La mise en production est une tâche très importante qui doit être soigneusement pensée et planifiée au préalable. Certaines décisions moins bonnes peuvent être facilement corrigées par la suite, mais d'autres non. Il est donc toujours préférable de passer ce temps supplémentaire à lire les documents officiels, les livres et les recherches effectuées par d'autres tôt, plutôt que d'être désolé plus tard. Cela est vrai pour la plupart des déploiements de systèmes informatiques, et PostgreSQL ne fait pas exception.
Planification initiale du système
Certaines décisions doivent être prises tôt, avant que le système ne soit opérationnel. Le DBA PostgreSQL doit répondre à un certain nombre de questions :la base de données fonctionnera-t-elle sur du métal nu, des VM ou même en conteneur ? Fonctionnera-t-il dans les locaux de l'organisation ou dans le cloud ? Quel OS sera utilisé ? Le stockage sera-t-il de type disques rotatifs ou SSD ? Pour chaque scénario ou décision, il y a des avantages et des inconvénients et l'appel final se fera en collaboration avec les parties prenantes selon les exigences de l'organisation. Traditionnellement, les gens utilisaient PostgreSQL sur du métal nu, mais cela a radicalement changé ces dernières années avec de plus en plus de fournisseurs de cloud proposant PostgreSQL comme option standard, ce qui est un signe de la large adoption et du résultat de la popularité croissante de PostgreSQL. Indépendamment de la solution spécifique, le DBA doit s'assurer que les données seront sécurisées, ce qui signifie que la base de données pourra survivre aux pannes, et c'est le critère n°1 lors de la prise de décisions concernant le matériel et le stockage. Cela nous amène donc au premier conseil !
Astuce 1
Peu importe ce que le contrôleur de disque ou le fabricant de disque ou le fournisseur de stockage en nuage annoncent, vous devez toujours vous assurer que le stockage ne ment pas sur fsync. Une fois que fsync retourne OK, les données doivent être en sécurité sur le support quoi qu'il arrive par la suite (crash, panne de courant, etc.). Un bel outil qui vous aidera à tester la fiabilité du cache en écriture différée de vos disques est diskchecker.pl.
Lisez simplement les notes :https://brad.livejournal.com/2116715.html et faites le test.
Utilisez une machine pour écouter les événements et la machine réelle pour tester. Vous devriez voir :
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0à la fin du rapport sur la machine testée.
La deuxième préoccupation après la fiabilité devrait concerner les performances. Les décisions concernant le système (CPU, mémoire) étaient autrefois beaucoup plus vitales car il était assez difficile de les changer par la suite. Mais aujourd'hui, à l'ère du cloud, nous pouvons être plus flexibles quant aux systèmes sur lesquels la base de données s'exécute. Il en va de même pour le stockage, en particulier au début de la vie d'un système et alors que les tailles sont encore petites. Lorsque la base de données dépasse le chiffre de TB, il devient de plus en plus difficile de modifier les paramètres de stockage de base sans avoir besoin de copier entièrement la base de données - ou pire encore, d'effectuer un pg_dump, pg_restore. Le deuxième conseil concerne les performances du système.
Astuce 2
De même que pour toujours tester les promesses des fabricants concernant la fiabilité, vous devriez faire de même pour les performances matérielles. Bonnie++ est la référence de performance de stockage la plus populaire pour les systèmes de type Unix. Pour les tests globaux du système (CPU, Mémoire et également stockage), rien n'est plus représentatif que les performances de la base de données. Ainsi, le test de performances de base sur votre nouveau système serait d'exécuter pgbench, la suite officielle de benchmarks PostgreSQL basée sur TCP-B.
Démarrer avec pgbench est assez simple, tout ce que vous avez à faire est :
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Vous devriez toujours consulter pgbench après tout changement important dont vous souhaitez évaluer et comparer les résultats.
Déploiement, automatisation et surveillance du système
Une fois que vous êtes en ligne, il est très important que les principaux composants de votre système soient documentés et reproductibles, que vous disposiez de procédures automatisées pour créer des services et des tâches récurrentes et que vous disposiez également des outils nécessaires pour effectuer une surveillance continue.
