Travaillant dans l'industrie informatique, nous avons probablement entendu le mot « basculement » à plusieurs reprises, mais il peut également soulever des questions telles que :qu'est-ce qu'un basculement ? A quoi peut-on l'utiliser ? Est-ce important de l'avoir ? Comment pouvons-nous faire ?
Bien qu'elles puissent sembler des questions assez basiques, il est important de les prendre en compte dans n'importe quel environnement de base de données. Et le plus souvent, on ne tient pas compte des fondamentaux...
Pour commencer, examinons quelques concepts de base.
Qu'est-ce que le basculement ?
Le basculement est la capacité d'un système à continuer à fonctionner même en cas de défaillance. Cela suggère que les fonctions du système sont assumées par des composants secondaires en cas de défaillance des composants primaires.
Dans le cas de PostgreSQL, il existe différents outils qui permettent d'implémenter un cluster de base de données résistant aux pannes. Un mécanisme de redondance disponible nativement dans PostgreSQL est la réplication. Et la nouveauté de PostgreSQL 10 est l'implémentation de la réplication logique.
Qu'est-ce que la réplication ?
C'est le processus de copie et de mise à jour des données dans un ou plusieurs nœuds de base de données. Il utilise un concept de nœud maître qui reçoit les modifications, et de nœuds esclaves où elles sont répliquées.
Nous avons plusieurs façons de catégoriser la réplication :
- Réplication synchrone :il n'y a pas de perte de données même si notre nœud maître est perdu, mais les validations dans le maître doivent attendre une confirmation de l'esclave, ce qui peut affecter les performances.
- Réplication asynchrone :il existe un risque de perte de données si nous perdons notre nœud maître. Si, pour une raison quelconque, la réplique n'est pas mise à jour au moment de l'incident, les informations qui n'ont pas été copiées peuvent être perdues.
- Réplication physique :les blocs de disque sont copiés.
- Réplication logique :flux des modifications de données.
- Warm Standby Slaves :ils ne prennent pas en charge les connexions.
- Esclaves de redondance d'UC :prennent en charge les connexions en lecture seule, utiles pour les rapports ou les requêtes.
À quoi sert le basculement ?
Il existe plusieurs utilisations possibles du basculement. Voyons quelques exemples.
Migration
Si nous voulons migrer d'un centre de données à un autre en minimisant nos temps d'arrêt, nous pouvons utiliser le basculement.
Supposons que notre maître se trouve dans le centre de données A et que nous souhaitions migrer nos systèmes vers le centre de données B.
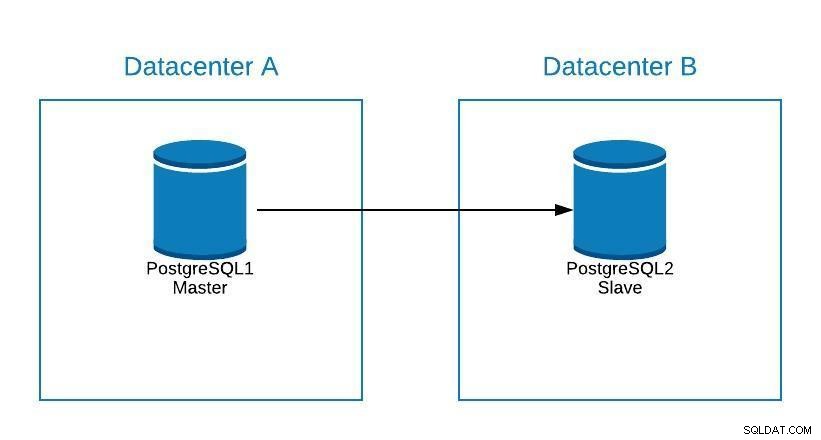 Diagramme de migration 1
Diagramme de migration 1 Nous pouvons créer une réplique dans le centre de données B. Une fois synchronisée, nous devons arrêter notre système, promouvoir notre réplique vers un nouveau maître et basculer, avant de pointer notre système vers le nouveau maître du centre de données B.
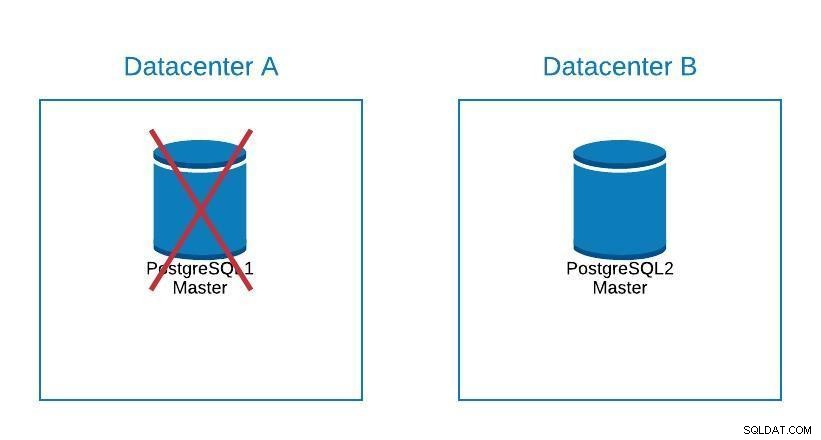 Diagramme de migration 2
Diagramme de migration 2 Le basculement ne concerne pas seulement la base de données, mais également les applications. Comment savent-ils à quelle base de données se connecter ? Nous ne voulons certainement pas avoir à modifier notre application, car cela ne fera que prolonger notre temps d'arrêt. Nous pouvons donc configurer un équilibreur de charge pour que lorsque nous supprimons notre maître, il pointe automatiquement vers le prochain serveur qui est promu.
Une autre option est l'utilisation du DNS. En promouvant le réplica maître dans le nouveau centre de données, nous modifions directement l'adresse IP du nom d'hôte qui pointe vers le maître. De cette façon, nous évitons d'avoir à modifier notre application, et bien que cela ne puisse pas être fait automatiquement, c'est une alternative si nous ne voulons pas implémenter un équilibreur de charge.
Avoir une seule instance d'équilibreur de charge n'est pas génial car cela peut devenir un point de défaillance unique. Par conséquent, vous pouvez également implémenter le basculement pour l'équilibreur de charge, à l'aide d'un service tel que keepalived. De cette façon, si nous avons un problème avec notre équilibreur de charge principal, keepalived se charge de migrer l'IP vers notre équilibreur de charge secondaire, et tout continue à fonctionner de manière transparente.
Entretien
Si nous devons effectuer une maintenance sur notre serveur de base de données maître postgreSQL, nous pouvons promouvoir notre esclave, effectuer la tâche et reconstruire un esclave sur notre ancien maître.
