les données. Exemple ci-dessous :
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Unique
Ce nœud est sélectionné afin d'obtenir une valeur distincte du résultat sous-jacent. Notez qu'en fonction de la requête, de la sélectivité et d'autres informations sur les ressources, la valeur distincte peut être récupérée à l'aide de HashAggregate/GroupAggregate également sans utiliser le nœud Unique. Exemple :
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL fournit une fonctionnalité pour verrouiller toutes les lignes sélectionnées. Les lignes peuvent être sélectionnées en mode "Partagé" ou en mode "Exclusif" selon les clauses "FOR SHARE" et "FOR UPDATE" respectivement. Un nouveau nœud "LockRows" est ajouté à l'arborescence du plan lors de la réalisation de cette opération.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL fournit des fonctionnalités pour combiner les résultats de deux requêtes ou plus. Ainsi, lorsque le type de nœud Join est sélectionné pour joindre deux tables, un type similaire de nœud SetOp est sélectionné pour combiner les résultats de deux requêtes ou plus. Par exemple, considérons un tableau avec des employés avec leur identifiant, leur nom, leur âge et leur salaire comme ci-dessous :
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Prenons maintenant les employés âgés de plus de 25 ans :
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Prenons maintenant les employés avec un salaire supérieur à 95 millions :
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Maintenant, afin d'obtenir des employés âgés de plus de 25 ans et d'un salaire supérieur à 95 millions, nous pouvons écrire la requête d'intersection ci-dessous :
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Ainsi, ici, un nouveau type de nœud HashSetOp est ajouté pour évaluer l'intersection de ces deux requêtes individuelles.
Notez qu'il existe deux autres types de nouveaux nœuds ajoutés ici :
Ajouter
Ce nœud est ajouté pour combiner plusieurs ensembles de résultats en un seul.
Analyse des sous-requêtes
Ce nœud est ajouté pour évaluer toute sous-requête. Dans le plan ci-dessus, la sous-requête est ajoutée pour évaluer une valeur de colonne constante supplémentaire qui indique quel jeu d'entrée a contribué à une ligne spécifique.
HashedSetop fonctionne en utilisant le hachage du résultat sous-jacent mais il est possible de générer une opération SetOp basée sur le tri par l'optimiseur de requête. Le nœud Setop basé sur le tri est désigné par "Setop".
Remarque :Il est possible d'obtenir le même résultat que celui indiqué dans le résultat ci-dessus avec une seule requête, mais ici, il est affiché en utilisant l'intersection juste pour une démonstration facile.
Conclusion
Tous les nœuds de PostgreSQL sont utiles et sont sélectionnés en fonction de la nature de la requête, des données, etc. De nombreuses clauses sont mappées une à une avec des nœuds. Pour certaines clauses, il existe plusieurs options pour les nœuds, qui sont décidées en fonction des calculs du coût des données sous-jacentes.