Eh bien, analyser la propagation du coronavirus SARS-CoV-2 n'était pas mon cas d'utilisation rêvé . Mais sur la base des réponses à l'article Tracking Coronavirus COVID-19 Near Real Time with SAP HANA XSA de Ferry Djaja, j'ai décidé d'ajouter également mes deux groszy.
[Mise à jour le 20-03-30 avec les liens modifiés vers les données source ; et la nouvelle sortie de carte basée sur la nouvelle granularité des données. Merci Douglas Maltby pour votre commentaire !]
Dans son article de blog, Ferry a utilisé JavaScript dans SAP HANA XSA pour extraire les données des fichiers CSV mis à jour quotidiennement par l'Université Johns Hopkins.
Je voudrais vous montrer comment vous pouvez extraire et charger ces fichiers dans SAP HANA en utilisant seulement quelques lignes de code grâce à SAP HANA Python Client API for Machine Learning (hana_ml paquet).
Certaines personnes ont été confondues avec la visualisation sur la carte à la fin - veuillez noter que cet article se concentre sur le cas d'utilisation technique reliant différents composants, et non sur l'analyse approfondie des données sur les coronavirus.
Obtenir l'environnement Python, par ex. Jupyter
J'utiliserai Jupyter dans le conteneur Docker pour cela. Veuillez consulter mon article précédent Comprendre les conteneurs (partie 05) :fichiers partagés entre l'hôte et les conteneurs si vous ne savez pas comment le démarrer. Vous pouvez également effectuer les mêmes étapes ci-dessous à partir de n'importe quel autre environnement Python.
Donc, j'ai mon conteneur myjupyter01 course. Je suis connecté à l'interface utilisateur Jupyter comme décrit dans le blog précédent.
Installer hana_ml
L'image Jupyter que j'ai utilisée à partir du registre Docker Hub était jupyter/minimal-notebook . Il contient déjà certains packages de traitement de données populaires, comme pandas .
