Ce blog commence une multi-série documentant mon parcours sur l'analyse comparative de PostgreSQL dans le cloud.
La première partie comprend un aperçu des outils d'analyse comparative et lance le plaisir avec Amazon Aurora PostgreSQL.
Sélectionner les fournisseurs de services cloud PostgreSQL
Il y a quelque temps, je suis tombé sur la procédure de référence AWS pour Aurora et j'ai pensé que ce serait vraiment cool si je pouvais passer ce test et l'exécuter sur d'autres fournisseurs d'hébergement cloud. Au crédit d'Amazon, parmi les trois fournisseurs d'informatique utilitaire les plus connus - AWS, Google et Microsoft - AWS est le seul contributeur majeur au développement de PostgreSQL et le premier à proposer un service PostgreSQL géré (remontant à novembre 2013).
Bien que les services PostgreSQL gérés soient également disponibles auprès d'une pléthore de fournisseurs d'hébergement PostgreSQL, je voulais me concentrer sur ces trois fournisseurs de cloud computing car leurs environnements sont ceux où de nombreuses organisations à la recherche des avantages du cloud computing choisissent d'exécuter leurs applications, à condition qu'elles aient le savoir-faire requis sur la gestion de PostgreSQL. Je suis convaincu que dans le paysage informatique actuel, les organisations travaillant avec des charges de travail critiques dans le cloud bénéficieraient grandement des services d'un fournisseur de services PostgreSQL spécialisé, qui peut les aider à naviguer dans le monde complexe de GUCS et des myriades de présentations SlideShare.
Sélectionner le bon outil de référence
L'analyse comparative de PostgreSQL apparaît assez souvent sur la liste de diffusion des performances, et comme souligné d'innombrables fois, les tests ne sont pas destinés à valider une configuration pour une application réelle. Cependant, il est important de sélectionner le bon outil et les bons paramètres de référence pour obtenir des résultats significatifs. Je m'attendrais à ce que chaque fournisseur de cloud fournisse des procédures d'évaluation de leurs services, en particulier lorsque la première expérience cloud ne démarre pas du bon pied. La bonne nouvelle, c'est que deux des trois acteurs de ce test, ont inclus des benchmarks dans leur documentation. Le guide AWS Benchmark Procedure for Aurora est facile à trouver, disponible directement sur la page Amazon Aurora Resources. Google ne fournit pas de guide spécifique à PostgreSQL, cependant, la documentation de Compute Engine contient un guide de test de charge pour SQL Server basé sur HammerDB.
Voici un résumé des outils de référence en fonction de leurs références qui valent la peine d'être examinés :
- Le AWS Benchmark mentionné ci-dessus est basé sur pgbench et sysbench.
- HammerDB, également mentionné précédemment, est abordé dans un article récent sur pgsql-hackers list.
- Tests TPC-C basés sur oltpbench comme évoqué dans cette autre discussion pgsql-hackers.
- benchmarksql est un autre test TPC-C qui a été utilisé pour valider les modifications apportées aux fractionnements de page B-Tree.
- pg_ycsb est le nouveau venu, il améliore pgbench et est déjà utilisé par certains hackers PostgreSQL.
- pgbench-tools, comme son nom l'indique, est basé sur pgbench et bien qu'il n'ait reçu aucune mise à jour depuis 2016, il est le produit de Greg Smith, l'auteur des livres PostgreSQL High Performance.
- join order benchmark est un benchmark qui testera l'optimiseur de requête.
- pgreplay que j'ai découvert en lisant le blog sur l'invite de commande est aussi proche que possible de l'analyse comparative d'un scénario réel.
Un autre point à noter est que PostgreSQL n'est pas encore bien adapté à la norme de référence TPC-H, et comme indiqué ci-dessus, tous les outils (à l'exception de pgreplay) doivent être exécutés en mode TPC-C (pgbench est par défaut).
Pour les besoins de ce blog, j'ai pensé que la procédure AWS Benchmark pour Aurora est un bon début simplement parce qu'elle établit une norme pour les fournisseurs de cloud et est basée sur des outils largement utilisés.
De plus, j'ai utilisé la dernière version de PostgreSQL disponible à l'époque. Lors de la sélection d'un fournisseur de cloud, il est important de tenir compte de la fréquence des mises à niveau, en particulier lorsque des fonctionnalités importantes introduites par les nouvelles versions peuvent affecter les performances (ce qui est le cas pour les versions 10 et 11 versus 9). Au moment d'écrire ces lignes, nous avons :
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS pour PostgreSQL 10.6
- Google Cloud SQL pour PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
... et le gagnant ici est AWS en proposant la version la plus récente (bien que ce ne soit pas la dernière, qui à ce jour est la 11.2).
