La connaissance de la réplication est indispensable pour quiconque gère des bases de données. C'est un sujet que vous avez probablement vu maintes et maintes fois mais qui ne vieillit jamais. Dans ce blog, nous passerons en revue un peu l'historique des fonctionnalités de réplication intégrées de PostgreSQL et approfondirons le fonctionnement de la réplication en continu.
En parlant de réplication, nous parlerons beaucoup des WAL. Alors, passons rapidement en revue un peu les journaux à écriture anticipée.
Journal d'écriture anticipée (WAL)
Un journal à écriture anticipée est une méthode standard pour garantir l'intégrité des données, et il est automatiquement activé par défaut.
Les WAL sont les journaux REDO dans PostgreSQL. Mais que sont exactement les journaux REDO ?
Les journaux REDO contiennent toutes les modifications apportées à la base de données et sont utilisés pour la réplication, la restauration, la sauvegarde en ligne et la restauration ponctuelle (PITR). Toutes les modifications qui n'ont pas été appliquées aux pages de données peuvent être rétablies à partir des journaux REDO.
L'utilisation de WAL réduit considérablement le nombre d'écritures sur disque car seul le fichier journal doit être vidé sur le disque pour garantir qu'une transaction est validée, plutôt que tous les fichiers de données modifiés par la transaction.
Un enregistrement WAL spécifiera les modifications apportées aux données, bit par bit. Chaque enregistrement WAL sera ajouté dans un fichier WAL. La position d'insertion est un numéro de séquence de journal (LSN), un décalage d'octet dans les journaux, augmentant à chaque nouvel enregistrement.
Les WAL sont stockés dans le répertoire pg_wal (ou pg_xlog dans les versions PostgreSQL <10) sous le répertoire data. Ces fichiers ont une taille par défaut de 16 Mo (vous pouvez modifier la taille en modifiant l'option de configuration --with-wal-segsize lors de la construction du serveur). Ils ont un nom incrémentiel unique au format suivant :"00000001 00000000 00000000".
Le nombre de fichiers WAL contenus dans pg_wal dépendra de la valeur attribuée au paramètre checkpoint_segments (ou min_wal_size et max_wal_size, selon la version) dans le fichier de configuration postgresql.conf.
Un paramètre que vous devez configurer lors de la configuration de toutes vos installations PostgreSQL est le wal_level. Le wal_level détermine la quantité d'informations écrites dans le WAL. La valeur par défaut est minimale, qui n'écrit que les informations nécessaires pour récupérer d'un plantage ou d'un arrêt immédiat. Archive ajoute la journalisation requise pour l'archivage WAL ; hot_standby ajoute en outre les informations nécessaires pour exécuter des requêtes en lecture seule sur un serveur de secours ; logical ajoute les informations nécessaires pour prendre en charge le décodage logique. Ce paramètre nécessite un redémarrage, il peut donc être difficile de le modifier sur les bases de données de production en cours d'exécution si vous l'avez oublié.
Pour plus d'informations, vous pouvez consulter la documentation officielle ici ou ici. Maintenant que nous avons couvert les WAL, passons en revue l'historique de la réplication dans PostgreSQL.
Historique de la réplication dans PostgreSQL
La première méthode de réplication (warm standby) implémentée par PostgreSQL (version 8.2, en 2006) était basée sur la méthode d'envoi de journaux.
Cela signifie que les enregistrements WAL sont directement déplacés d'un serveur de base de données à un autre pour être appliqués. On peut dire que c'est un PITR continu.
PostgreSQL implémente l'envoi de journaux basé sur les fichiers en transférant les enregistrements WAL un fichier (segment WAL) à la fois.
Cette implémentation de réplication a un inconvénient :en cas de panne majeure sur les serveurs primaires, les transactions non encore expédiées seront perdues. Donc, il y a une fenêtre pour la perte de données (vous pouvez régler cela en utilisant le paramètre archive_timeout, qui peut être réglé à quelques secondes seulement. Cependant, un réglage aussi bas augmentera considérablement la bande passante requise pour l'envoi de fichiers).
