Puisque vous utilisez le ressort. Vous pouvez utiliser MultipartFile pour obtenir le fichier dans votre contrôleur, puis utilisez Binary de org.bson pour stocker le fichier dans MongoDB, si la taille de votre image <16 Mo (si la taille de l'image> 16 Mo, vous pouvez utiliser GridFs
).
Vous devez ajouter une seule dépendance à votre projet - spring-data-mongoDB
Prenons un exemple de collection User qui ressemble à ceci :
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Ici vous pouvez voir Binary image qui représente votre fichier image.
Créez maintenant un référentiel pour cette collection d'utilisateurs à l'aide de MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Créez un contrôleur à des fins de démonstration. Utiliser le fichier @RequestParam MultipartFile file pour obtenir le fichier sur votre contrôleur, récupérez les octets du fichier et définissez-le sur l'objet utilisateur user.setImage(new Binary(file.getBytes())); exemple complet ci-dessous :
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Démarrez le serveur et atteignez le point final comme indiqué dans la capture d'écran du facteur ci-dessous
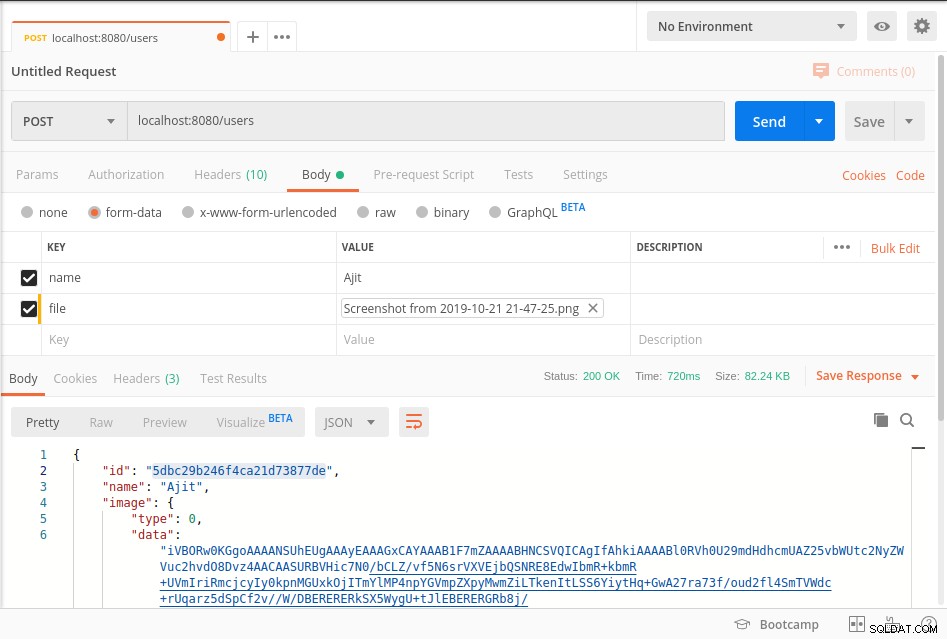
Vos données sont stockées dans mongoDb dans BinData format et pour obtenir les données de la base de données, veuillez vous référer à getImage méthode du code ci-dessus.
MODIF :
Le demandeur de la question utilise tess4j bibliothèque pour extraire le texte de l'image et doOCR est une méthode dans cette bibliothèque. J'ai suivi ces étapes pour extraire le texte de l'image dans mon application de démarrage de printemps.
-
Installez
tesseract-ocrdans votre système :sudo apt-get install tesseract-ocr -
Télécharger
eng.traineddatadonnées d'entraînement de https://github.com/tesseract-ocr/tessdata et déplacez-le vers le dossier racine du projet. -
Ajoutez la dépendance ci-dessous à votre projet :
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Ajoutez le code ci-dessous au projet existant :
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}