Mais en plus, je dois installer hana_ml , qui — dans sa version actuelle 1.0.8 — est disponible sur le référentiel PyPI :https://pypi.org/project/hana-ml/.
La commande pour lancer l'installation est python -m pip install hana_ml , mais parce que je l'exécute à partir du bloc-notes Jupyter avec le noyau Python3, je dois l'exécuter avec ! au début :
!python -m pip install hana_ml
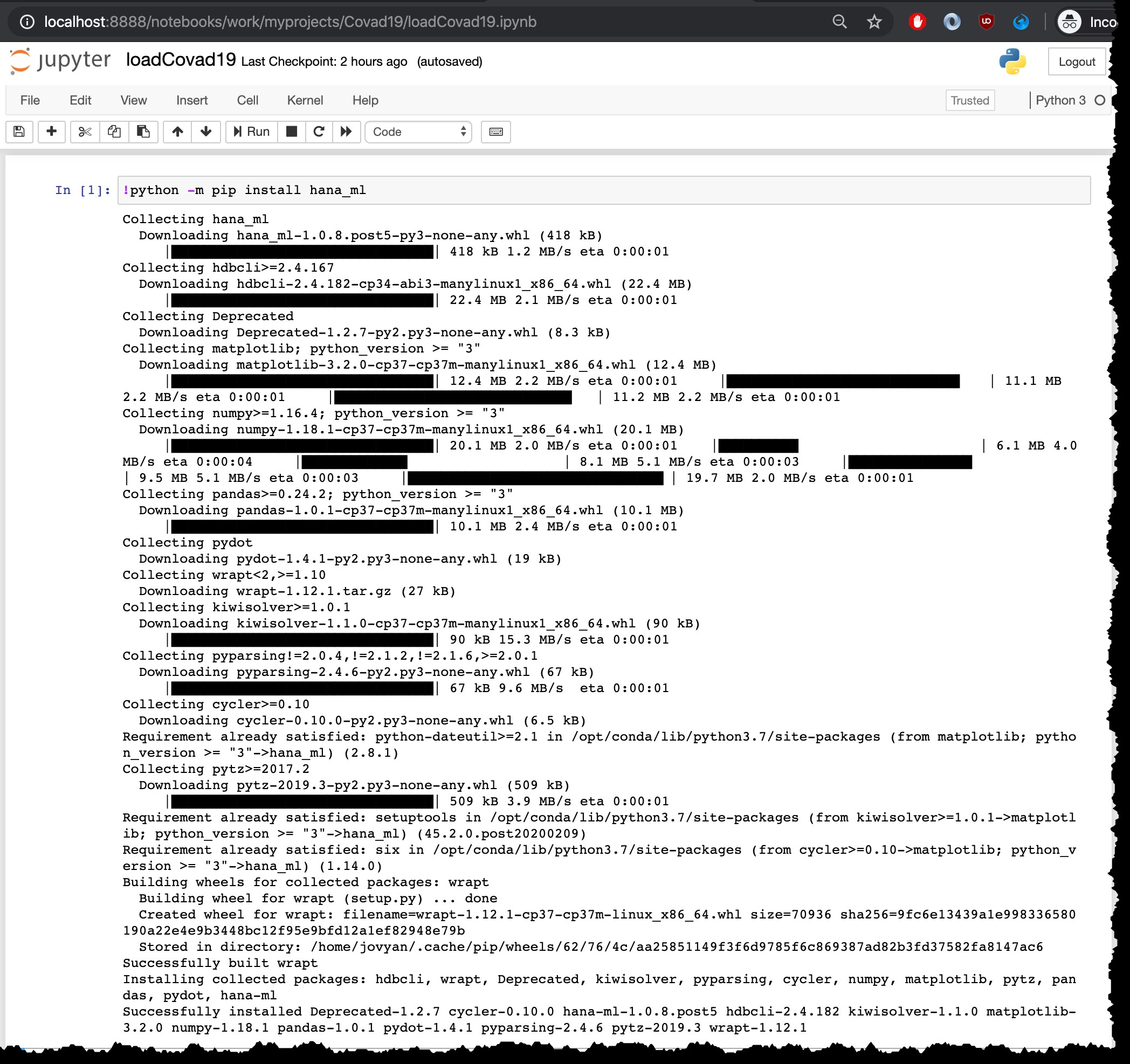
Évidemment, cette étape d'installation ne doit être effectuée qu'une seule fois. Pas besoin de le réexécuter dans le même conteneur, par ex. lors du rechargement des fichiers les plus récents.
Utilisez des pandas pour importer des fichiers avec des données
Importons les trois mêmes fichiers (confirmed , deaths , recovered ) de https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series comme Ferry utilisé dans son exemple.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
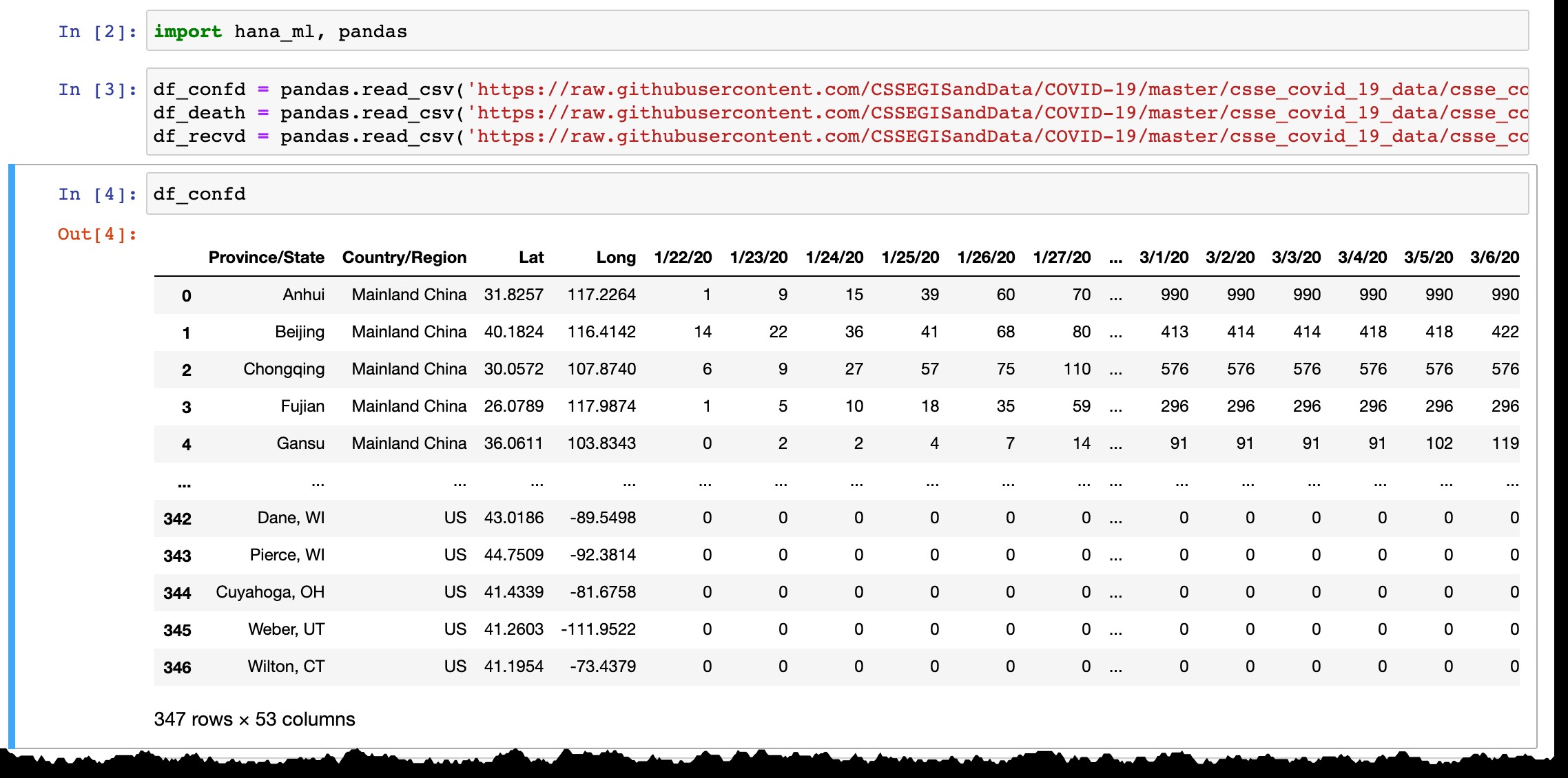