Nous pouvons représenter cette méthode d'envoi de journaux basée sur des fichiers avec l'image ci-dessous :
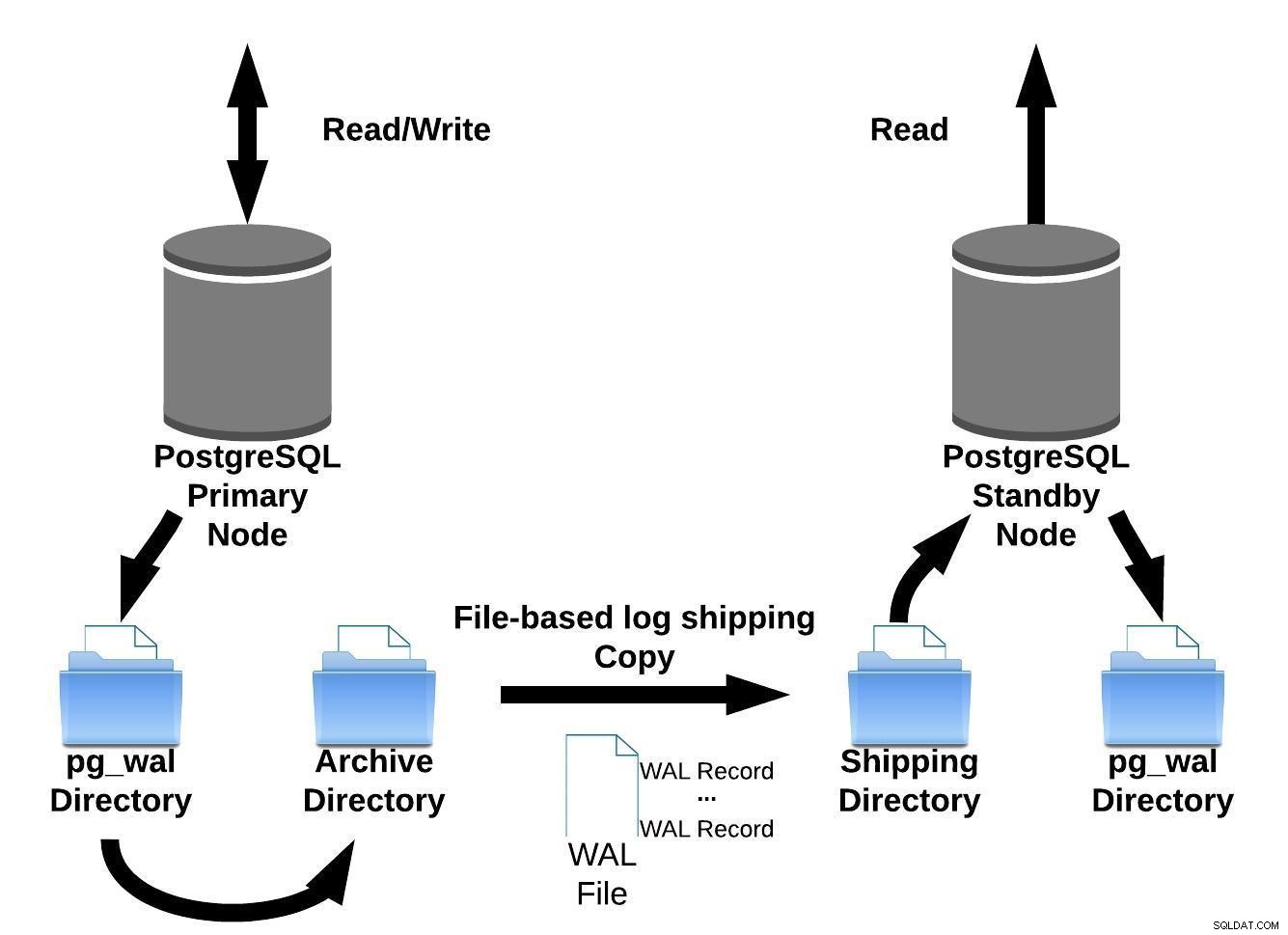 Envoi de journaux basé sur des fichiers PostgreSQL
Envoi de journaux basé sur des fichiers PostgreSQLPuis, dans la version 9.0 (en 2010 ), la réplication en continu a été introduite.
La réplication en continu vous permet de rester plus à jour qu'il n'est possible avec l'envoi de journaux basé sur des fichiers. Cela fonctionne en transférant des enregistrements WAL (un fichier WAL est composé d'enregistrements WAL) à la volée (record-based log shipping) entre un serveur primaire et un ou plusieurs serveurs de secours sans attendre que le fichier WAL soit rempli.
En pratique, un processus appelé récepteur WAL, s'exécutant sur le serveur de secours, se connectera au serveur principal à l'aide d'une connexion TCP/IP. Dans le serveur primaire, un autre processus existe, nommé WAL sender, et est chargé d'envoyer les registres WAL au serveur de secours au fur et à mesure qu'ils se produisent.
