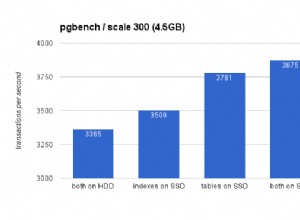
Pourquoi ?
pourquoi la version C est-elle tellement plus rapide ?
Un tableau PostgreSQL est lui-même une structure de données assez inefficace. Il peut contenir tout type de données et il est capable d'être multidimensionnel, donc de nombreuses optimisations ne sont tout simplement pas possibles. Cependant, comme vous l'avez vu, il est possible de travailler avec le même tableau beaucoup plus rapidement en C.
C'est parce que l'accès aux tableaux en C peut éviter une grande partie du travail répété impliqué dans l'accès aux tableaux PL/PgSQL. Jetez un œil à src/backend/utils/adt/arrayfuncs.c , array_ref . Maintenant, regardez comment il est invoqué depuis src/backend/executor/execQual.c dans ExecEvalArrayRef . Qui s'exécute pour chaque accès individuel à la baie depuis PL/PgSQL, comme vous pouvez le voir en attachant gdb au pid trouvé depuis select pg_backend_pid() , en définissant un point d'arrêt à ExecEvalArrayRef , en continuant et en exécutant votre fonction.
Plus important encore, en PL/PgSQL, chaque instruction que vous exécutez est exécutée via la machinerie de l'exécuteur de requêtes. Cela rend les petites déclarations bon marché assez lentes, même en tenant compte du fait qu'elles sont préparées à l'avance. Quelque chose comme :
a := b + c
est en fait exécuté par PL/PgSQL plus comme :
SELECT b + c INTO a;
Vous pouvez observer cela si vous augmentez suffisamment les niveaux de débogage, attachez un débogueur et arrêtez à un point approprié, ou utilisez le auto_explain module avec analyse d'instructions imbriquées. Pour vous donner une idée de la surcharge que cela impose lorsque vous exécutez de nombreuses petites instructions simples (comme des accès au tableau), jetez un œil à cet exemple de backtrace et à mes notes à ce sujet.
Il existe également des frais généraux de démarrage importants à chaque invocation de fonction PL/PgSQL. Ce n'est pas énorme, mais c'est suffisant pour s'additionner lorsqu'il est utilisé comme agrégat.
Une approche plus rapide en C
Dans votre cas, je le ferais probablement en C, comme vous l'avez fait, mais j'éviterais de copier le tableau lorsqu'il est appelé en tant qu'agrégat. Vous pouvez vérifier s'il est appelé dans un contexte agrégé :
if (AggCheckCallContext(fcinfo, NULL))
et si c'est le cas, utilisez la valeur d'origine comme espace réservé mutable, en la modifiant puis en la renvoyant au lieu d'en attribuer une nouvelle. J'écrirai une démo pour vérifier que cela est possible avec des tableaux sous peu ... (mise à jour) ou pas si peu de temps, j'ai oublié à quel point il est horrible de travailler avec des tableaux PostgreSQL en C. C'est parti :
// append to contrib/intarray/_int_op.c
PG_FUNCTION_INFO_V1(add_intarray_cols);
Datum add_intarray_cols(PG_FUNCTION_ARGS);
Datum
add_intarray_cols(PG_FUNCTION_ARGS)
{
ArrayType *a,
*b;
int i, n;
int *da,
*db;
if (PG_ARGISNULL(1))
ereport(ERROR, (errmsg("Second operand must be non-null")));
b = PG_GETARG_ARRAYTYPE_P(1);
CHECKARRVALID(b);
if (AggCheckCallContext(fcinfo, NULL))
{
// Called in aggregate context...
if (PG_ARGISNULL(0))
// ... for the first time in a run, so the state in the 1st
// argument is null. Create a state-holder array by copying the
// second input array and return it.
PG_RETURN_POINTER(copy_intArrayType(b));
else
// ... for a later invocation in the same run, so we'll modify
// the state array directly.
a = PG_GETARG_ARRAYTYPE_P(0);
}
else
{
// Not in aggregate context
if (PG_ARGISNULL(0))
ereport(ERROR, (errmsg("First operand must be non-null")));
// Copy 'a' for our result. We'll then add 'b' to it.
a = PG_GETARG_ARRAYTYPE_P_COPY(0);
CHECKARRVALID(a);
}
// This requirement could probably be lifted pretty easily:
if (ARR_NDIM(a) != 1 || ARR_NDIM(b) != 1)
ereport(ERROR, (errmsg("One-dimesional arrays are required")));
// ... as could this by assuming the un-even ends are zero, but it'd be a
// little ickier.
n = (ARR_DIMS(a))[0];
if (n != (ARR_DIMS(b))[0])
ereport(ERROR, (errmsg("Arrays are of different lengths")));
da = ARRPTR(a);
db = ARRPTR(b);
for (i = 0; i < n; i++)
{
// Fails to check for integer overflow. You should add that.
*da = *da + *db;
da++;
db++;
}
PG_RETURN_POINTER(a);
}
et ajoutez ceci à contrib/intarray/intarray--1.0.sql :
CREATE FUNCTION add_intarray_cols(_int4, _int4) RETURNS _int4
AS 'MODULE_PATHNAME'
LANGUAGE C IMMUTABLE;
CREATE AGGREGATE sum_intarray_cols(_int4) (sfunc = add_intarray_cols, stype=_int4);
(plus correctement, vous créeriez intarray--1.1.sql et intarray--1.0--1.1.sql et mettre à jour intarray.control . Ce n'est qu'un hack rapide.)
Utiliser :
make USE_PGXS=1
make USE_PGXS=1 install
pour compiler et installer.
Maintenant DROP EXTENSION intarray; (si vous l'avez déjà) et CREATE EXTENSION intarray; .
Vous aurez maintenant la fonction d'agrégation sum_intarray_cols à votre disposition (comme votre sum(int4[]) , ainsi que les deux opérandes add_intarray_cols (comme votre array_add ).
En se spécialisant dans les tableaux d'entiers, tout un tas de complexité disparaît. Un tas de copies est évité dans le cas agrégé, car nous pouvons modifier en toute sécurité le tableau "state" (le premier argument) sur place. Pour garder les choses cohérentes, dans le cas d'un appel non agrégé, nous obtenons une copie du premier argument afin que nous puissions toujours travailler avec lui sur place et le renvoyer.
Cette approche pourrait être généralisée pour prendre en charge n'importe quel type de données en utilisant le cache fmgr pour rechercher la fonction d'ajout pour le ou les types d'intérêt, etc. Cela ne m'intéresse pas particulièrement, donc si vous en avez besoin (par exemple, pour additionner les colonnes de NUMERIC tableaux) alors ... amusez-vous.
De même, si vous devez gérer des longueurs de tableau différentes, vous pouvez probablement déterminer ce qu'il faut faire à partir de ce qui précède.