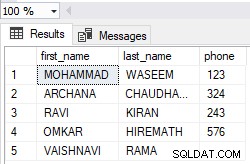
Vous n'êtes pas , en fait, en utilisant des fonctions d'agrégation. Vous utilisez des fonctions de fenêtre . C'est pourquoi PostgreSQL exige sp.payout et s.buyin à inclure dans le GROUP BY clause.
En ajoutant un OVER clause, la fonction d'agrégation sum() est transformé en une fonction de fenêtre, qui agrège les valeurs par partition tout en gardant toutes les lignes.
Vous pouvez combiner les fonctions de fenêtre et les fonctions d'agrégation . Les agrégations sont appliquées en premier. D'après votre description, je n'ai pas compris comment vous souhaitez gérer plusieurs paiements/buyins par événement. Comme une conjecture, je calcule une somme d'entre eux par événement. Maintenant Je peux supprimer sp.payout et s.buyin du GROUP BY clause et obtenez une ligne par player et event :
SELECT p.name
, e.event_id
, e.date
, sum(sum(sp.payout)) OVER w
- sum(sum(s.buyin )) OVER w AS "Profit/Loss"
FROM player p
JOIN result r ON r.player_id = p.player_id
JOIN game g ON g.game_id = r.game_id
JOIN event e ON e.event_id = g.event_id
JOIN structure s ON s.structure_id = g.structure_id
JOIN structure_payout sp ON sp.structure_id = g.structure_id
AND sp.position = r.position
WHERE p.player_id = 17
GROUP BY e.event_id
WINDOW w AS (ORDER BY e.date, e.event_id)
ORDER BY e.date, e.event_id;
Dans cette expression :sum(sum(sp.payout)) OVER w , le sum() externe est une fonction de fenêtre, le sum() interne est une fonction d'agrégation.
En supposant p.player_id et e.event_id sont PRIMARY KEY dans leurs tables respectives.
J'ai ajouté e.event_id au ORDER BY de la WINDOW clause pour arriver à un ordre de tri déterministe. (Il peut y avoir plusieurs événements à la même date.) Également inclus event_id dans le résultat pour distinguer plusieurs événements par jour.
Alors que la requête se limite à un seul joueur (WHERE p.player_id = 17 ), nous n'avons pas besoin d'ajouter p.name ou p.player_id à GROUP BY et ORDER BY . Si l'une des jointures multipliait indûment les lignes, la somme résultante serait incorrecte (multipliée partiellement ou complètement). Regroupement par p.name n'a pas pu réparer la requête alors.
J'ai également supprimé e.date du GROUP BY clause. La clé primaire e.event_id couvre toutes les colonnes de la ligne d'entrée depuis PostgreSQL 9.1.
Si vous modifiez la requête pour renvoyer plusieurs joueurs à la fois, adaptez :
...
WHERE p.player_id < 17 -- example - multiple players
GROUP BY p.name, p.player_id, e.date, e.event_id -- e.date and p.name redundant
WINDOW w AS (ORDER BY p.name, p.player_id, e.date, e.event_id)
ORDER BY p.name, p.player_id, e.date, e.event_id;
Sauf si p.name est défini unique (?), regrouper et trier par player_id en outre pour obtenir des résultats corrects dans un ordre de tri déterministe.
Je n'ai gardé que e.date et p.name dans GROUP BY pour avoir un ordre de tri identique dans toutes les clauses, en espérant un gain de performances. Sinon, vous pouvez supprimer les colonnes ici. (Similaire pour seulement e.date dans la première requête.)