Le schéma suivant représente la réplication en continu :
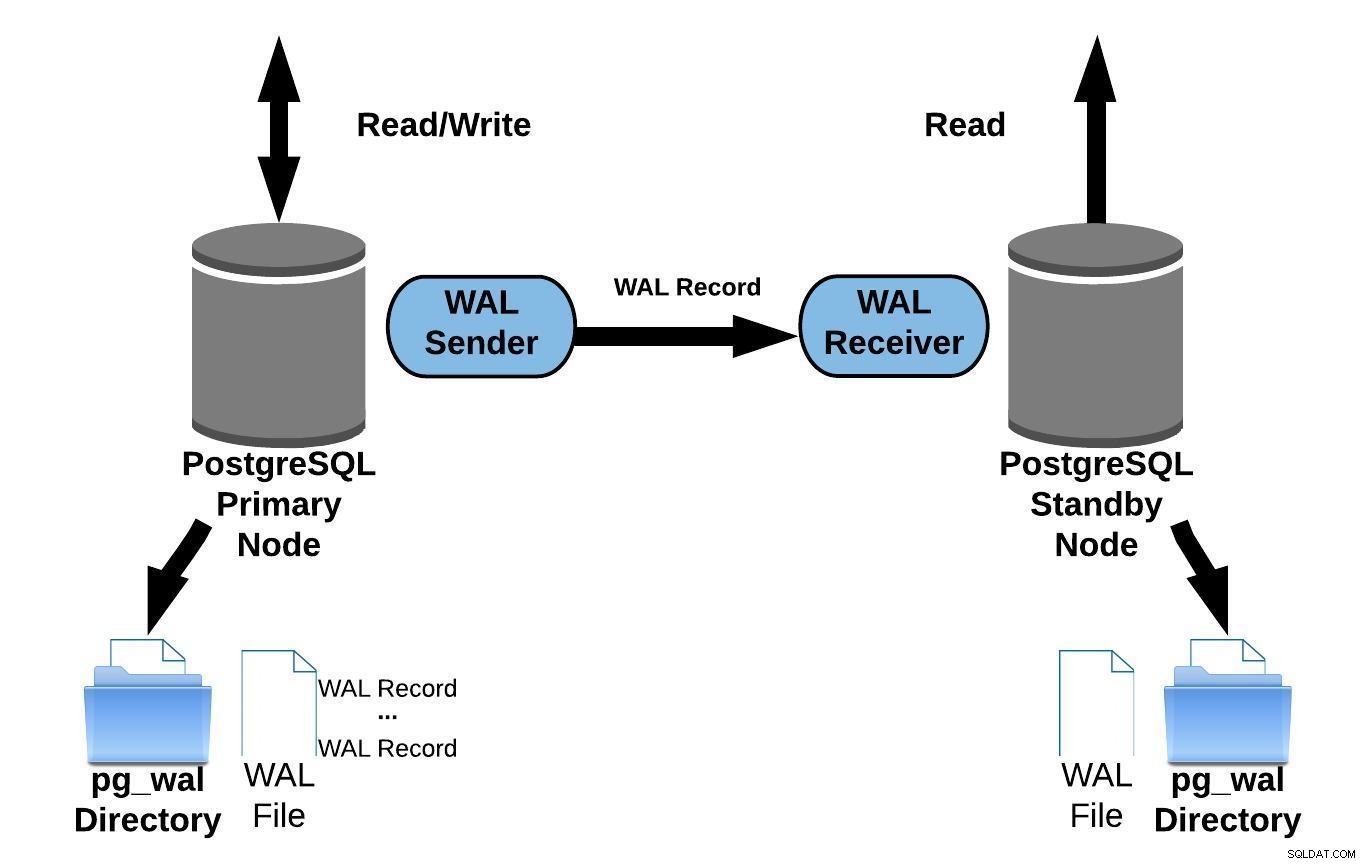 Réplication PostgreSQL Streaming
Réplication PostgreSQL StreamingEn regardant le diagramme ci-dessus, vous vous demandez peut-être ce qui se passe lorsque la communication entre l'émetteur WAL et le récepteur WAL échoue ?
Lors de la configuration de la réplication en continu, vous avez la possibilité d'activer l'archivage WAL.
Cette étape n'est pas obligatoire mais est extrêmement importante pour une configuration de réplication robuste. Il est nécessaire d'éviter que le serveur principal ne recycle d'anciens fichiers WAL qui n'ont pas encore été appliqués au serveur de secours. Si cela se produit, vous devrez recréer la réplique à partir de zéro.
Lors de la configuration de la réplication avec archivage continu, elle démarre à partir d'une sauvegarde. Pour atteindre l'état de synchronisation avec le primaire, il doit appliquer toutes les modifications hébergées dans le WAL qui se sont produites après la sauvegarde. Au cours de ce processus, le standby restaurera d'abord tous les WAL disponibles dans l'emplacement de l'archive (fait en appelant restore_command). La commande restore_command échouera lorsqu'elle atteindra le dernier enregistrement WAL archivé, donc après cela, le standby va regarder dans le répertoire pg_wal pour voir si le changement existe là-bas (cela fonctionne pour éviter la perte de données lorsque les serveurs primaires plantent et certains changements qui ont déjà été déplacés et appliqués au réplica n'ont pas encore été archivés).