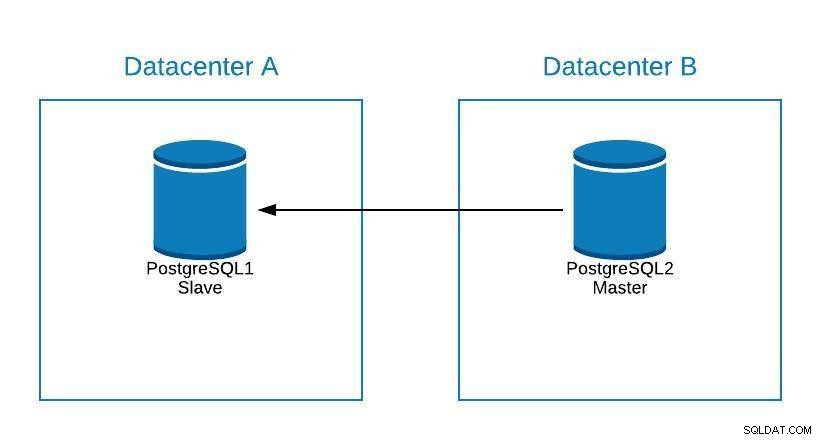 Schéma de maintenance 1
Schéma de maintenance 1 Après cela, nous pouvons re-promouvoir l'ancien maître et répéter le processus de reconstruction de l'esclave, en revenant à l'état initial.
Schéma de maintenance 2 De cette façon, nous pourrions travailler sur notre serveur, sans courir le risque d'être hors ligne ou de perdre des informations lors de la maintenance.
Mettre à jour
Bien que PostgreSQL 11 ne soit pas encore disponible, il serait techniquement possible de mettre à niveau depuis PostgreSQL version 10, en utilisant la réplication logique, comme cela peut être fait avec d'autres moteurs.
Les étapes seraient les mêmes que pour migrer vers un nouveau centre de données (voir la section Migration), sauf que notre esclave serait dans PostgreSQL 11.
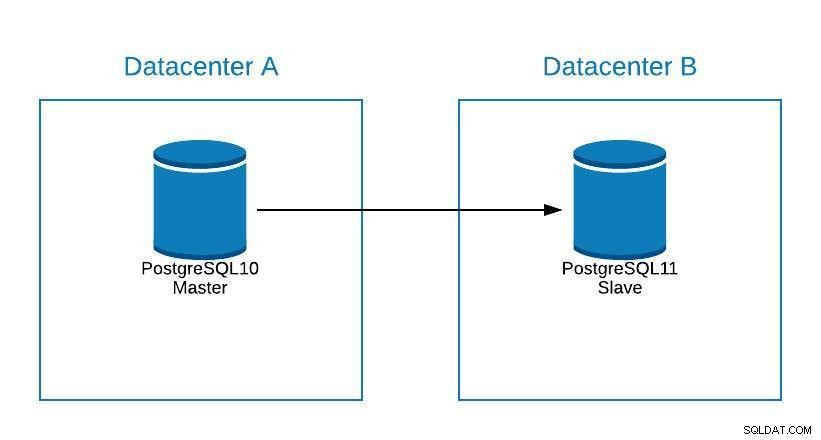 Schéma de mise à niveau 1
Schéma de mise à niveau 1 Problèmes
La fonction la plus importante du basculement est de minimiser nos temps d'arrêt ou d'éviter la perte d'informations en cas de problème avec notre base de données principale.
Si, pour une raison quelconque, nous perdons notre base de données maître, nous pouvons effectuer un basculement en promouvant notre esclave en maître et maintenir nos systèmes en fonctionnement.
Pour ce faire, PostgreSQL ne nous fournit aucune solution automatisée. Nous pouvons le faire manuellement ou l'automatiser au moyen d'un script ou d'un outil externe.
Pour promouvoir notre esclave à maître :
-
Exécutez la promotion pg_ctl
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Créez un fichier trigger_file que nous devons avoir ajouté dans le recovery.conf de notre répertoire de données.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Afin de mettre en œuvre une stratégie de basculement, nous devons la planifier et la tester minutieusement à travers différents scénarios de défaillance. Comme les pannes peuvent se produire de différentes manières, la solution devrait idéalement fonctionner pour la plupart des scénarios courants. Si nous cherchons un moyen d'automatiser cela, nous pouvons jeter un œil à ce que ClusterControl a à offrir.
ClusterControl pour le basculement PostgreSQL
ClusterControl possède un certain nombre de fonctionnalités liées à la réplication PostgreSQL et au basculement automatisé.
Ajouter un esclave
Si nous voulons ajouter un esclave dans un autre centre de données, soit en cas d'urgence, soit pour migrer vos systèmes, nous pouvons accéder à Actions de cluster et sélectionner Ajouter un esclave de réplication.
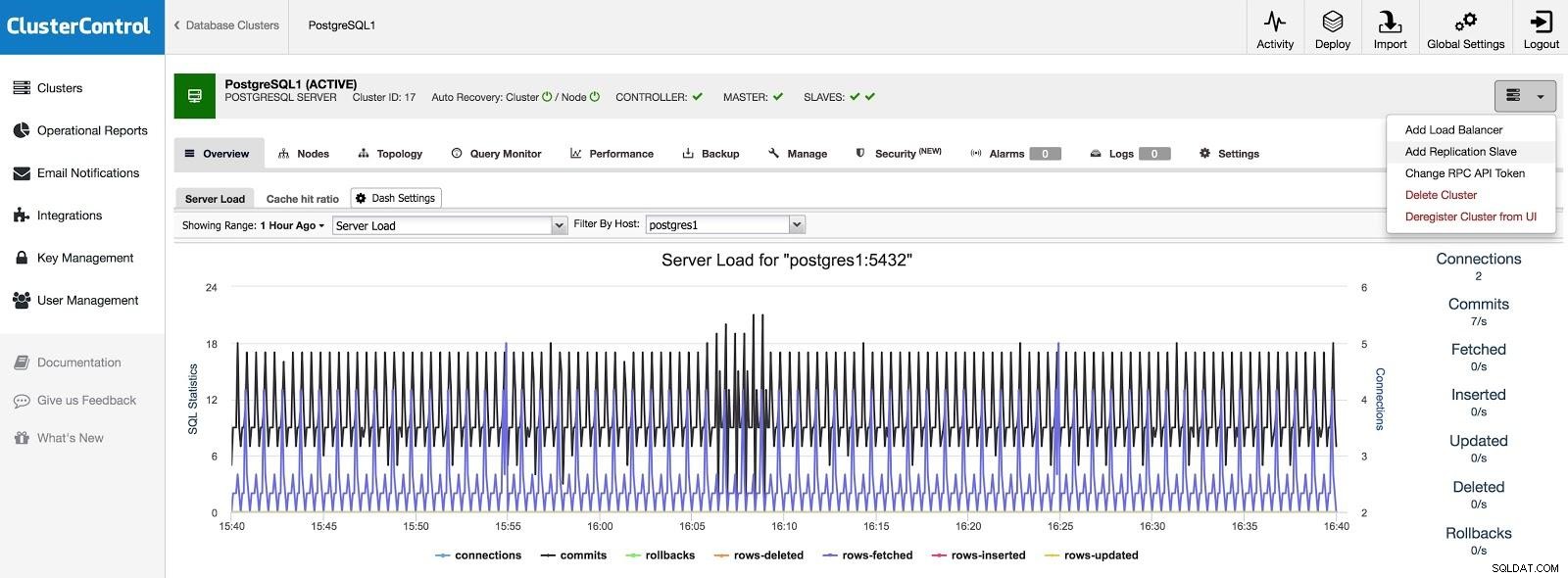 ClusterControl Ajouter un esclave 1
ClusterControl Ajouter un esclave 1 Nous devrons entrer certaines données de base, telles que l'adresse IP ou le nom d'hôte, le répertoire de données (facultatif), l'esclave synchrone ou asynchrone. Nous devrions avoir notre esclave opérationnel après quelques secondes.