Astuce 3
Un moyen pratique de commencer à utiliser PostgreSQL avec toutes ses fonctionnalités d'entreprise avancées est ClusterControl de Manynines. On peut avoir un cluster PostgreSQL de classe entreprise, simplement en appuyant sur quelques clics. ClusterControl fournit tous les services susmentionnés et bien d'autres. La configuration de ClusterControl est assez simple, il suffit de suivre les instructions de la documentation officielle. Une fois que vous avez préparé vos systèmes (généralement un pour exécuter CC et un pour PostgreSQL pour une configuration de base) et effectué la configuration SSH, vous devez entrer les paramètres de base (IP, numéros de port, etc.), et si tout se passe bien, vous devriez voir une sortie comme celle-ci :
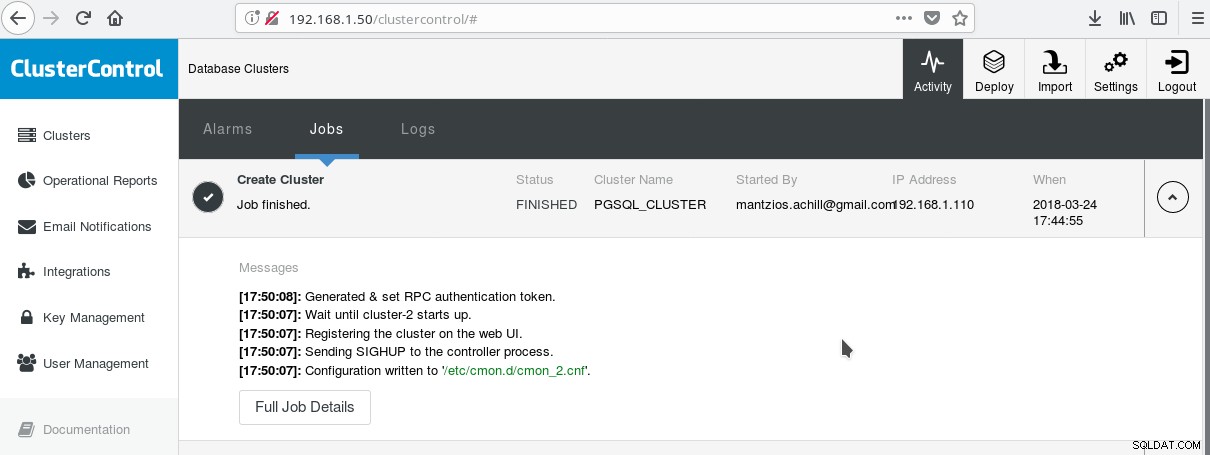
Et dans l'écran principal des clusters :
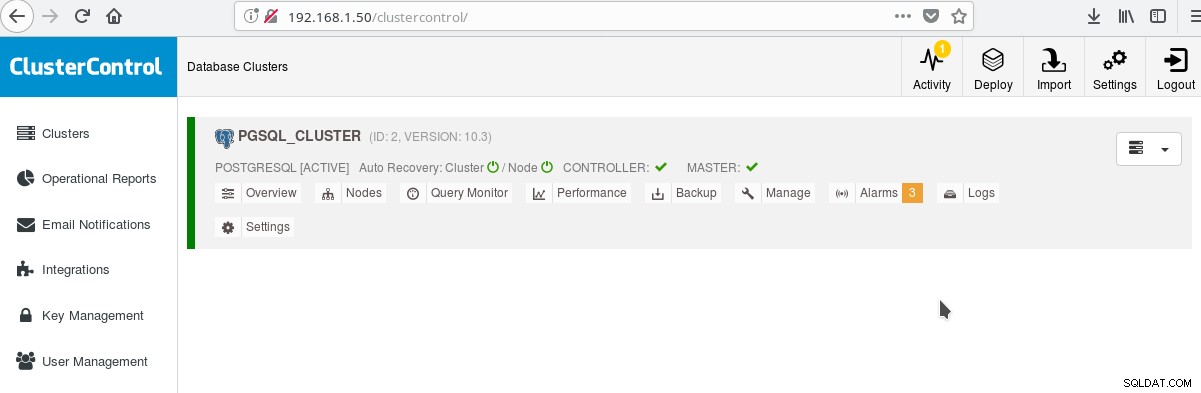
Vous pouvez vous connecter à votre serveur maître et commencer à créer votre schéma ! Bien entendu, vous pouvez vous baser sur le cluster que vous venez de créer pour développer davantage votre infrastructure (topologie). Une bonne idée est généralement d'avoir une disposition stable du système de fichiers du serveur et une configuration finale sur votre serveur PostgreSQL et les bases de données utilisateur/application avant de commencer à créer des clones et des standby (esclaves) basés sur votre tout nouveau serveur que vous venez de créer.