Si cela échoue et que l'enregistrement demandé n'existe pas, il commencera à communiquer avec le serveur principal via la réplication en continu.
Chaque fois que la réplication en continu échoue, elle revient à l'étape 1 et restaure à nouveau les enregistrements à partir de l'archive. Cette boucle de tentatives à partir de l'archive, pg_wal, et via la réplication en continu se poursuit jusqu'à ce que le serveur s'arrête ou que le basculement soit déclenché par un fichier déclencheur.
Le schéma suivant représente une configuration de réplication en continu avec archivage continu :
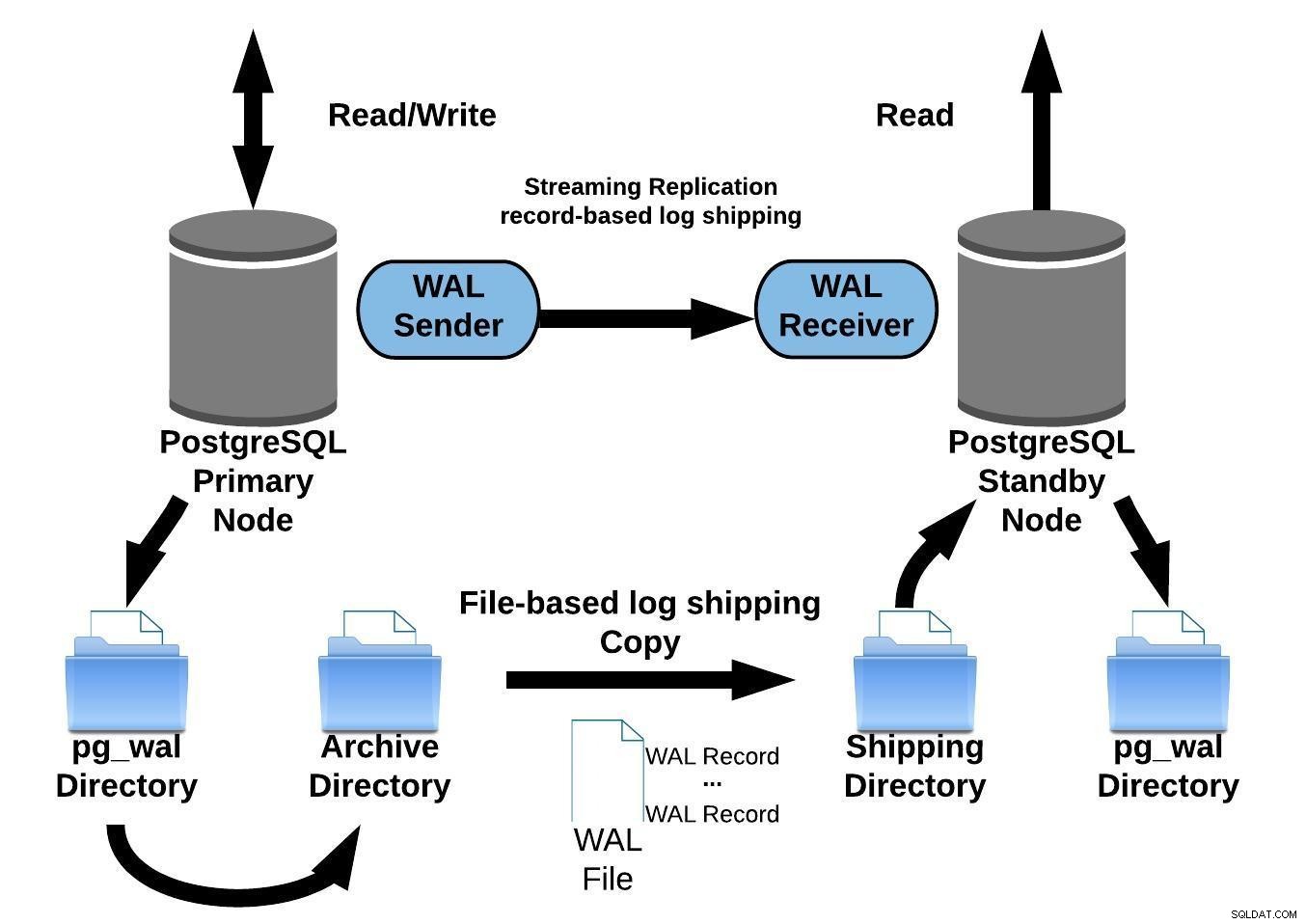 Réplication en continu PostgreSQL avec archivage continu
Réplication en continu PostgreSQL avec archivage continuLa réplication en continu est asynchrone par défaut, donc à à tout moment, certaines transactions peuvent être validées sur le serveur principal et non encore répliquées sur le serveur de secours. Cela implique une perte potentielle de données.
