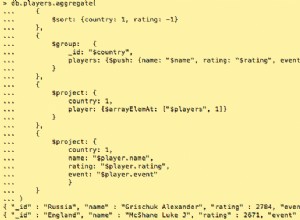
Vous devez faire quelques choses ici pour votre résultat final, mais les premières étapes sont relativement simples. Prenez l'objet utilisateur que vous fournissez :
var user = {
user_id : 1,
Friends : [3,5,6],
Artists : [
{artist_id: 10 , weight : 345},
{artist_id: 17 , weight : 378}
]
};
Maintenant, en supposant que vous avez déjà récupéré ces données, cela revient à trouver les mêmes structures pour chaque "ami" et à filtrer le contenu du tableau des "Artistes" en une seule liste distincte. Vraisemblablement, chaque "poids" sera également considéré au total ici.
Il s'agit d'une opération d'agrégation simple qui filtrera d'abord les artistes déjà présents dans la liste pour l'utilisateur donné :
var artists = user.Artists.map(function(artist) { return artist.artist_id });
User.aggregate(
[
// Find possible friends without all the same artists
{ "$match": {
"user_id": { "$in": user.Friends },
"Artists.artist_id": { "$nin": artists }
}},
// Pre-filter the artists already in the user list
{ "$project":
"Artists": {
"$setDifference": [
{ "$map": {
"input": "$Artists",
"as": "$el",
"in": {
"$cond": [
"$anyElementTrue": {
"$map": {
"input": artists,
"as": "artist",
"in": { "$eq": [ "$$artist", "$el.artist_id" ] }
}
},
false,
"$$el"
]
}
}}
[false]
]
}
}},
// Unwind the reduced array
{ "$unwind": "$Artists" },
// Group back by each artist and sum weights
{ "$group": {
"_id": "$Artists.artist_id",
"weight": { "$sum": "$Artists.weight" }
}},
// Sort the results by weight
{ "$sort": { "weight": -1 } }
],
function(err,results) {
// more to come here
}
);
Le "pré-filtre" est la seule partie vraiment délicate ici. Vous pouvez simplement $unwind
le tableau et $match
à nouveau pour filtrer les entrées que vous ne voulez pas. Même si nous voulons $unwind les résultats plus tard afin de les combiner, il est plus efficace de les supprimer du tableau "d'abord", donc il y a moins à développer.
Voici donc le $map
L'opérateur permet l'inspection de chaque élément du tableau "Artistes" de l'utilisateur et également une comparaison avec la liste filtrée des artistes "utilisateurs" pour simplement renvoyer les détails souhaités. Le $setDifference
est utilisé pour réellement "filtrer" tous les résultats qui n'ont pas été renvoyés comme contenu du tableau, mais plutôt renvoyés comme false .
Après cela, il n'y a que le $unwind pour dénormaliser le contenu dans le tableau et le $group
pour réunir un total par artiste. Pour le plaisir, nous utilisons $sort pour montrer que la liste est renvoyée dans l'ordre souhaité, mais cela ne sera pas nécessaire ultérieurement.
C'est au moins une partie du chemin ici car la liste résultante ne devrait être que d'autres artistes qui ne figurent pas déjà dans la propre liste de l'utilisateur, et triés par le "poids" additionné de tous les artistes qui pourraient éventuellement apparaître sur plusieurs amis.
La suite va avoir besoin des données de la collection "artistes" pour tenir compte du nombre d'auditeurs. Alors que la mangouste a un .populate() méthode, vous ne voulez vraiment pas cela ici car vous recherchez le nombre "d'utilisateurs distincts". Cela implique une autre implémentation d'agrégation afin d'obtenir ces décomptes distincts pour chaque artiste.
Suite à la liste des résultats de l'opération d'agrégation précédente, vous utiliseriez le $_id des valeurs comme ceci :
// First get just an array of artist id's
var artists = results.map(function(artist) {
return artist._id;
});
Artist.aggregate(
[
// Match artists
{ "$match": {
"artistID": { "$in": artists }
}},
// Project with weight for distinct users
{ "$project": {
"_id": "$artistID",
"weight": {
"$multiply": [
{ "$size": {
"$setUnion": [
{ "$map": {
"input": "$user_tag",
"as": "tag",
"in": "$$tag.user_id"
}},
[]
]
}},
10
]
}
}}
],
function(err,results) {
// more later
}
);
Ici, le tour est fait en agrégat avec $map pour effectuer une transformation similaire des valeurs qui est envoyée à $setUnion
pour en faire une liste unique. Puis le $size
L'opérateur est appliqué pour connaître la taille de cette liste. Le calcul supplémentaire consiste à donner à ce nombre une signification lorsqu'il est appliqué aux poids déjà enregistrés à partir des résultats précédents.
Bien sûr, vous devez rassembler tout cela d'une manière ou d'une autre, car pour le moment, il n'y a que deux ensembles de résultats distincts. Le processus de base est une "table de hachage", où les valeurs uniques d'identifiant "d'artiste" sont utilisées comme clé et les valeurs de "poids" sont combinées.