Dans le cas de l'utilisation d'un autre centre de données, nous vous recommandons de créer un esclave asynchrone, car sinon la latence peut affecter considérablement les performances.
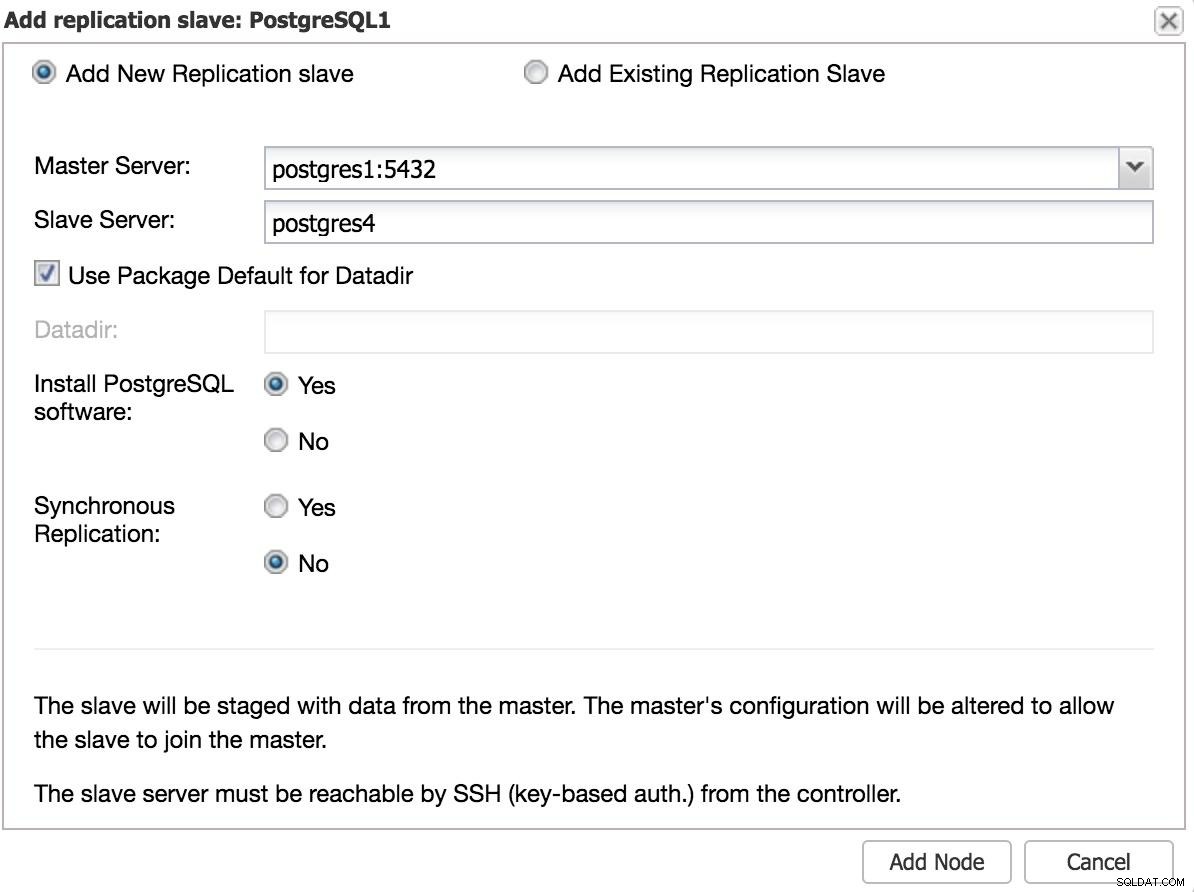 ClusterControl Ajouter un esclave 2
ClusterControl Ajouter un esclave 2 Basculement manuel
Avec ClusterControl, le basculement peut être effectué manuellement ou automatiquement.