Comme vous pouvez le voir dans l'aperçu de la base de données Pandas, elle ne répertorie que les pays ou provinces avec des cas confirmés, et chaque jour, la nouvelle colonne est ajoutée avec les dernières données de la veille. Des lignes sont ajoutées lorsque le ou les premiers cas sont confirmés dans la nouvelle région.
Utilisez des pandas pour reformater la trame de données
Avant de conserver les données dans SAP HANA, procédons comme suit :
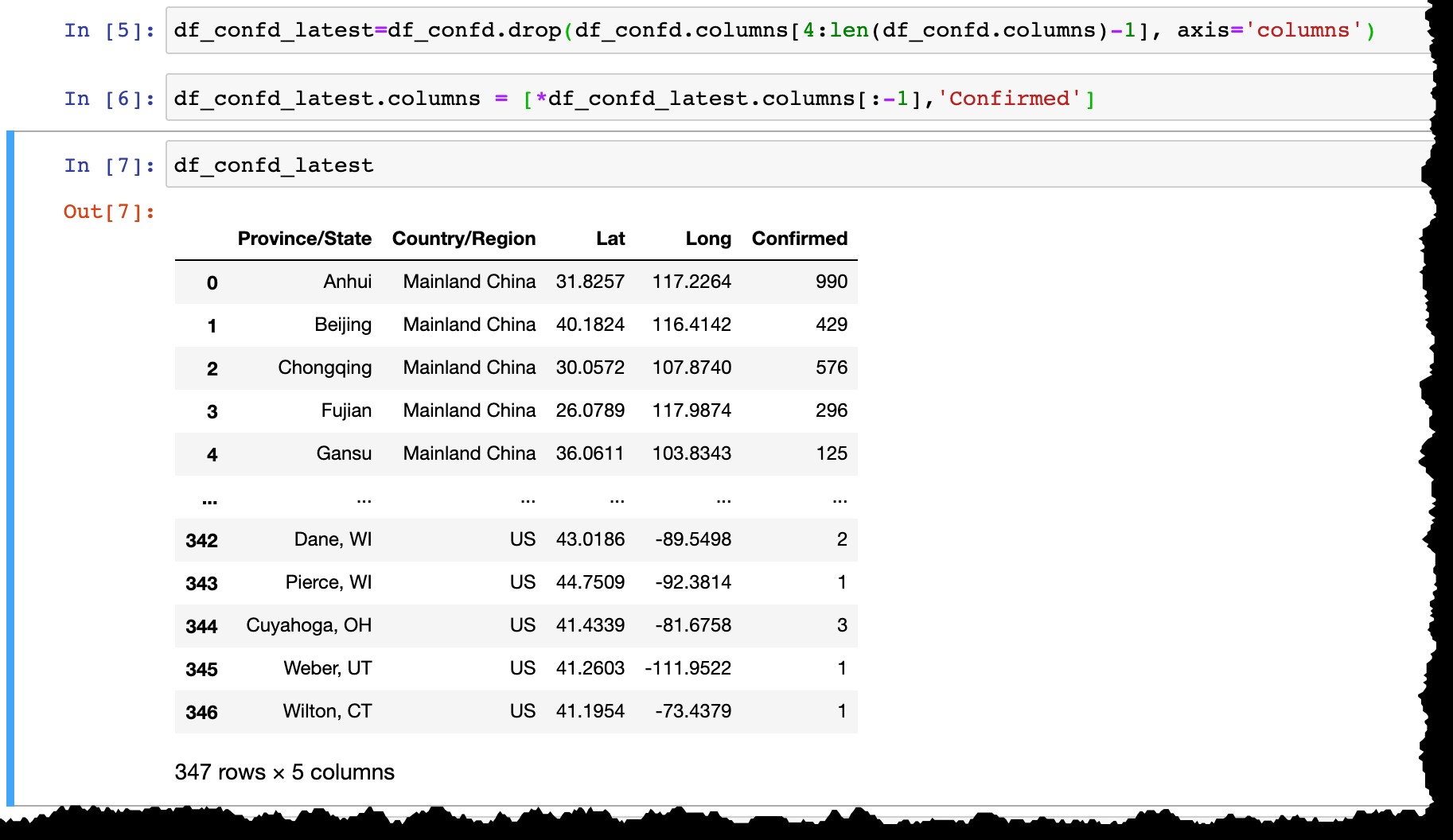
- Supprimez toutes les colonnes de date sauf la dernière,
- Renommer la dernière colonne à partir de la date réelle (comme aujourd'hui
3/10/20àConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Utilisez hana_ml pour conserver les données dans la table SAP HANA
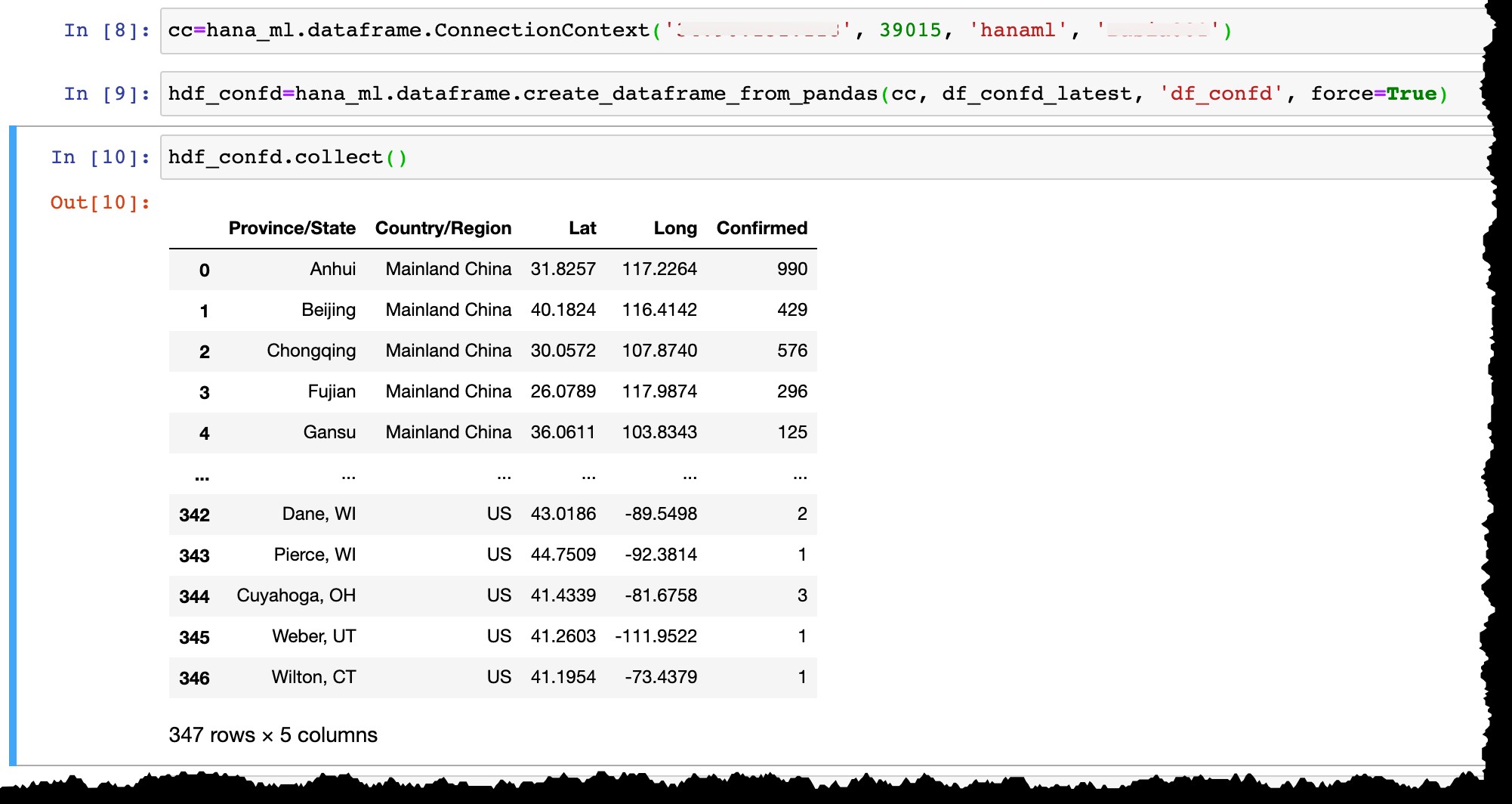
Maintenant, permettez-moi de me connecter à mon instance de SAP HANA Express avec l'utilisateur hanaml qui existe déjà là-bas…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…et convertir le dataframe Pandas df_confd_latest dans une trame de données HANA hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Une fois le dataframe HANA créé :
- Une table de colonnes physiques est créée dans HANA et les données du dataframe Pandas y sont insérées,
- Frame de données HANA
hdf_confden Python ne stocke aucune donnée dans votre ordinateur portable, mais pointe uniquement vers une tableHANAML.df_confddans la mémoire du serveur SAP HANA, et toutes les opérations Python sur la trame de données HANA sont exécutées physiquement dans la base de données HANA sans déplacer les données entre le serveur et un client, - Pour afficher le résultat de toute opération, nous devons appliquer
collect()méthode pour convertir la trame de données HANA en Pandas (et par conséquent pour amener les données du serveur de base de données HANA au client local).