Configuration de l'environnement d'analyse comparative
J'ai décidé de limiter mes tests à des charges de travail moyennes pour plusieurs raisons :premièrement, les ressources cloud disponibles ne sont pas identiques d'un fournisseur à l'autre. Dans le guide, les spécifications AWS pour l'instance de base de données sont de 64 vCPU / 488 Gio de RAM / 25 Gigabit de réseau, tandis que la RAM maximale de Google pour n'importe quelle taille d'instance (le choix doit être défini sur "personnalisé" dans le calculateur Google) est de 208 Gio, et le Business Critical Gen5 de Microsoft à 32 vCPU est livré avec seulement 163 Gio). Deuxièmement, l'initialisation de pgbench porte la taille de la base de données à 160 Go, ce qui, dans le cas d'une instance avec 488 Go de RAM, est susceptible d'être stocké en mémoire.
De plus, j'ai laissé la configuration de PostgreSQL intacte. La raison de s'en tenir aux valeurs par défaut du fournisseur de cloud est que, prêt à l'emploi, lorsqu'il est stressé par une référence standard, un service géré devrait fonctionner raisonnablement bien. N'oubliez pas que la communauté PostgreSQL exécute des tests pgbench dans le cadre du processus de gestion des versions. De plus, le guide AWS ne mentionne aucune modification de la configuration PostgreSQL par défaut.
Comme expliqué dans le guide, AWS a appliqué deux correctifs à pgbench. Étant donné que le correctif pour le nombre de clients ne s'appliquait pas proprement sur la version 10.6 de PostgreSQL et que je ne voulais pas investir de temps pour le réparer, le nombre de clients était limité à un maximum de 1 000.
Le guide spécifie une exigence pour que l'instance cliente ait activé la mise en réseau améliorée — pour ce type d'instance qui est la valeur par défaut :
[example@sqldat.com ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff
inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cd:eeff:fe40:2be6/64 scope link
valid_lft forever preferred_lft forever
[example@sqldat.com ~]$ ethtool -i eth0
driver: ena
version: 2.0.2g
firmware-version:
bus-info: 0000:00:03.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