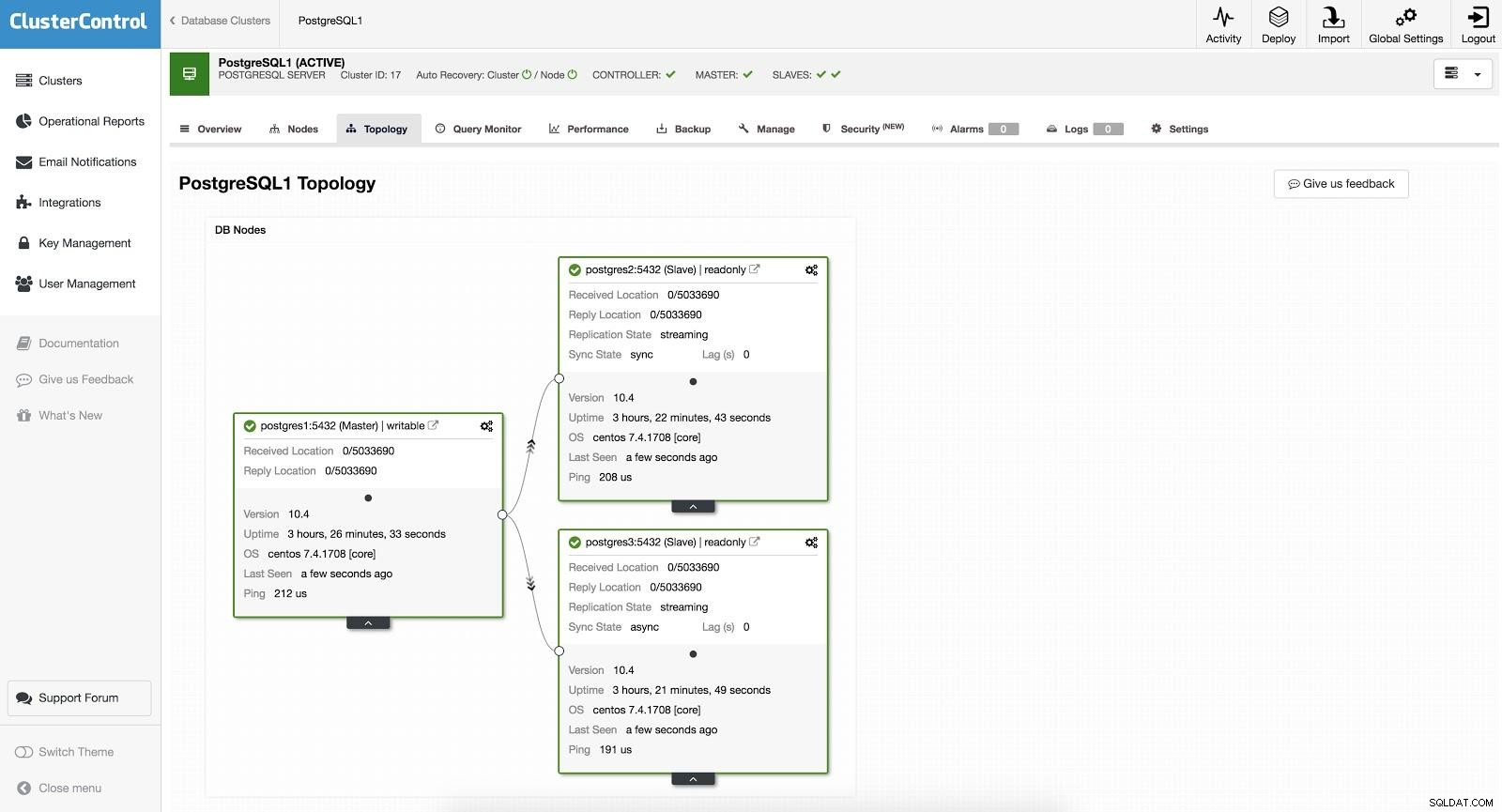 ClusterControl Failover 1
ClusterControl Failover 1 Pour effectuer un basculement manuel, allez dans ClusterControl -> Select Cluster -> Nodes, et dans le Node d'action d'un de nos esclaves, sélectionnez "Promote Slave". De cette façon, après quelques secondes, notre esclave devient maître, et ce qui était notre maître auparavant, se transforme en esclave.
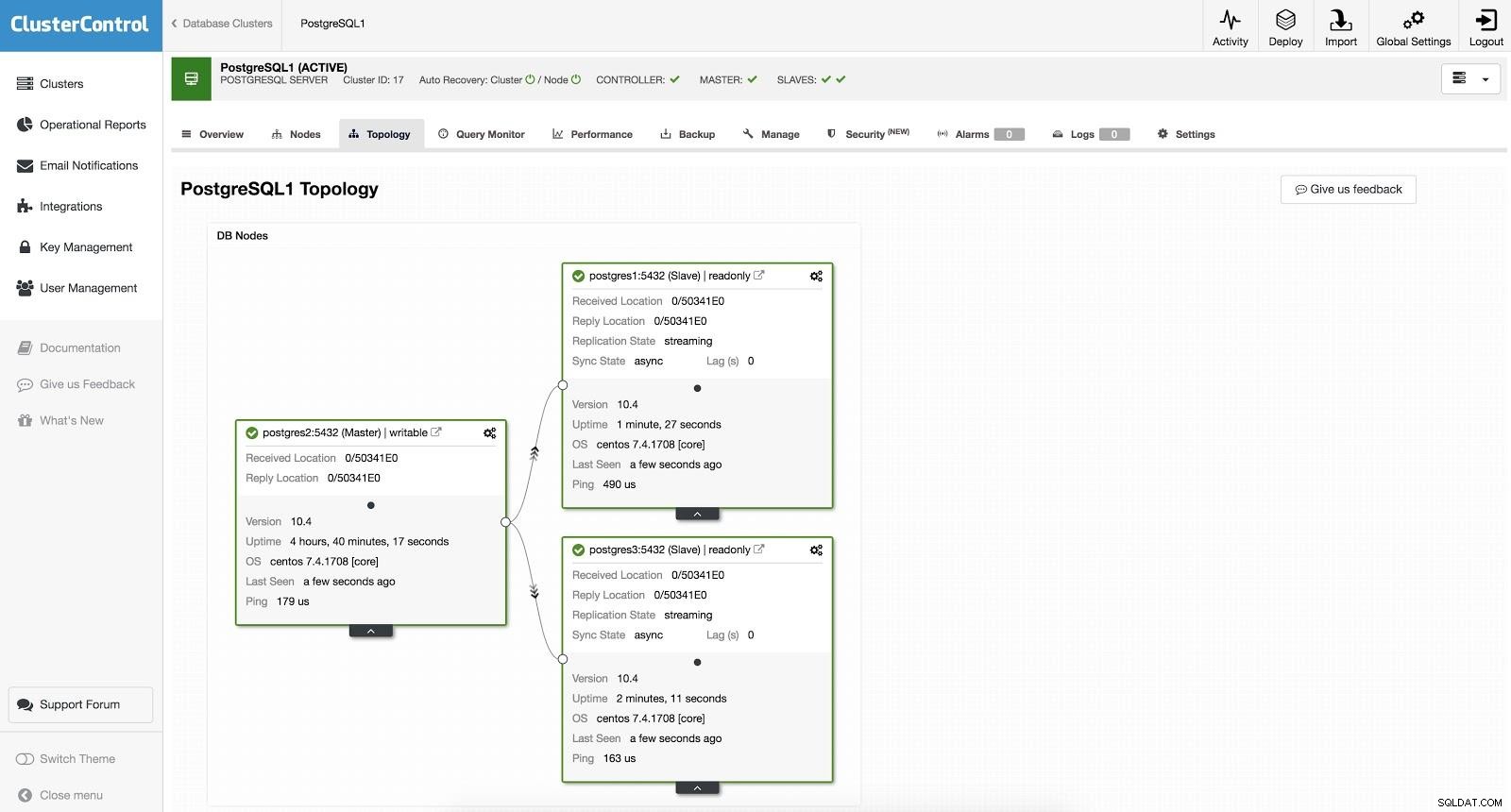 ClusterControl Failover 2
ClusterControl Failover 2 Ce qui précède est utile pour les tâches de migration, de maintenance et de mises à niveau que nous avons vues précédemment.
