Je ne pense pas que vous puissiez le faire à moindre coût avec une requête simple, des CTE et des fonctions de fenêtre - leur définition de cadre est statique, mais vous avez besoin d'un cadre dynamique (selon les valeurs des colonnes).
En règle générale, vous devrez définir avec soin les limites inférieure et supérieure de votre fenêtre :les requêtes suivantes excluent la ligne actuelle et inclure la bordure inférieure.
Il y a encore une différence mineure :la fonction inclut les pairs précédents de la ligne actuelle, tandis que la sous-requête corrélée les exclut...
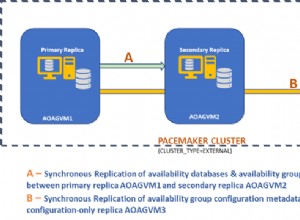
Cas de test
Utilisation de ts au lieu du mot réservé date comme nom de colonne.
CREATE TABLE test (
id bigint
, ts timestamp
);
ROM - Requête de Roman
Utiliser les CTE, agréger les horodatages dans un tableau, désimbriquer, compter...
Bien que correctes, les performances se détériorent considérablement avec plus d'une main pleine de rangées. Il y a quelques tueurs de performance ici. Voir ci-dessous.
ARR - compter les éléments du tableau
J'ai pris la requête de Roman et essayé de la rationaliser un peu :
- Supprimez le 2e CTE qui n'est pas nécessaire.
- Transformez le 1er CTE en sous-requête, ce qui est plus rapide.
- Direct
count()au lieu de se réagréger dans un tableau et de compter avecarray_length().
Mais la gestion des baies coûte cher et les performances se détériorent encore fortement avec plus de lignes.
SELECT id, ts
, (SELECT count(*)::int - 1
FROM unnest(dates) x
WHERE x >= sub.ts - interval '1h') AS ct
FROM (
SELECT id, ts
, array_agg(ts) OVER(ORDER BY ts) AS dates
FROM test
) sub;
COR - sous-requête corrélée
Vous pourriez résolvez-le avec une simple sous-requête corrélée. Beaucoup plus rapide, mais quand même...
SELECT id, ts
, (SELECT count(*)
FROM test t1
WHERE t1.ts >= t.ts - interval '1h'
AND t1.ts < t.ts) AS ct
FROM test t
ORDER BY ts;
FNC - Fonction
Boucle sur les lignes dans l'ordre chronologique avec un row_number() dans la fonction plpgsql et combinez-le avec un curseur sur la même requête, couvrant la période souhaitée. Ensuite, nous pouvons simplement soustraire les numéros de ligne :
CREATE OR REPLACE FUNCTION running_window_ct(_intv interval = '1 hour')
RETURNS TABLE (id bigint, ts timestamp, ct int)
LANGUAGE plpgsql AS
$func$
DECLARE
cur CURSOR FOR
SELECT t.ts + _intv AS ts1, row_number() OVER (ORDER BY t.ts) AS rn
FROM test t ORDER BY t.ts;
rec record;
rn int;
BEGIN
OPEN cur;
FETCH cur INTO rec;
ct := -1; -- init
FOR id, ts, rn IN
SELECT t.id, t.ts, row_number() OVER (ORDER BY t.ts)
FROM test t ORDER BY t.ts
LOOP
IF rec.ts1 >= ts THEN
ct := ct + 1;
ELSE
LOOP
FETCH cur INTO rec;
EXIT WHEN rec.ts1 >= ts;
END LOOP;
ct := rn - rec.rn;
END IF;
RETURN NEXT;
END LOOP;
END
$func$;
Appel avec un intervalle par défaut d'une heure :
SELECT * FROM running_window_ct();
Ou avec n'importe quel intervalle :
SELECT * FROM running_window_ct('2 hour - 3 second');
db<>jouez ici
Vieux sqlfiddle
Référence
Avec le tableau ci-dessus, j'ai exécuté un test rapide sur mon ancien serveur de test :(PostgreSQL 9.1.9 sur Debian).
-- TRUNCATE test;
INSERT INTO test
SELECT g, '2013-08-08'::timestamp
+ g * interval '5 min'
+ random() * 300 * interval '1 min' -- halfway realistic values
FROM generate_series(1, 10000) g;
CREATE INDEX test_ts_idx ON test (ts);
ANALYZE test; -- temp table needs manual analyze
J'ai varié le gras partie pour chaque course et a pris le meilleur des 5 avec EXPLAIN ANALYZE .
100 lignes
ROM :27,656 ms
ARR :7,834 ms
COR :5,488 ms
FNC :1,115 ms
1 000 lignes
ROM :2116,029 ms
ARR :189,679 ms
COR :65,802 ms
FNC :8,466 ms
5 000 lignes
ROM :51347 ms !!
ARR :3167 ms
COR :333 ms
FNC :42 ms
100 000 lignes
ROM :DNF
ARR :DNF
COR :6 760 ms
FNC :828 ms
La fonction est clairement victorieuse. Il est le plus rapide d'un ordre de grandeur et s'adapte le mieux.
La gestion des tableaux ne peut pas rivaliser.