>>> aws (master *%) ~ $ aws ec2 describe-instances --instance-ids i-0ee51642334c1ec57 --query "Reservations[].Instances[].EnaSupport"
[
true
]Exécuter le benchmark sur Amazon Aurora PostgreSQL
Au cours de l'exécution proprement dite, j'ai décidé de faire un écart supplémentaire par rapport au guide :au lieu d'exécuter le test pendant 1 heure, fixez la limite de temps à 10 minutes, ce qui est généralement accepté comme une bonne valeur.
Exécuter #1
Spécificités
- Ce test utilise les spécifications AWS pour les tailles d'instance de client et de base de données.
- Machine client :instance EC2 à mémoire optimisée à la demande :
- vCPU :32 (16 cœurs x 2 threads/cœur)
- RAM :244 Gio
- Stockage :EBS optimisé
- Réseau :10 Gigabits
- Cluster de bases de données :db.r4.16xlarge
- processeur virtuel :64
- ECU (capacité du processeur) :195 x [1,0-1,2 GHz] 2007 Opteron / Xeon
- RAM :488 Gio
- Stockage :EBS optimisé (capacité dédiée pour les E/S)
- Réseau :bande passante maximale de 14 000 Mbit/s sur un réseau de 25 Gps
- Machine client :instance EC2 à mémoire optimisée à la demande :
- La configuration de la base de données comprenait une réplique.
- Le stockage de la base de données n'a pas été chiffré.
Exécution des tests et résultats
- Suivez les instructions du guide pour installer pgbench et sysbench.
- Modifiez ~/.bashrc pour définir les variables d'environnement pour la connexion à la base de données et les chemins d'accès requis aux bibliothèques PostgreSQL :
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com export PGUSER=postgres export PGPASSWORD=postgres export PGDATABASE=postgres export PATH=$PATH:/usr/local/pgsql/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Initialisez la base de données :
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.05 s, remaining 457.23 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 631.70 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 688.29 s) ... 