Basculement automatique
En cas de basculement automatique, ClusterControl détecte les défaillances du maître et promeut un esclave avec les données les plus récentes en tant que nouveau maître. Cela fonctionne également sur le reste des esclaves pour les répliquer à partir du nouveau maître.
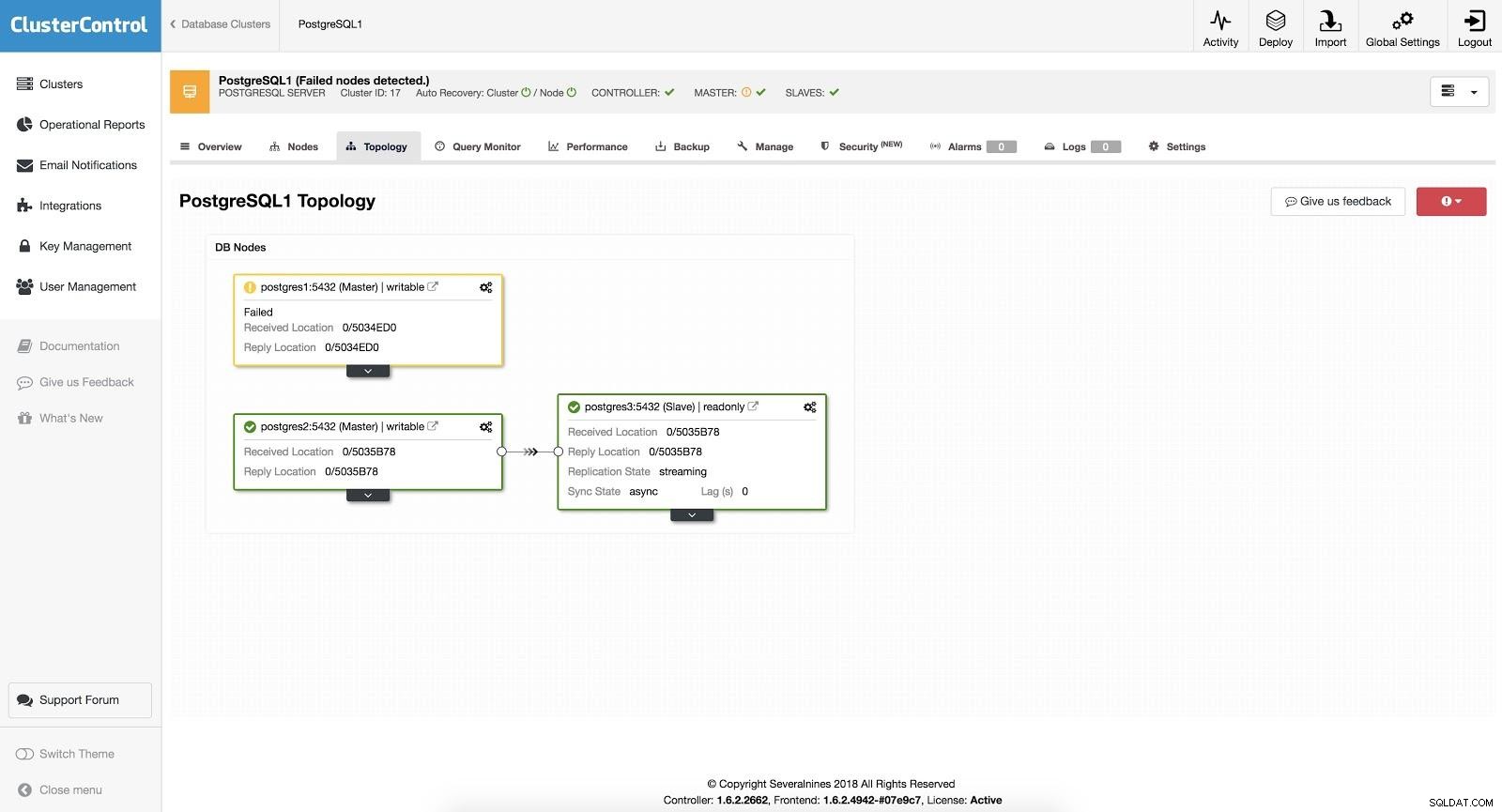 ClusterControl Failover 3
ClusterControl Failover 3 Si l'option "Récupération automatique" est activée, notre ClusterControl effectuera un basculement automatique et nous informera du problème. De cette manière, nos systèmes peuvent récupérer en quelques secondes et sans notre intervention.
Cluster Control nous offre la possibilité de configurer une liste blanche/liste noire pour définir comment nous voulons que nos serveurs soient pris en compte (ou non) lors de la sélection d'un candidat maître.
Parmi ceux disponibles selon la configuration ci-dessus, ClusterControl choisira l'esclave le plus avancé, en utilisant à cet effet pg_current_xlog_location (PostgreSQL 9+) ou pg_current_wal_lsn (PostgreSQL 10+) selon la version de notre base de données.
ClusterControl effectue également plusieurs vérifications sur le processus de basculement, afin d'éviter certaines erreurs courantes. Un exemple est que si nous parvenons à récupérer notre ancien maître défaillant, il ne sera PAS réintroduit automatiquement dans le cluster, ni en tant que maître ni en tant qu'esclave. Nous devons le faire manuellement. Cela évitera la possibilité de perte de données ou d'incohérence dans le cas où notre esclave (que nous avons promu) a été retardé au moment de l'échec. Nous pourrions également vouloir analyser le problème en détail, mais en l'ajoutant à notre cluster, nous pourrions perdre des informations de diagnostic.
De plus, si le basculement échoue, aucune autre tentative n'est effectuée, une intervention manuelle est nécessaire pour analyser le problème et effectuer les actions correspondantes. Ceci afin d'éviter la situation où ClusterControl, en tant que gestionnaire de haute disponibilité, essaie de promouvoir l'esclave suivant et le suivant. Il peut y avoir un problème, et nous ne voulons pas aggraver les choses en tentant plusieurs basculements.