Mise en page, paramètres et paramètres PostgreSQL
Lors de la phase d'initialisation du cluster, la décision la plus importante est d'utiliser ou non les sommes de contrôle des données sur les pages de données. Si vous souhaitez une sécurité maximale des données pour vos précieuses données (futures), c'est le moment de le faire. S'il y a une chance que vous vouliez cette fonctionnalité à l'avenir et que vous négligez de le faire à ce stade, vous ne pourrez pas le changer plus tard (sans pg_dump/pg_restore c'est-à-dire). Voici le conseil suivant :
Astuce 4
Afin d'activer les sommes de contrôle des données, exécutez initdb comme suit :
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Notez que cela devrait être fait au moment du conseil 3 que nous avons décrit ci-dessus. Si vous avez déjà créé le cluster avec ClusterControl, vous devrez relancer pg_createcluster à la main, car au moment d'écrire ces lignes, il n'y a aucun moyen de dire au système ou à CC d'inclure cette option.
Une autre étape très importante avant de passer en production consiste à planifier la disposition du système de fichiers du serveur. La plupart des distributions Linux modernes (du moins celles basées sur Debian) montent tout sur / mais avec PostgreSQL normalement, vous ne voulez pas cela. Il est avantageux d'avoir votre/vos tablespace(s) sur un/des volume(s) séparé(s), d'avoir un volume dédié aux fichiers WAL et un autre pour pg log. Mais le plus important est de déplacer le WAL sur son propre disque. Cela nous amène au conseil suivant.
Astuce 5
Avec PostgreSQL 10 sur Debian Stretch, vous pouvez déplacer votre WAL vers un nouveau disque avec les commandes suivantes (en supposant que le nouveau disque s'appelle /dev/sdb ) :
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlIl est extrêmement important de configurer correctement les paramètres régionaux et l'encodage de vos bases de données. Oubliez cela lors de la phase de création et vous le regretterez beaucoup, car votre application/base de données se déplace dans les territoires i18n, l10n. Le conseil suivant montre comment procéder.
Astuce 6
Vous devriez lire la documentation officielle et décider de vos paramètres COLLATE et CTYPE (createdb --locale=) (responsables de l'ordre de tri et de la classification des caractères) ainsi que du paramètre charset (createdb --encoding=). Spécifier UTF8 comme encodage permettra à votre base de données de stocker du texte multilingue.
Téléchargez le livre blanc aujourd'hui PostgreSQL Management &Automation with ClusterControlDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer PostgreSQLTélécharger le livre blancHaute disponibilité PostgreSQL
Depuis PostgreSQL 9.0, lorsque la réplication en continu est devenue une fonctionnalité standard, il est devenu possible d'avoir un ou plusieurs serveurs de secours en lecture seule, permettant ainsi de diriger le trafic en lecture seule vers n'importe lequel des esclaves disponibles. De nouveaux plans existent pour la réplication multimaître, mais au moment d'écrire ces lignes (10.3), il n'est possible d'avoir qu'un seul maître en lecture-écriture, au moins dans le produit open source officiel. Pour le prochain conseil qui traite exactement de cela.