999500000 of 1000000000 tuples (99%) done (elapsed 811.41 s, remaining 0.41 s) 999600000 of 1000000000 tuples (99%) done (elapsed 811.50 s, remaining 0.32 s) 999700000 of 1000000000 tuples (99%) done (elapsed 811.58 s, remaining 0.24 s) 999800000 of 1000000000 tuples (99%) done (elapsed 811.65 s, remaining 0.16 s) 999900000 of 1000000000 tuples (99%) done (elapsed 811.73 s, remaining 0.08 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 811.80 s, remaining 0.00 s) vacuum... set primary keys... done. - Vérifiez la taille de la base de données :
postgres=> \l+ postgres List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description ----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | default administrative connection database (1 row) - Utilisez la requête suivante pour vérifier que l'intervalle de temps entre les points de contrôle est défini afin que les points de contrôle soient forcés pendant l'exécution de 10 minutes :
Résultat :SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpoints FROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutes_between_checkpoints -------------------+----------------------------- 50 | 0.977392292333333 (1 row) - Exécutez la charge de travail en lecture/écriture :
Sortie[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048starting vacuum...end. progress: 60.0 s, 35670.3 tps, lat 27.243 ms stddev 10.915 progress: 120.0 s, 36569.5 tps, lat 27.352 ms stddev 11.859 progress: 180.0 s, 35845.2 tps, lat 27.896 ms stddev 12.785 progress: 240.0 s, 36613.7 tps, lat 27.310 ms stddev 11.804 progress: 300.0 s, 37323.4 tps, lat 26.793 ms stddev 11.376 progress: 360.0 s, 36828.8 tps, lat 27.155 ms stddev 11.318 progress: 420.0 s, 36670.7 tps, lat 27.268 ms stddev 12.083 progress: 480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981 progress: 540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341 progress: 600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 22040445 latency average = 27.149 ms latency stddev = 11.617 ms tps = 36710.828624 (including connections establishing) tps = 36811.054851 (excluding connections establishing) - Préparez le test sysbench :