Équilibreurs de charge
Comme nous l'avons mentionné précédemment, l'équilibreur de charge est un outil important à prendre en compte pour notre basculement, surtout si nous voulons utiliser le basculement automatique dans notre topologie de base de données.
Pour que le basculement soit transparent à la fois pour l'utilisateur et pour l'application, nous avons besoin d'un composant intermédiaire, car il ne suffit pas de promouvoir un maître en esclave. Pour cela, nous pouvons utiliser HAProxy + Keepalived.
Qu'est-ce que HAProxy ?
HAProxy est un équilibreur de charge qui répartit le trafic d'une origine vers une ou plusieurs destinations et peut définir des règles et/ou des protocoles spécifiques pour cette tâche. Si l'une des destinations cesse de répondre, elle est marquée comme étant hors ligne et le trafic est envoyé au reste des destinations disponibles. Cela empêche le trafic d'être envoyé vers une destination inaccessible et empêche la perte de ce trafic en le dirigeant vers une destination valide.
Qu'est-ce que Keepalived ?
Keepalived vous permet de configurer une adresse IP virtuelle au sein d'un groupe de serveurs actif/passif. Cette IP virtuelle est attribuée à un serveur « Primaire » actif. Si ce serveur tombe en panne, l'IP est automatiquement migrée vers le serveur "Secondaire" qui s'est avéré passif, lui permettant de continuer à fonctionner avec la même IP de manière transparente pour nos systèmes.
Pour implémenter cette solution avec ClusterControl, nous avons commencé comme si nous allions ajouter un esclave. Accédez à Actions de cluster et sélectionnez Ajouter un équilibreur de charge (voir ClusterControl Ajouter l'image de l'esclave 1).
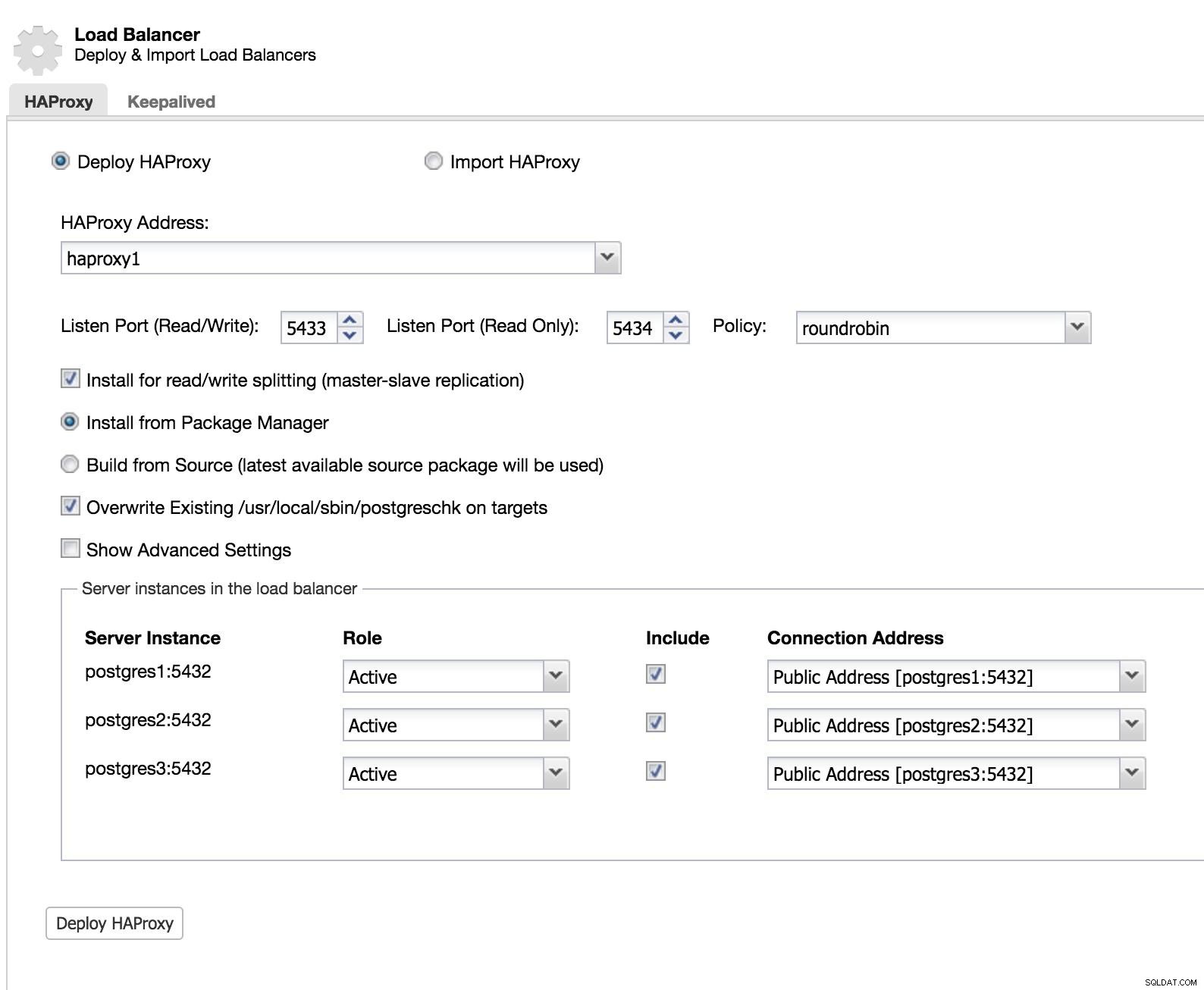 Équilibreur de charge ClusterControl 1
Équilibreur de charge ClusterControl 1 Nous ajoutons les informations de notre nouvel équilibreur de charge et comment nous voulons qu'il se comporte (politique).
Dans le cas où l'on souhaite implémenter le basculement pour notre équilibreur de charge, nous devons configurer au moins deux instances.
Ensuite, nous pouvons configurer Keepalived (Sélectionnez Cluster -> Gérer -> Load Balancer -> Keepalived).