Astuce 7
Nous allons utiliser notre ClusterControl PGSQL_CLUSTER créé dans l'astuce 3. Nous créons d'abord une deuxième machine qui agira comme notre esclave en lecture seule (hot standby dans la terminologie PostgreSQL). Ensuite, nous cliquons sur Ajouter un esclave de réplication, et sélectionnons notre maître et le nouvel esclave. Une fois la tâche terminée, vous devriez voir cette sortie :
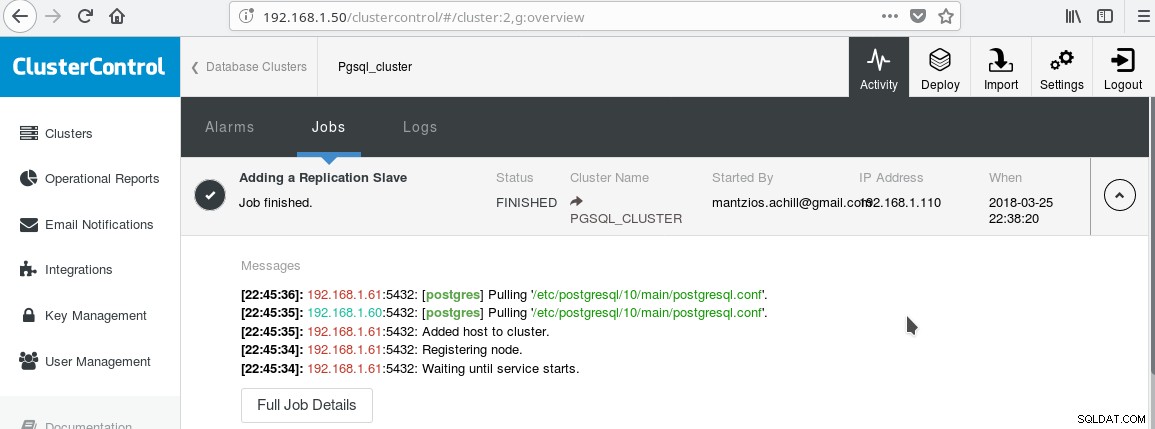
Et le cluster devrait maintenant ressembler à :
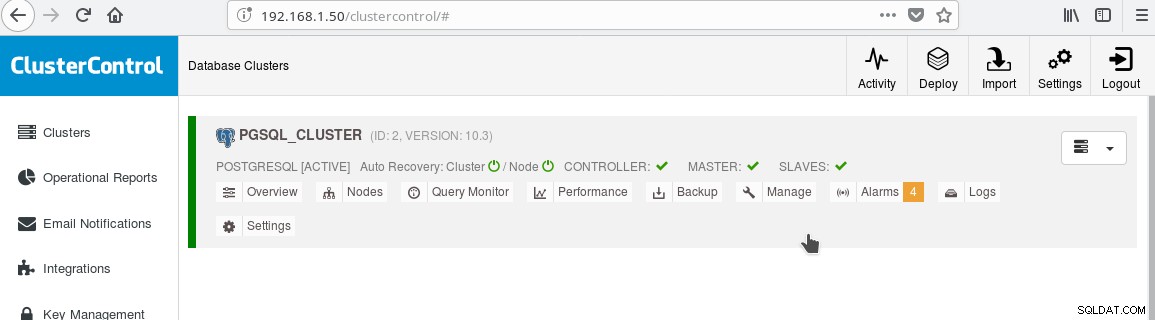
Notez l'icône verte « cochée » sur l'étiquette « SLAVES » à côté de « MASTER ». Vous pouvez vérifier que la réplication en continu fonctionne en créant un objet de base de données (base de données, table, etc.) ou en insérant des lignes dans une table sur le maître et voir le changement sur le standby.
La présence de la veille en lecture seule nous permet d'effectuer un équilibrage de charge pour les clients effectuant des requêtes de sélection uniquement entre les deux serveurs disponibles, le maître et l'esclave. Cela nous amène au conseil 8.