Sortie :sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ --oltp-table-size=450000 \ preparesysbench 0.5: multi-threaded system evaluation benchmark Creating table 'sbtest1'... Inserting 450000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... ... Creating table 'sbtest250'... Inserting 450000 records into 'sbtest250' Creating secondary indexes on 'sbtest250'... - Exécutez le test sysbench :
Sortie :sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ --oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp-sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ runsysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 20443.09, reads: 0.00, writes: 81834.16, response time: 68.24ms (95%), errors: 0.62, reconnects: 0.00 [ 120s] threads: 1000, tps: 20580.68, reads: 0.00, writes: 82324.33, response time: 70.75ms (95%), errors: 0.73, reconnects: 0.00 [ 180s] threads: 1000, tps: 20531.85, reads: 0.00, writes: 82127.21, response time: 70.63ms (95%), errors: 0.73, reconnects: 0.00 [ 240s] threads: 1000, tps: 20212.67, reads: 0.00, writes: 80861.67, response time: 71.99ms (95%), errors: 0.43, reconnects: 0.00 [ 300s] threads: 1000, tps: 19383.90, reads: 0.00, writes: 77537.87, response time: 75.64ms (95%), errors: 0.75, reconnects: 0.00 [ 360s] threads: 1000, tps: 19797.20, reads: 0.00, writes: 79190.78, response time: 75.27ms (95%), errors: 0.68, reconnects: 0.00 [ 420s] threads: 1000, tps: 20304.43, reads: 0.00, writes: 81212.87, response time: 73.82ms (95%), errors: 0.70, reconnects: 0.00 [ 480s] threads: 1000, tps: 20933.80, reads: 0.00, writes: 83737.16, response time: 74.71ms (95%), errors: 0.68, reconnects: 0.00 [ 540s] threads: 1000, tps: 20663.05, reads: 0.00, writes: 82626.42, response time: 73.56ms (95%), errors: 0.75, reconnects: 0.00 [ 600s] threads: 1000, tps: 20746.02, reads: 0.00, writes: 83015.81, response time: 73.58ms (95%), errors: 0.78, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 48868458 other: 24434022 total: 73302480 transactions: 12216804 (20359.59 per sec.) read/write requests: 48868458 (81440.43 per sec.) other operations: 24434022 (40719.87 per sec.) ignored errors: 414 (0.69 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0516s total number of events: 12216804 total time taken by event execution: 599964.4735s response time: min: 6.27ms avg: 49.11ms max: 350.24ms approx. 95 percentile: 72.90ms Threads fairness: events (avg/stddev): 12216.8040/31.27 execution time (avg/stddev): 599.9645/0.01