Cependant, ce délai entre la validation et l'impact des modifications dans la réplique est censé être très faible (quelques millisecondes), en supposant, bien sûr, que le serveur de réplique soit suffisamment puissant pour suivre la charge.
Pour les cas où même le risque d'une légère perte de données n'est pas acceptable, la version 9.1 a introduit la fonctionnalité de réplication synchrone.
Dans la réplication synchrone, chaque validation d'une transaction d'écriture attend jusqu'à ce que la confirmation soit reçue que la validation est écrite dans le journal d'écriture anticipée sur le disque du serveur principal et du serveur de secours.
Cette méthode minimise la possibilité de perte de données ; pour que cela se produise, vous aurez besoin que le primaire et le standby échouent simultanément.
L'inconvénient évident de cette configuration est que le temps de réponse pour chaque transaction d'écriture augmente, car il doit attendre que toutes les parties aient répondu. Ainsi, le temps d'un commit est, au minimum, l'aller-retour entre le primaire et le réplica. Les transactions en lecture seule ne seront pas affectées par cela.
Pour configurer la réplication synchrone, vous devez spécifier un nom d'application dans le primary_conninfo de la récupération pour chaque fichier server.conf de secours :primary_conninfo ='...aplication_name=standbyX' .
Vous devez également spécifier la liste des serveurs de secours qui participeront à la réplication synchrone :synchronous_standby_name ='standbyX,standbyY'.
Vous pouvez configurer un ou plusieurs serveurs synchrones, et ce paramètre spécifie également la méthode (FIRST et ANY) pour choisir les standbys synchrones parmi ceux listés. Pour plus d'informations sur la configuration du mode de réplication synchrone, consultez ce blog. Il est également possible de mettre en place une réplication synchrone lors du déploiement via ClusterControl.
Une fois que vous avez configuré votre réplication et qu'elle est opérationnelle, vous devrez implémenter la surveillance
Surveillance de la réplication PostgreSQL
La vue pg_stat_replication sur le serveur maître contient de nombreuses informations pertinentes :
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Voyons cela en détail :
-
pid :ID de processus du processus walsender.
-
usesysid :OID de l'utilisateur utilisé pour la réplication en continu.
-
usename :nom de l'utilisateur utilisé pour la réplication en continu.
-
application_name :nom de l'application connectée au maître.
-
client_addr :adresse de la réplication en veille/en continu.
-
client_hostname :nom d'hôte de veille.
-
client_port :numéro de port TCP sur lequel la veille communique avec l'expéditeur WAL.
-
backend_start :heure de début à laquelle le SR s'est connecté au principal.
-
état :état actuel de l'expéditeur WAL, c'est-à-dire, streaming.
-
sent_lsn :dernier emplacement de transaction envoyé en attente.
-
write_lsn :dernière transaction écrite sur le disque en veille.
-
flush_lsn :dernier vidage de transaction sur le disque en veille.
-
replay_lsn :dernier vidage de transaction sur le disque en veille.
-
sync_priority :priorité du serveur de secours choisi comme serveur de secours synchrone.
-
sync_state :état de synchronisation de veille (est-il asynchrone ou synchrone).
Vous pouvez également voir les processus d'envoi/de réception WAL exécutés sur les serveurs.
Expéditeur (nœud principal) :
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Récepteur (nœud de veille) :
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Une façon de vérifier à quel point votre réplication est à jour consiste à vérifier la quantité d'enregistrements WAL générés sur le serveur principal, mais pas encore appliqués sur le serveur de secours.
Principal :
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)Veille :
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Vous pouvez utiliser la requête suivante dans le nœud de secours pour obtenir le décalage en secondes :
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)Et vous pouvez également voir le dernier message reçu :
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Surveillance de la réplication PostgreSQL avec ClusterControl
Pour surveiller votre cluster PostgreSQL, vous pouvez utiliser ClusterControl, qui vous permet de surveiller et d'effectuer plusieurs tâches de gestion supplémentaires telles que le déploiement, les sauvegardes, la mise à l'échelle, etc.