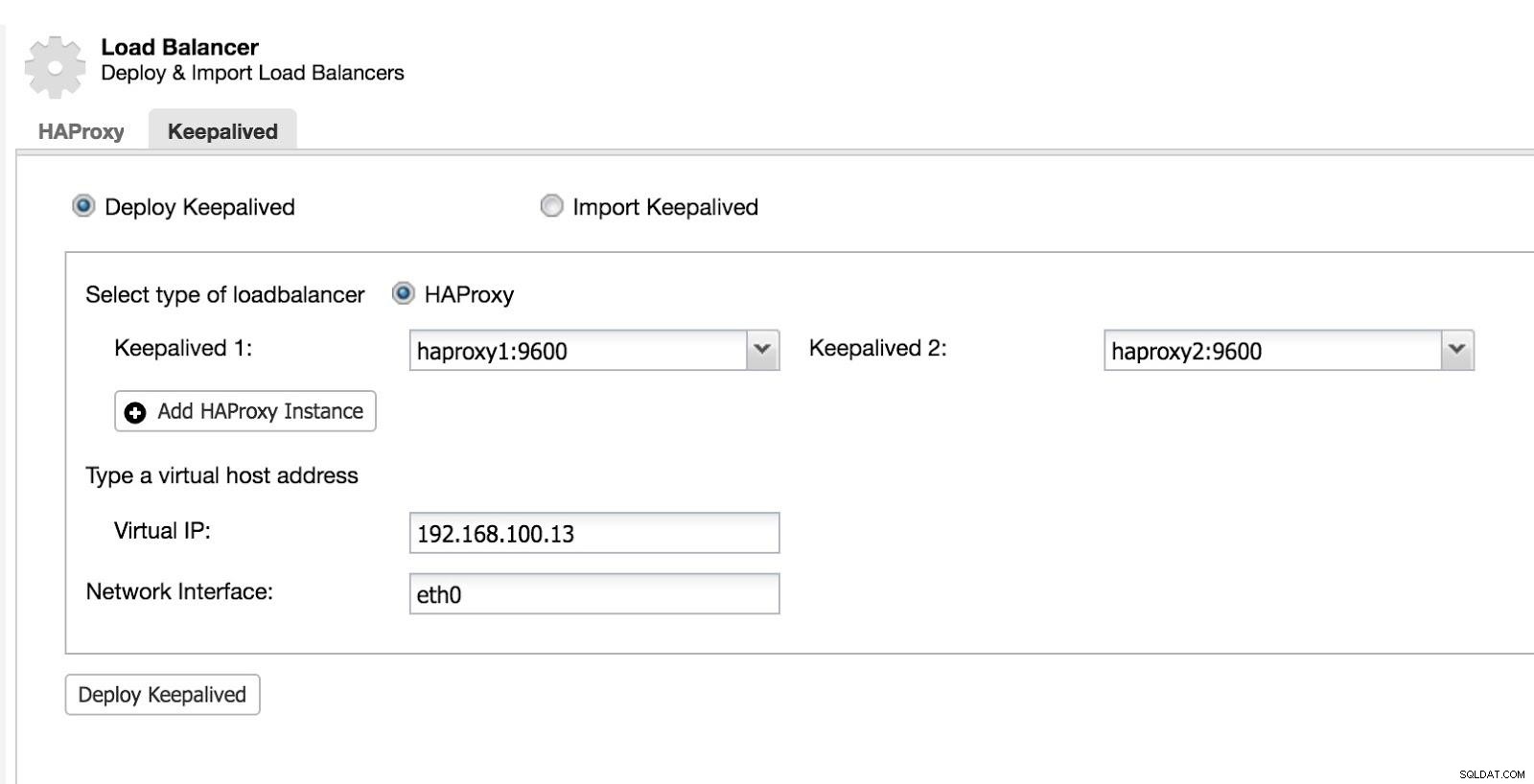 Équilibreur de charge ClusterControl 2
Équilibreur de charge ClusterControl 2 Après cela, nous avons la topologie suivante :
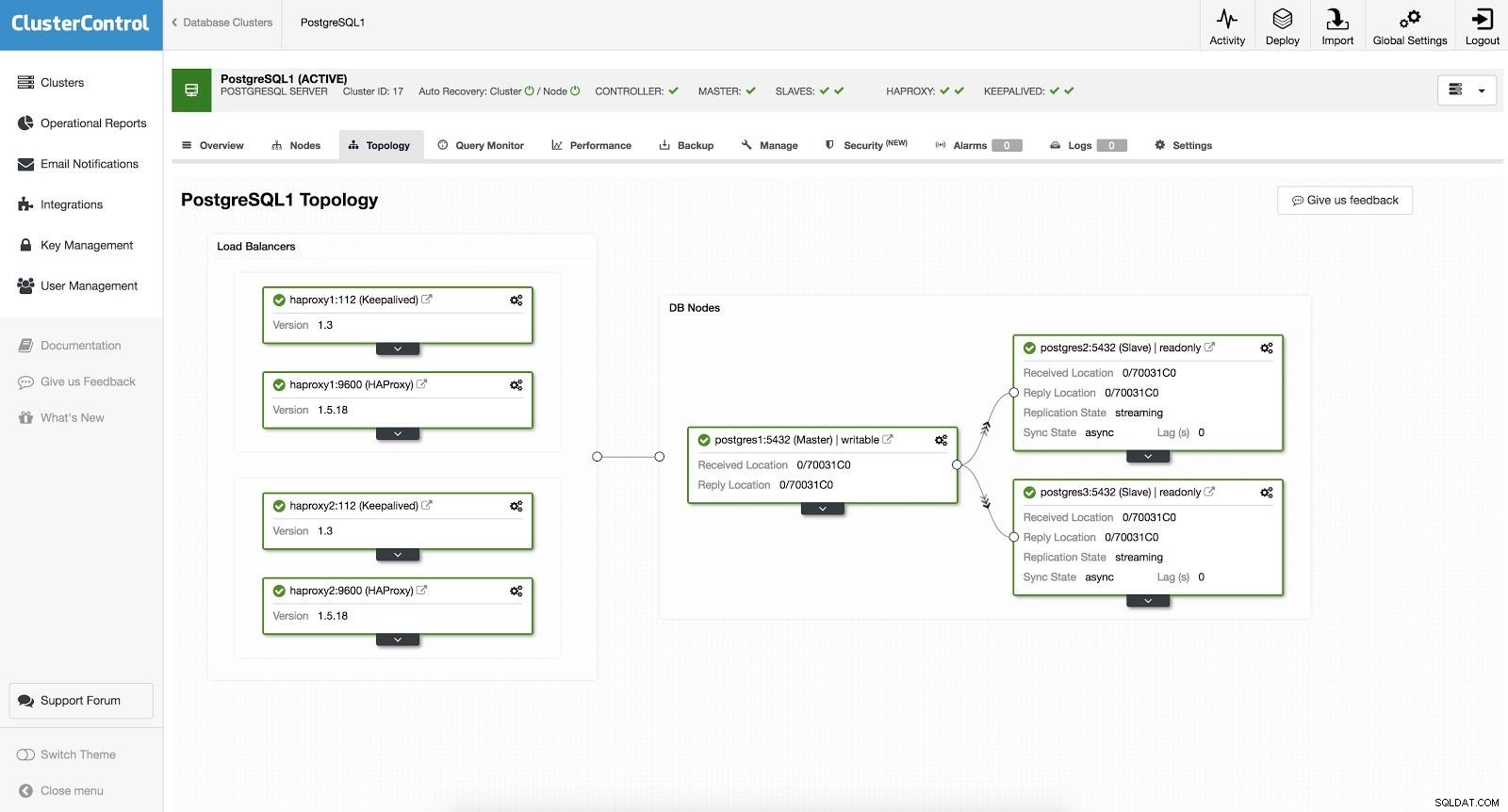 Équilibreur de charge ClusterControl 3
Équilibreur de charge ClusterControl 3 HAProxy est configuré avec deux ports différents, un en lecture-écriture et un en lecture seule.