Métriques collectées
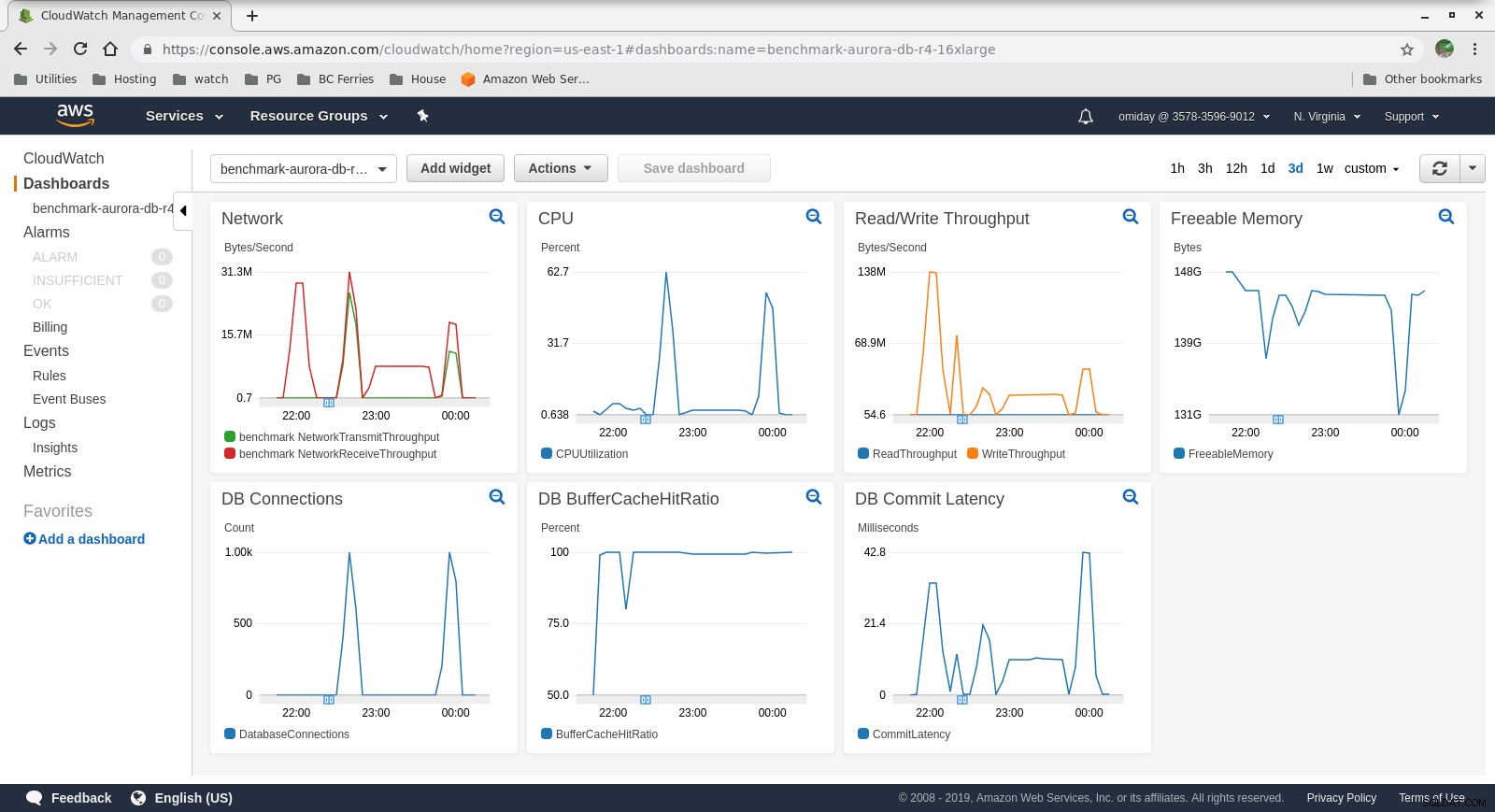 Métriques Cloudwatch
Métriques Cloudwatch 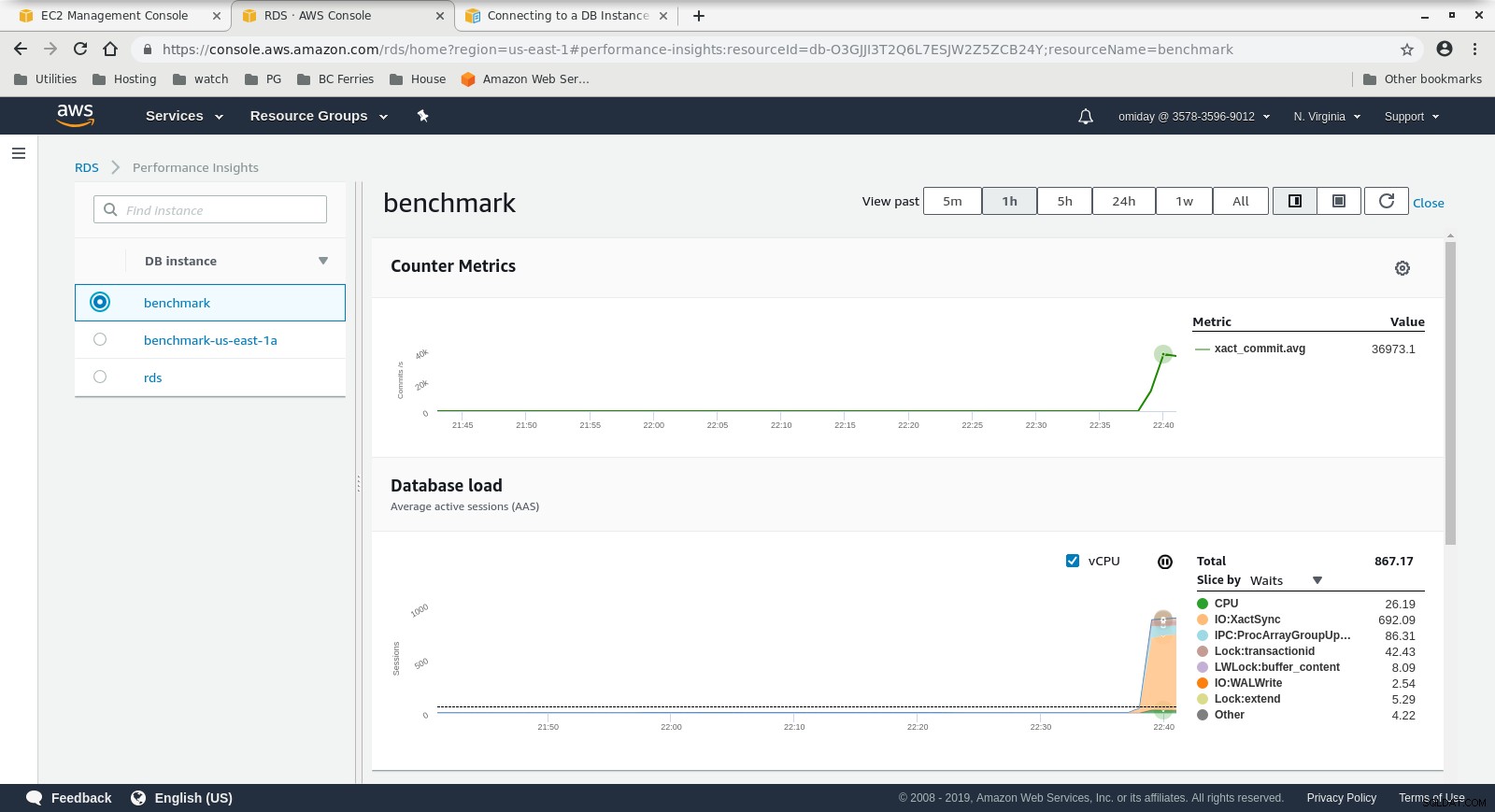 Performance Insights MetricsTéléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blanc
Performance Insights MetricsTéléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blanc Exécuter #2
Spécificités
- Ce test utilise les spécifications AWS pour le client et une taille d'instance plus petite pour la base de données :
- Machine client :instance EC2 à mémoire optimisée à la demande :
- vCPU :32 (16 cœurs x 2 threads/cœur)
- RAM :244 Gio
- Stockage :EBS optimisé
- Réseau :10 Gigabits
- Cluster de bases de données :db.r4.2xlarge :
- processeur virtuel :8
- RAM :61 Gio
- Stockage :EBS optimisé
- Réseau :1 750 Mbit/s de bande passante maximale sur une connexion jusqu'à 10 Gbit/s
- Machine client :instance EC2 à mémoire optimisée à la demande :
- La base de données n'incluait pas de réplica.
- Le stockage de la base de données n'a pas été chiffré.
Exécution des tests et résultats
Les étapes sont identiques à Run #1 donc je ne montre que la sortie :
-
pgbench Charge de travail en lecture/écriture :
... 745700000 of 1000000000 tuples (74%) done (elapsed 794.93 s, remaining 271.09 s) 745800000 of 1000000000 tuples (74%) done (elapsed 795.00 s, remaining 270.97 s) 745900000 of 1000000000 tuples (74%) done (elapsed 795.09 s, remaining 270.86 s) 746000000 of 1000000000 tuples (74%) done (elapsed 795.17 s, remaining 270.74 s) 746100000 of 1000000000 tuples (74%) done (elapsed 795.24 s, remaining 270.62 s) 746200000 of 1000000000 tuples (74%) done (elapsed 795.33 s, remaining 270.51 s) ... 