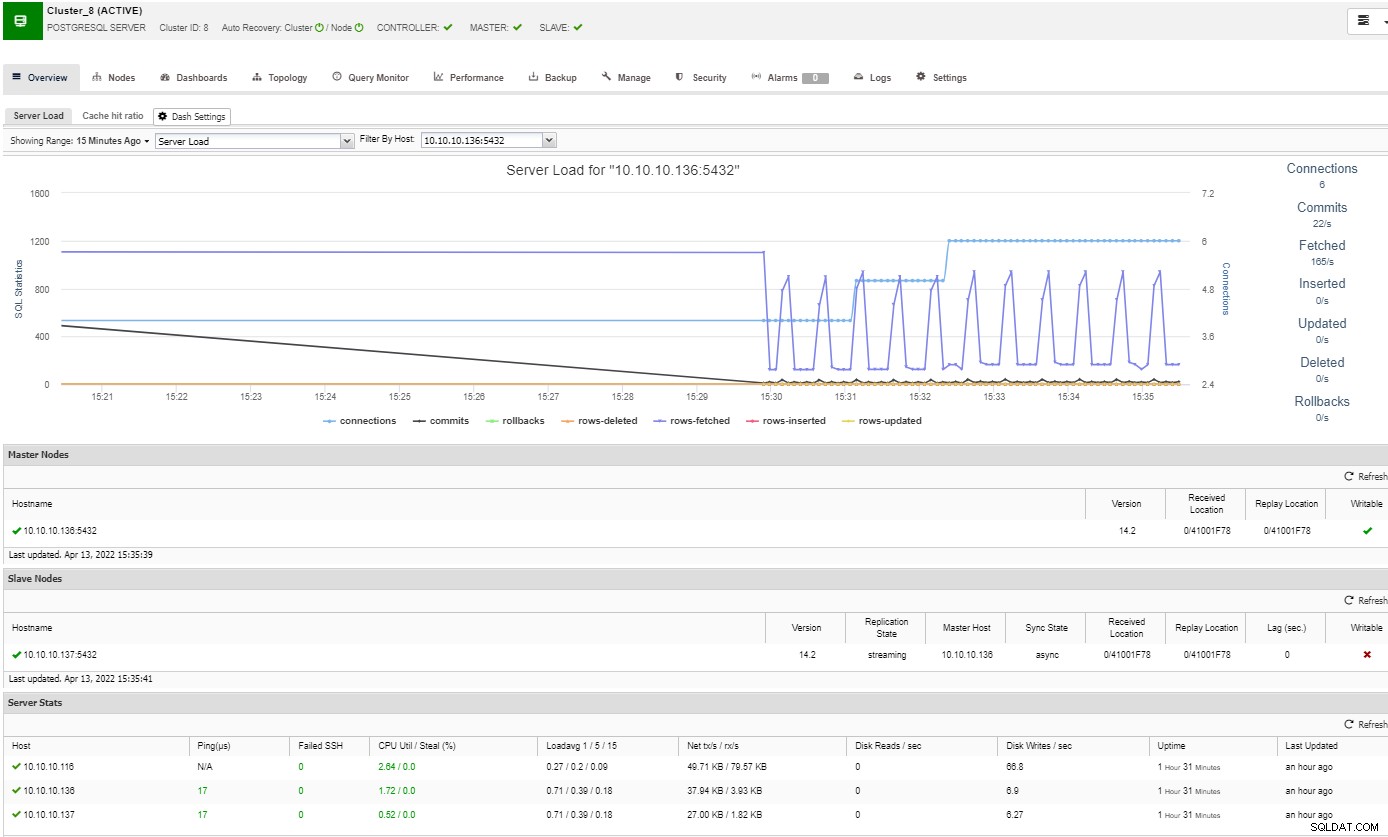
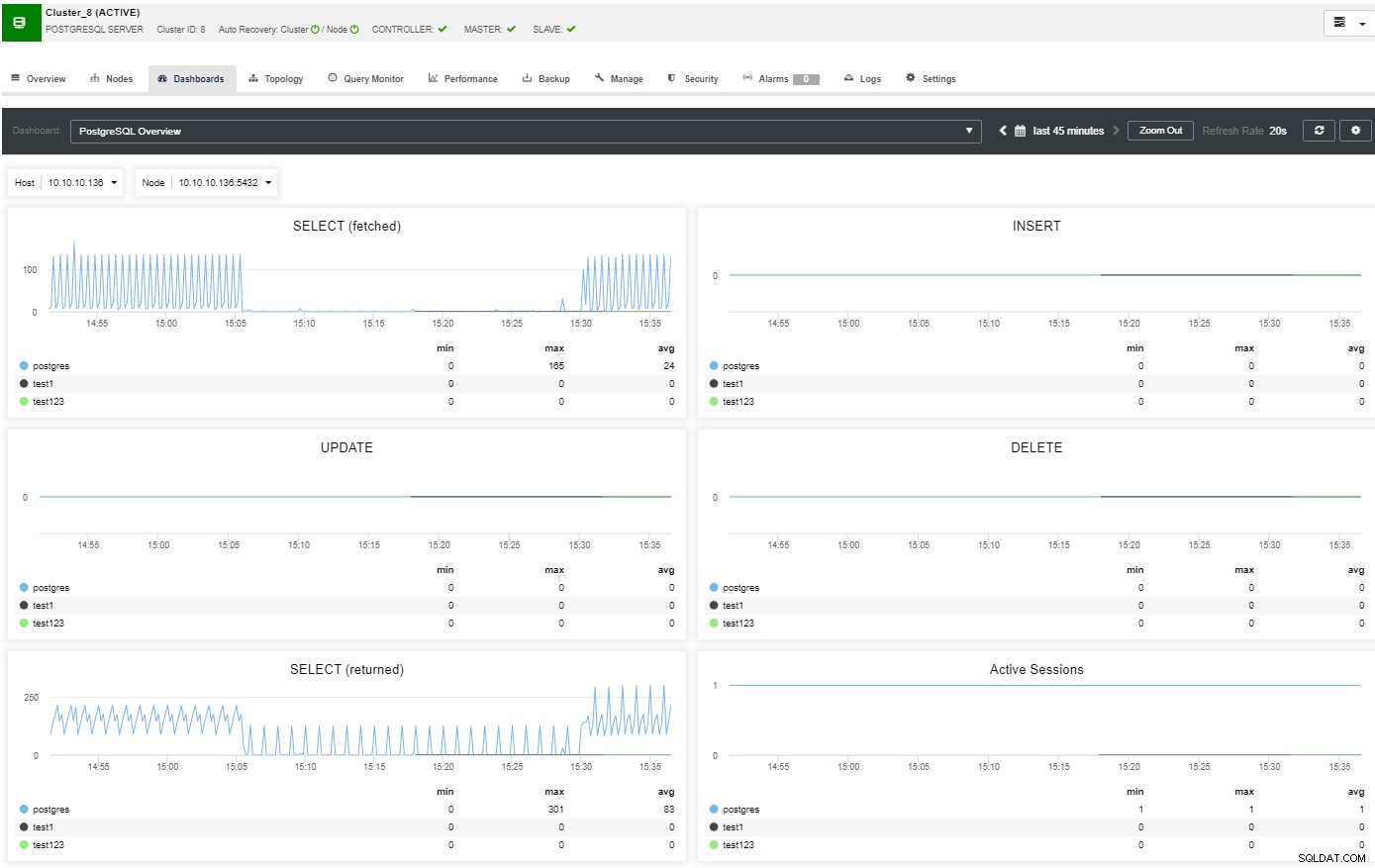
Dans la section vue d'ensemble, vous aurez une image complète de votre cluster de base de données statut actuel. Pour voir plus de détails, vous pouvez accéder à la section du tableau de bord, où vous verrez de nombreuses informations utiles séparées dans différents graphiques.
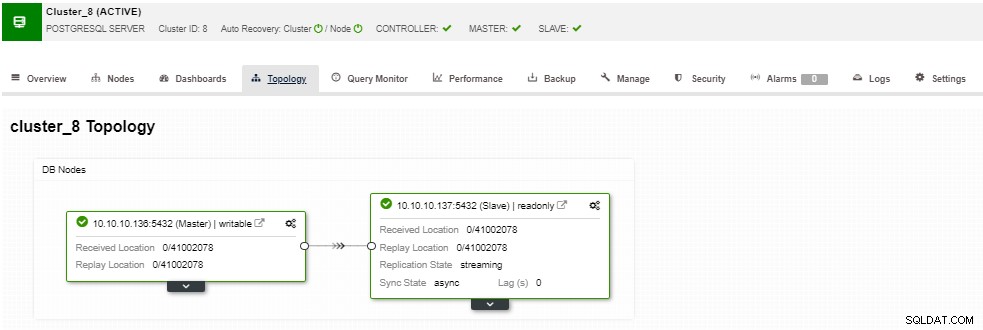
Dans la section topologie, vous pouvez voir votre topologie actuelle dans un fichier utilisateur manière conviviale, et vous pouvez également effectuer différentes tâches sur les nœuds en utilisant le bouton Node Action.
La réplication en continu est basée sur l'envoi des enregistrements WAL et leur application au standby serveur, il dicte quels octets ajouter ou modifier dans quel fichier. Par conséquent, le serveur de secours est en fait une copie bit à bit du serveur principal. Il existe cependant certaines limitations bien connues :
-
Vous ne pouvez pas répliquer dans une version ou une architecture différente.
-
Vous ne pouvez rien modifier sur le serveur de secours.
-
Vous n'avez pas beaucoup de granularité sur ce que vous répliquez.