Utilisez DBeaver pour vérifier les données dans SAP HANA…
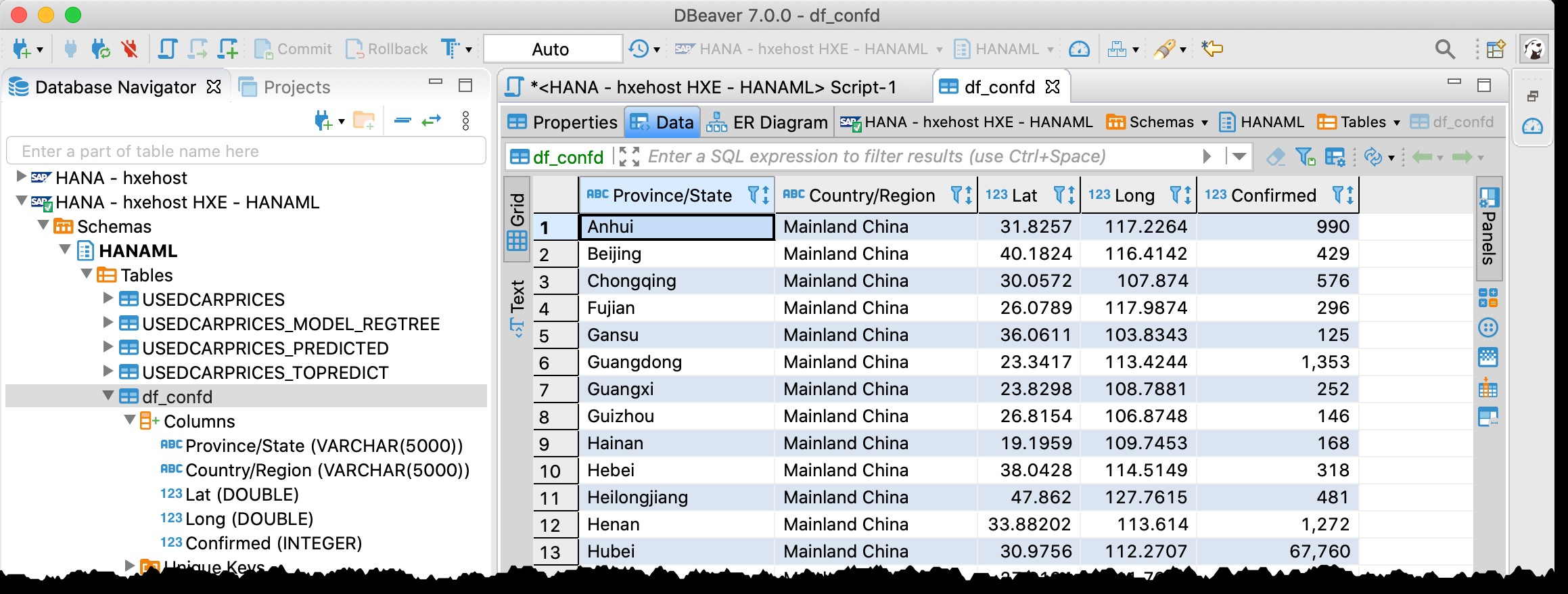
Vous vous souvenez peut-être que j'utilisais déjà DBeaver - l'outil de base de données gratuit prenant en charge SAP HANA - dans mon précédent article "GeoArt avec SAP HANA et DBeaver".
Je l'utilise à nouveau maintenant, et en effet je peux trouver la table df_confd dans le schéma HANAML avec toutes les données du dataframe source Pandas.
…et faire un aperçu spatial
Comme le tableau contient des colonnes de latitude et de longitude, je peux visualiser les pays/états concernés directement depuis DBeaver avec le SQL suivant en utilisant l'aperçu des données spatiales.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
J'avais besoin de changer la projection cartographique en EPSG:4326 pour obtenir ces points sur la carte. Et DBeaver me montre le reste des données d'enregistrement lorsque je clique sur n'importe quel point.