Dans notre port de lecture-écriture, nous avons notre serveur maître en ligne et le reste de nos nœuds hors ligne. Dans le port en lecture seule, nous avons à la fois le maître et les esclaves en ligne. De cette façon, nous pouvons équilibrer le trafic de lecture entre nos nœuds. Lors de l'écriture, le port de lecture-écriture sera utilisé, qui pointera vers le maître.
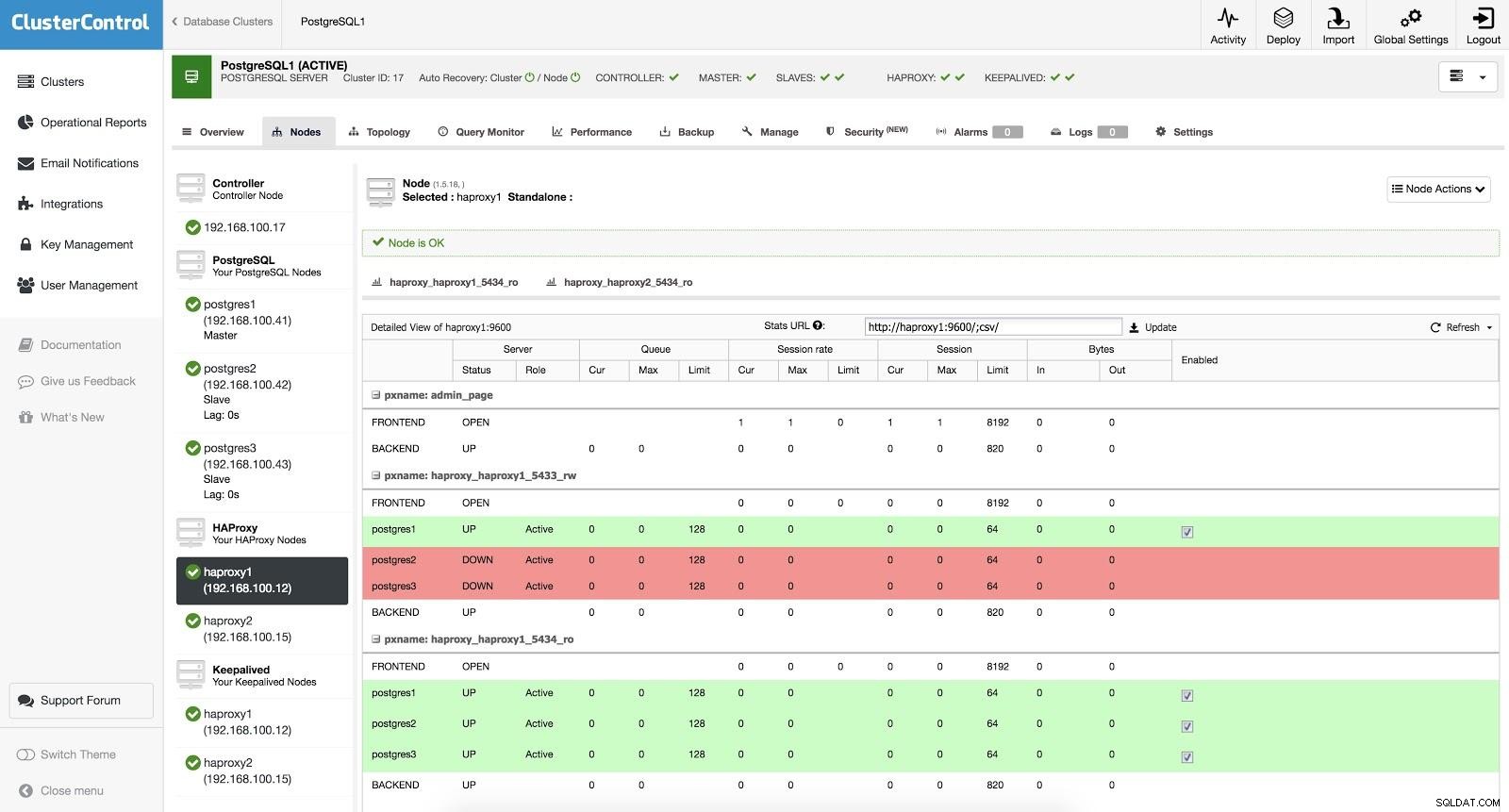 Équilibreur de charge ClusterControl 3
Équilibreur de charge ClusterControl 3 Lorsque HAProxy détecte que l'un de nos nœuds, qu'il soit maître ou esclave, n'est pas accessible, il le marque automatiquement comme étant hors ligne. HAProxy ne lui enverra aucun trafic. Cette vérification est effectuée par des scripts de vérification de l'état configurés par ClusterControl au moment du déploiement. Ceux-ci vérifient si les instances sont actives, si elles sont en cours de récupération ou sont en lecture seule.
Lorsque ClusterControl promeut un esclave en maître, notre HAProxy marque l'ancien maître comme étant hors ligne (pour les deux ports) et met le nœud promu en ligne (dans le port de lecture-écriture). De cette façon, nos systèmes continuent de fonctionner normalement.
Si notre HAProxy actif (qui se voit attribuer une adresse IP virtuelle à laquelle nos systèmes se connectent) tombe en panne, Keepalived migre automatiquement cette IP vers notre HAProxy passif. Cela signifie que nos systèmes peuvent alors continuer à fonctionner normalement.
Conclusion
Comme nous avons pu le voir, le basculement est un élément fondamental de toute base de données de production. Cela peut être utile lors de l'exécution de tâches de maintenance courantes ou de migrations. Nous espérons que ce blog a été utile en tant qu'introduction au sujet, afin que vous puissiez continuer vos recherches et créer vos propres stratégies de basculement.