Ainsi, pour surmonter ces limitations, PostgreSQL 10 a ajouté la prise en charge de la réplication logique
Réplication logique
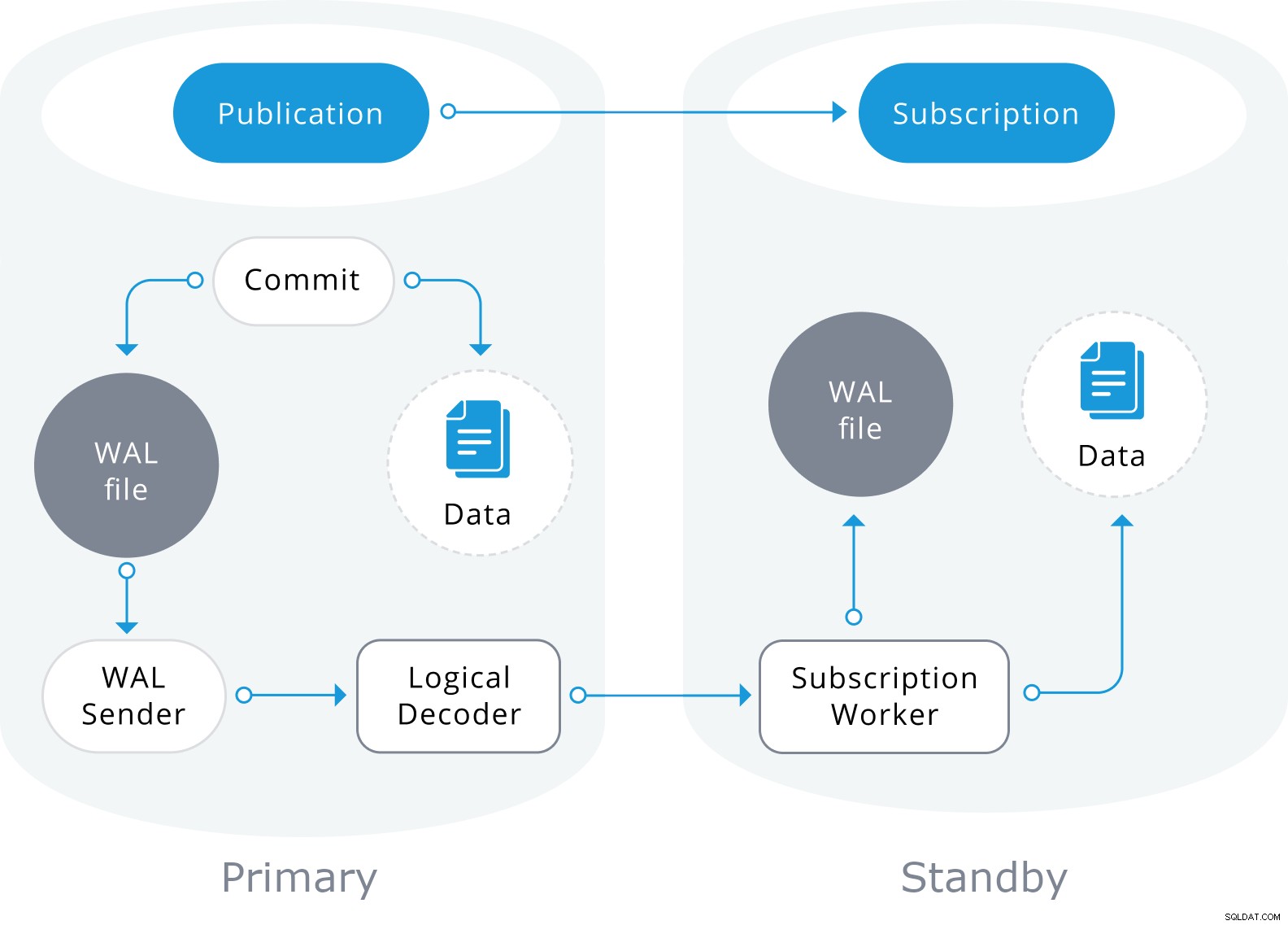
La réplication logique utilisera également les informations du fichier WAL, mais les décodera en modifications logiques. Au lieu de savoir quel octet a changé, il saura précisément quelles données ont été insérées dans quelle table.
Il est basé sur un modèle "publier" et "s'abonner" avec un ou plusieurs abonnés s'abonnant à une ou plusieurs publications sur un nœud d'éditeur qui ressemble à ceci :
Conclusion
Avec la réplication en continu, vous pouvez envoyer et appliquer en continu des enregistrements WAL à vos serveurs de secours, garantissant que les informations mises à jour sur le serveur principal sont transférées au serveur de secours en temps réel, permettant aux deux de rester synchronisés .
ClusterControl simplifie la configuration de la réplication en continu et vous pouvez l'évaluer gratuitement pendant 30 jours.
Si vous souhaitez en savoir plus sur la réplication logique dans PostgreSQL, assurez-vous de consulter cet aperçu de la réplication logique et cet article sur les meilleures pratiques de réplication PostgreSQL.
Pour plus de conseils et de meilleures pratiques pour gérer votre base de données open source, suivez-nous sur Twitter et LinkedIn, et abonnez-vous à notre newsletter pour des mises à jour régulières.