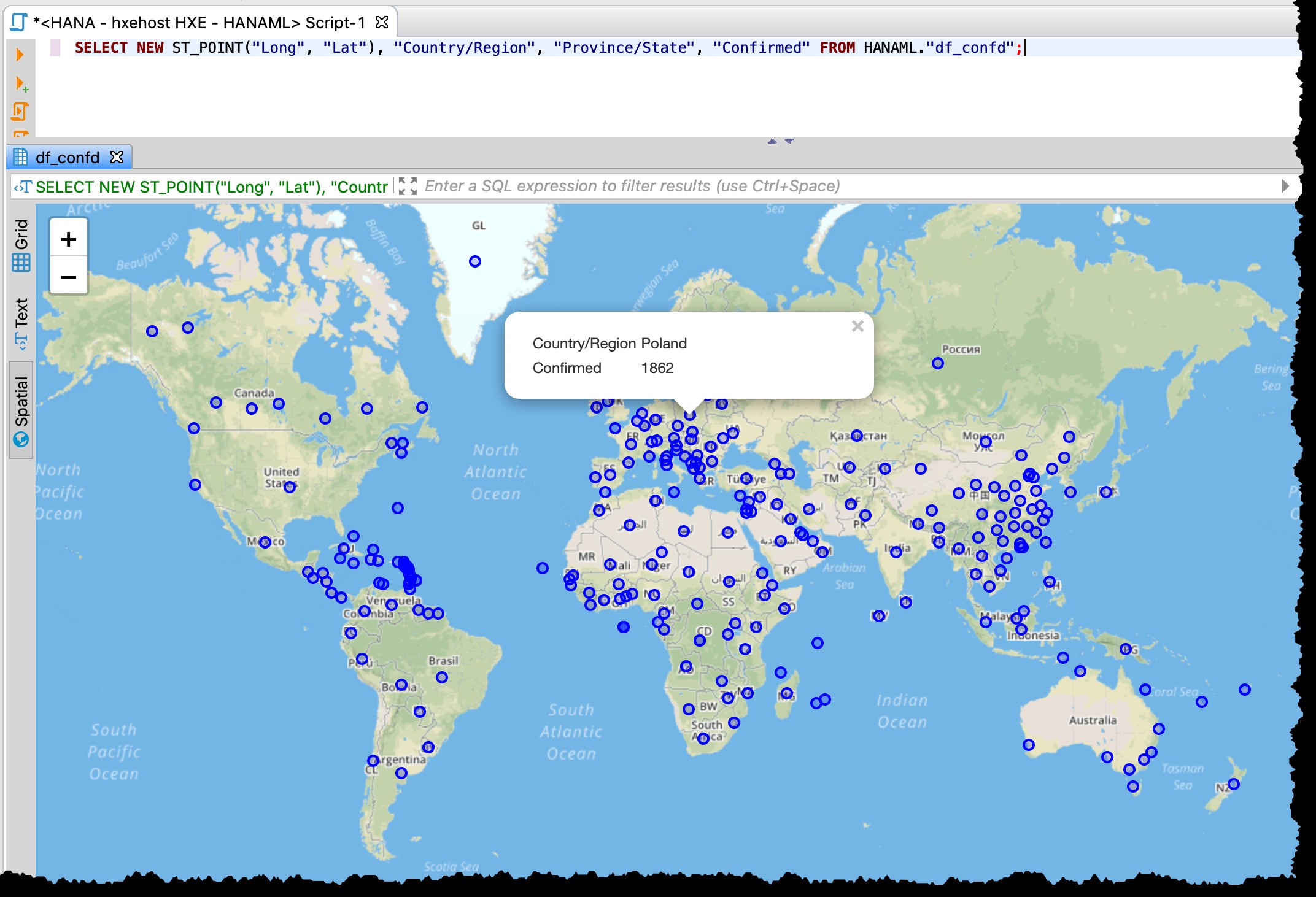
[Ci-dessous est l'ancienne capture d'écran du 11/03/2020, qui montre également la granularité différente, par exemple. Données américaines utilisées à l'époque]
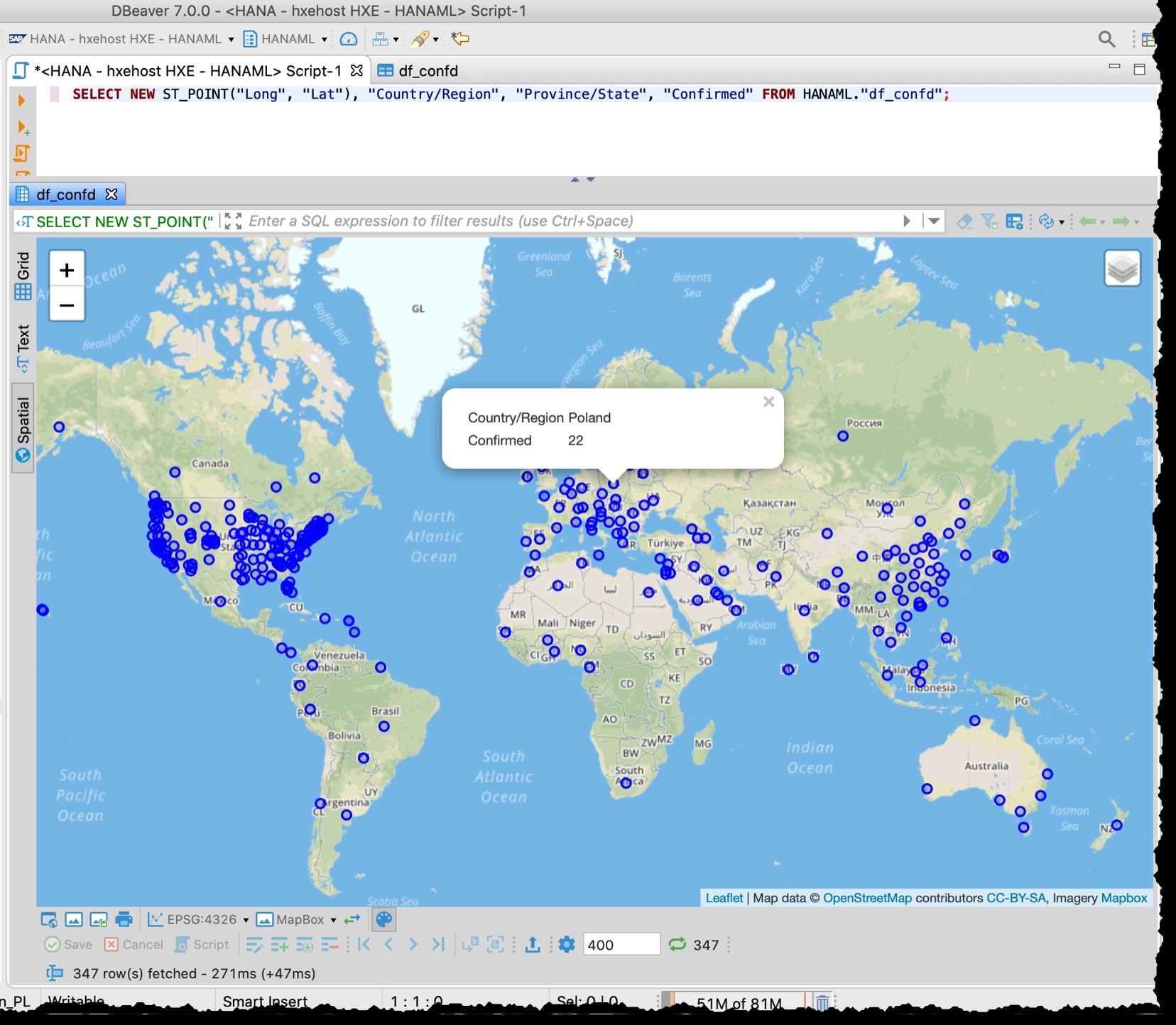
L'aperçu spatial DBeaver n'est pas un outil d'exploration visuelle géospatiale à part entière. Pourtant, c'est assez bon pour voir les pays/régions impactés (en fonction de la granularité dans les fichiers source).
Si vous souhaitez en savoir plus sur hana_ml …
… alors je recommanderais certainement de consulter le tutoriel pratique :Apprentissage automatique push-down vers SAP HANA avec Python par Andreas Forster.
HANA ML fait partie du nouveau sujet "Advanced Analytics with SAP HANA" pour les événements CodeJam. Malheureusement à cause de la situation du coronavirus, nous avons dû annuler le premier organisé par Jakob Flaman à Berne ce mois-ci. Un autre est organisé par Ewelina Pękała le 27 mai à Katowice :https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Espérons que la situation redeviendra normale à ce moment-là et que nous n'aurons pas besoin d'annuler celle-ci également.