Astuce 8
Vous pouvez activer l'équilibrage de charge entre les deux serveurs à l'aide de HAProxy. Avec ClusterControl, c'est assez facile à faire. Vous cliquez sur Gérer-> Équilibreur de charge. Après avoir choisi votre serveur HAProxy, ClusterControl installera tout pour vous :xinetd sur toutes les instances que vous avez spécifiées et HAProxy sur votre serveur HAProxy désigné. Une fois la tâche terminée avec succès, vous devriez voir :
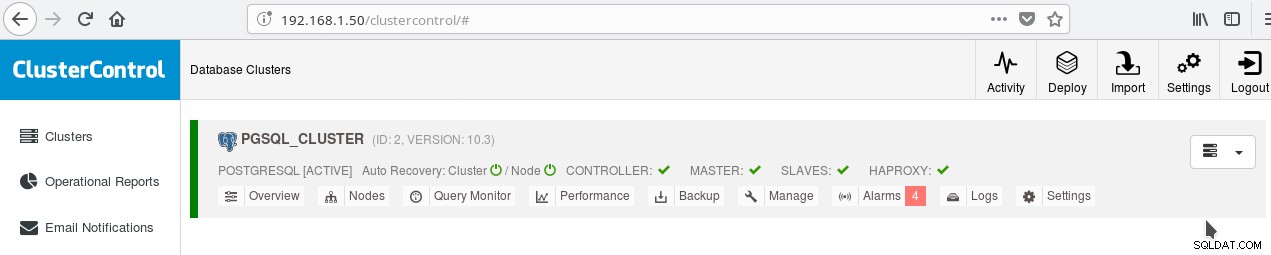
Notez la coche verte HAPROXY à côté des ESCLAVES. Vous pouvez maintenant tester le fonctionnement de HAProxy :
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Astuce 9
Outre la configuration de la haute disponibilité et de l'équilibrage de charge, il est toujours avantageux d'avoir une sorte de pool de connexions devant le serveur PostgreSQL. Pgpool et Pgbouncer sont deux projets issus de la communauté PostgreSQL. De nombreux serveurs d'applications d'entreprise fournissent également leurs propres pools. Pgbouncer a été très populaire en raison de sa simplicité, de sa rapidité et de la fonctionnalité de "transaction pooling", grâce à laquelle la connexion au serveur est libérée une fois la transaction terminée, ce qui le rend réutilisable pour les transactions ultérieures pouvant provenir de la même session ou d'une autre. . Le paramètre de regroupement de transactions interrompt certaines fonctionnalités de regroupement de sessions, mais en général, la conversion en une configuration prête pour le « regroupement de transactions » est facile et les inconvénients ne sont pas si importants dans le cas général. Une configuration courante consiste à configurer le pool du serveur d'applications avec des connexions semi-persistantes :un pool de connexions plutôt plus grand par utilisateur ou par application (qui se connecte à pgbouncer) avec de longs délais d'inactivité. De cette façon, le temps de connexion depuis l'application est minime tandis que pgbouncer aidera à réduire au maximum les connexions au serveur.
Une chose qui vous préoccupera très probablement une fois que vous serez en ligne avec PostgreSQL est de comprendre et de corriger les requêtes lentes. Les outils de surveillance que nous avons mentionnés dans le blog précédent comme pg_stat_statements ainsi que les écrans d'outils comme ClusterControl vous aideront à identifier et éventuellement à suggérer des idées pour corriger les requêtes lentes. Cependant, une fois que vous avez identifié la requête lente, vous devrez exécuter EXPLAIN ou EXPLAIN ANALYZE afin de voir exactement les coûts et les temps impliqués dans le plan de requête. Le conseil suivant concerne un outil très utile pour ce faire.
Astuce 10
Vous devez exécuter votre EXPLAIN ANALYZE sur votre base de données, puis copier la sortie et la coller sur l'outil en ligne d'analyse d'explication de depesz et cliquer sur Soumettre. Ensuite, vous verrez trois onglets :HTML, TEXTE et STATS. HTML contient le coût, le temps et le nombre de boucles pour chaque nœud du plan. L'onglet STATS affiche les statistiques par type de nœud. Vous devez observer la colonne "% de la requête", afin de savoir où votre requête souffre exactement.
Au fur et à mesure que vous vous familiariserez avec PostgreSQL, vous découvrirez de nombreux autres conseils !