999800000 of 1000000000 tuples (99%) done (elapsed 1067.11 s, remaining 0.21 s) 999900000 of 1000000000 tuples (99%) done (elapsed 1067.19 s, remaining 0.11 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 1067.28 s, remaining 0.00 s) vacuum... set primary keys... total time: 4386.44 s (insert 1067.33 s, commit 0.46 s, vacuum 2088.25 s, index 1230.41 s) done.starting vacuum...end. progress: 60.0 s, 3361.3 tps, lat 286.143 ms stddev 80.417 progress: 120.0 s, 3466.8 tps, lat 288.386 ms stddev 76.373 progress: 180.0 s, 3683.1 tps, lat 271.840 ms stddev 75.712 progress: 240.0 s, 3444.3 tps, lat 289.909 ms stddev 69.564 progress: 300.0 s, 3475.8 tps, lat 287.736 ms stddev 73.712 progress: 360.0 s, 3449.5 tps, lat 289.832 ms stddev 71.878 progress: 420.0 s, 3518.1 tps, lat 284.432 ms stddev 74.276 progress: 480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264 progress: 540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206 progress: 600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 2090702 latency average = 286.030 ms latency stddev = 74.245 ms tps = 3481.731730 (including connections establishing) tps = 3494.157830 (excluding connections establishing) -
test sysbench :
sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 4809.05, reads: 0.00, writes: 19301.02, response time: 288.03ms (95%), errors: 0.05, reconnects: 0.00 [ 120s] threads: 1000, tps: 5264.15, reads: 0.00, writes: 21005.40, response time: 255.23ms (95%), errors: 0.08, reconnects: 0.00 [ 180s] threads: 1000, tps: 5178.27, reads: 0.00, writes: 20713.07, response time: 260.40ms (95%), errors: 0.03, reconnects: 0.00 [ 240s] threads: 1000, tps: 5145.95, reads: 0.00, writes: 20610.08, response time: 255.76ms (95%), errors: 0.05, reconnects: 0.00 [ 300s] threads: 1000, tps: 5127.92, reads: 0.00, writes: 20507.98, response time: 264.24ms (95%), errors: 0.05, reconnects: 0.00 [ 360s] threads: 1000, tps: 5063.83, reads: 0.00, writes: 20278.10, response time: 268.55ms (95%), errors: 0.05, reconnects: 0.00 [ 420s] threads: 1000, tps: 5057.51, reads: 0.00, writes: 20237.28, response time: 269.19ms (95%), errors: 0.10, reconnects: 0.00 [ 480s] threads: 1000, tps: 5036.32, reads: 0.00, writes: 20139.29, response time: 279.62ms (95%), errors: 0.10, reconnects: 0.00 [ 540s] threads: 1000, tps: 5115.25, reads: 0.00, writes: 