Vous pouvez le faire de plusieurs façons, mais comme il y a un désir de "trier" les résultats combinés, ma préférence serait quelque chose de "MongoDBish" car il suit les méthodes de base auxquelles vous devriez déjà être habitué.
Un moyen pratique d'implémenter cela consiste à utiliser nedb
, qui fournit un magasin "en mémoire" qui utilise en grande partie le même type de méthodes que celles utilisées pour lire et écrire dans les collections MongoDB.
Cela s'adapte également bien si vous deviez utiliser une collection réelle pour des résultats volumineux, car tous les principes restent les mêmes.
-
La première opération d'agrégation insère de nouvelles données dans le magasin
-
La deuxième agrégation "met à jour" ces données et incrémente le champ "poids"
En tant que liste complète des fonctions, et avec une autre aide du async
bibliothèque, cela ressemblerait à ceci :
function GetUserRecommendations(userId,callback) {
var async = require('async')
DataStore = require('nedb');
User.findOne({ "user_id": user_id},function(err,user) {
if (err) callback(err);
var artists = user.Artists.map(function(artist) {
return artist.artist_id;
});
async.waterfall(
[
function(callback) {
var pipeline = [
// Find possible friends without all the same artists
{ "$match": {
"user_id": { "$in": user.Friends },
"Artists.artist_id": { "$nin": artists }
}},
// Pre-filter the artists already in the user list
{ "$project":
"Artists": {
"$setDifference": [
{ "$map": {
"input": "$Artists",
"as": "$el",
"in": {
"$cond": [
"$anyElementTrue": {
"$map": {
"input": artists,
"as": "artist",
"in": { "$eq": [ "$$artist", "$el.artist_id" ] }
}
},
false,
"$$el"
]
}
}}
[false]
]
}
}},
// Unwind the reduced array
{ "$unwind": "$Artists" },
// Group back by each artist and sum weights
{ "$group": {
"_id": "$Artists.artist_id",
"weight": { "$sum": "$Artists.weight" }
}},
// Sort the results by weight
{ "$sort": { "weight": -1 } }
];
User.aggregate(pipeline, function(err,results) {
if (err) callback(err);
async.each(
results,
function(result,callback) {
result.artist_id = result._id;
delete result._id;
DataStore.insert(result,callback);
},
function(err)
callback(err,results);
}
);
});
},
function(results,callback) {
var artists = results.map(function(artist) {
return artist.artist_id; // note that we renamed this
});
var pipeline = [
// Match artists
{ "$match": {
"artistID": { "$in": artists }
}},
// Project with weight for distinct users
{ "$project": {
"_id": "$artistID",
"weight": {
"$multiply": [
{ "$size": {
"$setUnion": [
{ "$map": {
"input": "$user_tag",
"as": "tag",
"in": "$$tag.user_id"
}},
[]
]
}},
10
]
}
}}
];
Artist.aggregate(pipeline,function(err,results) {
if (err) callback(err);
async.each(
results,
function(result,callback) {
result.artist_id = result._id;
delete result._id;
DataStore.update(
{ "artist_id": result.artist_id },
{ "$inc": { "weight": result.weight } },
callback
);
},
function(err) {
callback(err);
}
);
});
}
],
function(err) {
if (err) callback(err); // callback with any errors
// else fetch the combined results and sort to callback
DataStore.find({}).sort({ "weight": -1 }).exec(callback);
}
);
});
}
Ainsi, après avoir mis en correspondance l'objet utilisateur source initial, les valeurs sont transmises à la première fonction d'agrégation, qui s'exécute en série et utilise async.waterfall pour passer son résultat.
Avant que cela ne se produise, les résultats de l'agrégation sont ajoutés au DataStore avec .insert() normal déclarations, en prenant soin de renommer le _id champs comme nedb n'aime rien d'autre que son propre _id auto-généré valeurs. Chaque résultat est inséré avec artist_id et weight propriétés du résultat de l'agrégation.
Cette liste est ensuite transmise à la deuxième opération d'agrégation qui va renvoyer chaque "artiste" spécifié avec un "poids" calculé en fonction de la taille de l'utilisateur distinct. Il y a les "updated" avec le même .update() déclaration sur le DataStore pour chaque artiste et en incrémentant le champ "poids".
Tout se passe bien, l'opération finale est de .find() ces résultats et .sort() par le "poids" combiné, et renvoyez simplement le résultat au rappel passé à la fonction.
Donc, vous l'utiliseriez comme ceci :
GetUserRecommendations(1,function(err,results) {
// results is the sorted list
});
Et il renverra tous les artistes qui ne figurent pas actuellement dans la liste de cet utilisateur mais dans leurs listes d'amis et classés par les poids combinés du nombre d'écoutes d'amis plus le score du nombre d'utilisateurs distincts de cet artiste.
C'est ainsi que vous traitez les données de deux collections différentes que vous devez combiner en un seul résultat avec divers détails agrégés. Il s'agit de plusieurs requêtes et d'un espace de travail, mais cela fait également partie de la philosophie de MongoDB selon laquelle de telles opérations sont mieux exécutées de cette façon que de les lancer dans la base de données pour "joindre" les résultats.