20459.05, response time: 264.64ms (95%), errors: 0.08, reconnects: 0.00 [ 600s] threads: 1000, tps: 5124.89, reads: 0.00, writes: 20510.07, response time: 265.43ms (95%), errors: 0.10, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 12225686 other: 6112822 total: 18338508 transactions: 3056390 (5093.75 per sec.) read/write requests: 12225686 (20375.20 per sec.) other operations: 6112822 (10187.57 per sec.) ignored errors: 42 (0.07 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0277s total number of events: 3056390 total time taken by event execution: 600005.2104s response time: min: 9.57ms avg: 196.31ms max: 608.70ms approx. 95 percentile: 268.71ms Threads fairness: events (avg/stddev): 3056.3900/67.44 execution time (avg/stddev): 600.0052/0.01
Métriques collectées
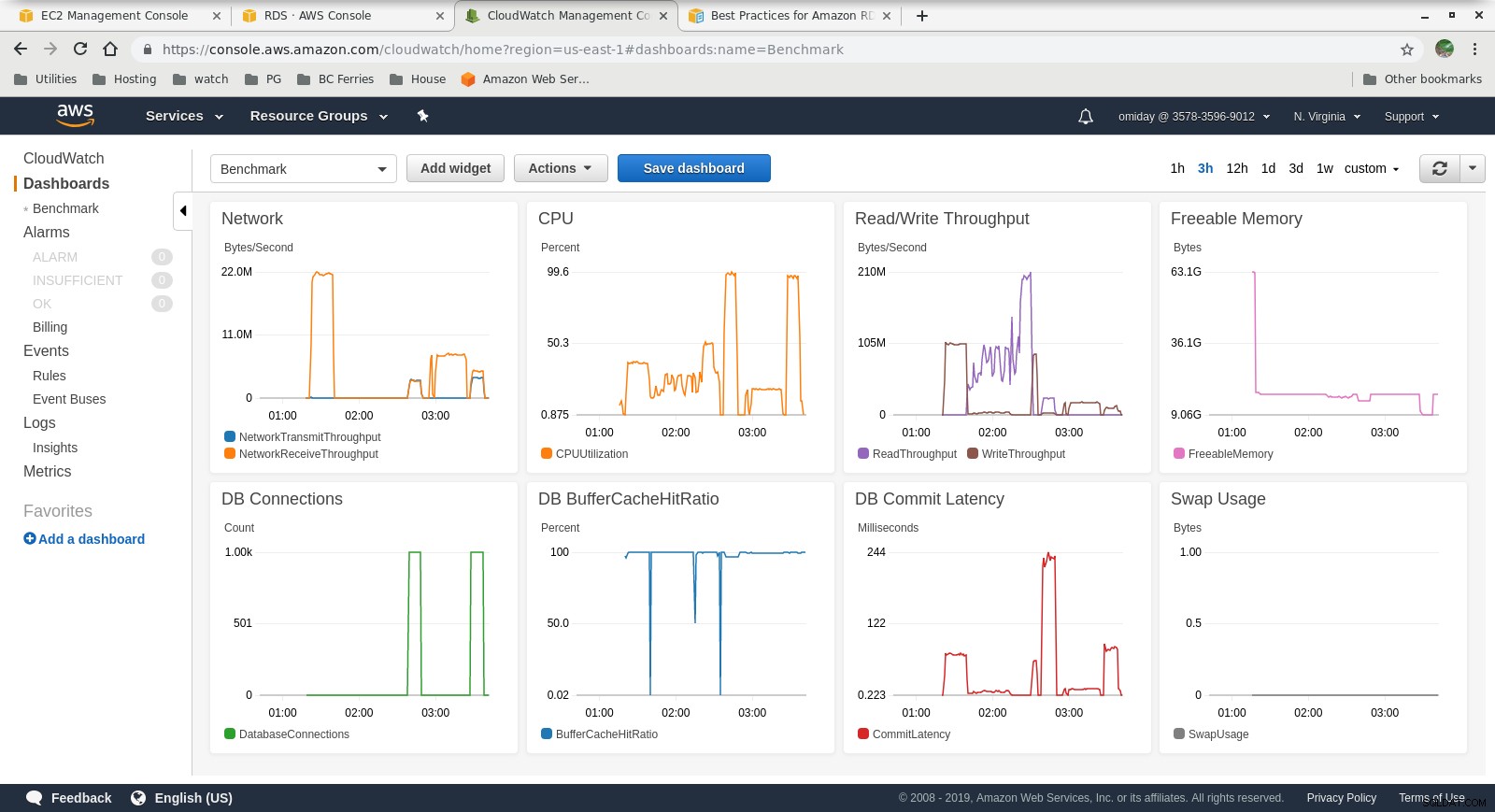 Métriques Cloudwatch
Métriques Cloudwatch 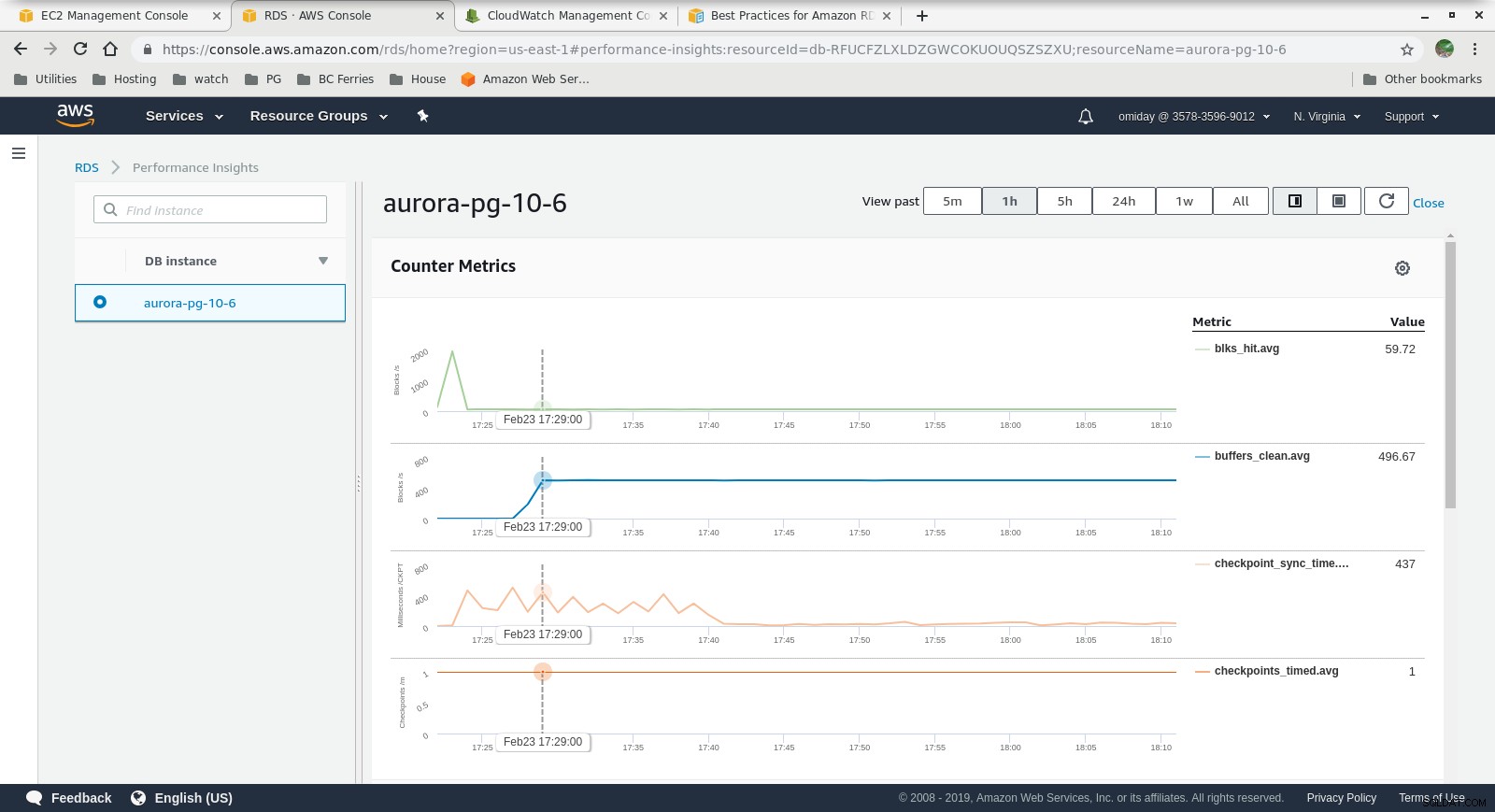 Insights sur les performances - Mesures de compteur
Insights sur les performances - Mesures de compteur 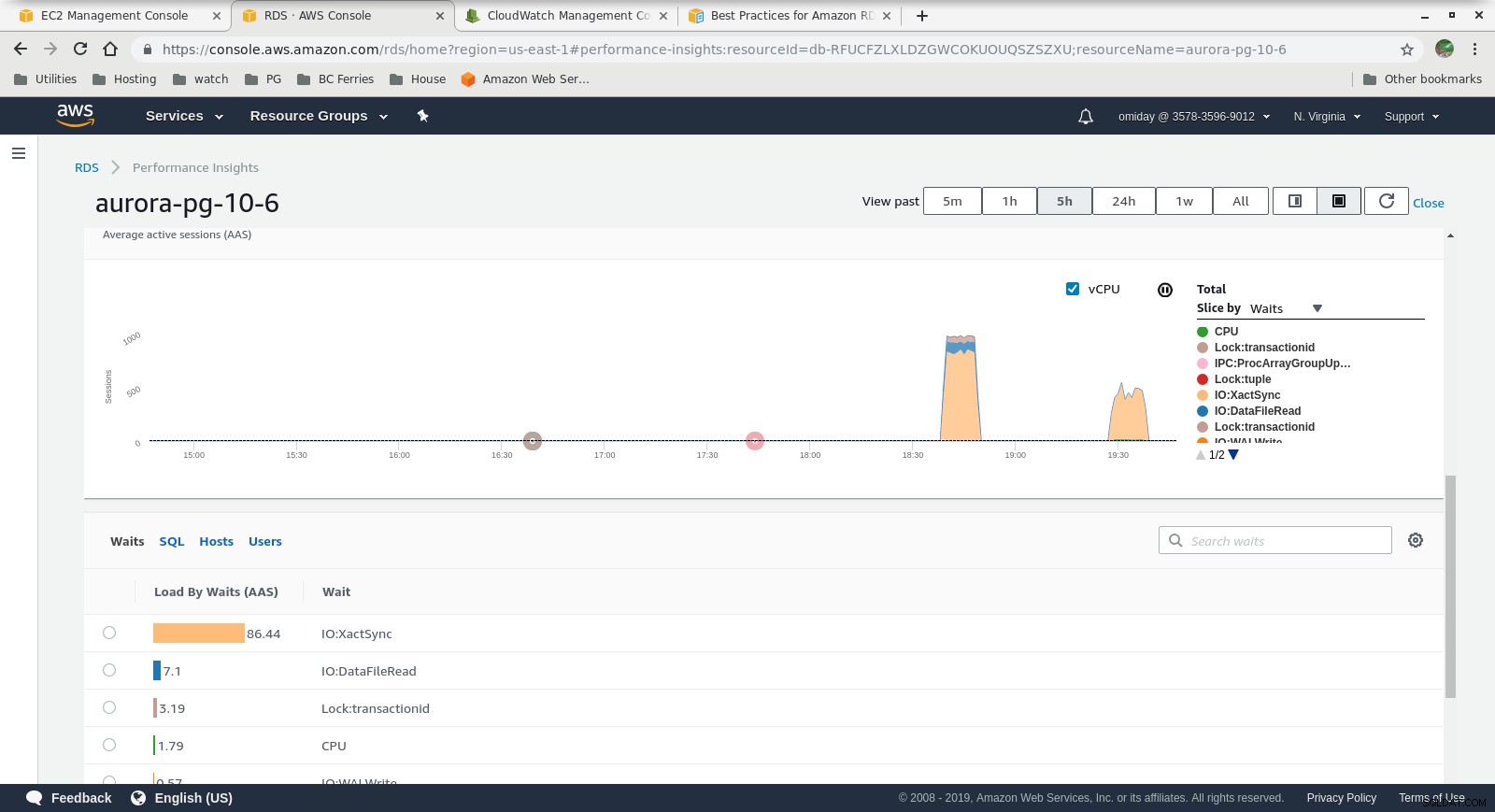 Performance Insights - Chargement de la base de données par attentes
Performance Insights - Chargement de la base de données par attentes Réflexions finales
- Les utilisateurs sont limités à l'utilisation de tailles d'instance prédéfinies. En revanche, si le benchmark montre que l'instance peut bénéficier de mémoire supplémentaire, il n'est pas possible de "simplement ajouter plus de RAM". L'ajout de plus de mémoire se traduit par une augmentation de la taille de l'instance, ce qui entraîne un coût plus élevé (le coût double pour chaque taille d'instance).
- Le moteur de stockage Amazon Aurora est très différent du RDS et repose sur le matériel SAN. Les métriques de débit d'E/S par instance montrent que le test ne s'est pas encore approché du maximum pour les volumes IOPS SSD EBS provisionnés de 1 750 Mio/s.
- Un réglage supplémentaire peut être effectué en examinant les événements AWS PostgreSQL inclus dans les graphiques Performance Insights.
Suivant de la série
Restez à l'écoute pour la partie suivante :Amazon RDS pour PostgreSQL 10.6.