Où stockons-nous les images ?
Solution n° 1 dans MongoDB
La première solution consiste donc à stocker les images dans MongoDB. Il peut accueillir des fichiers image ou tout type de fichier. Ainsi, vous pouvez prendre un fichier et le lier à un enregistrement à l'intérieur de MongoDB et l'enregistrer directement dans votre base de données.
Avec cette approche, lier une page de description d'un vêtement particulier avec son image correspondante devient facile car vous pouvez intégrer cette image directement dans votre développement de cette page et votre client serait satisfait de cette approche car lorsque l'utilisateur récupère une description détaillée page de ce vêtement, il est livré avec l'image.
C'est donc une solution possible, il suffit de prendre l'image et de la stocker directement dans MongoDB.
Cependant, je vais suggérer que c'est une mauvaise approche. La raison en est que vous pouvez dire à votre client s'il y a un refoulement, c'est qu'il paiera généralement pour son instance Mongo en fonction de la quantité de stockage utilisée par sa copie Mongo.
Ainsi, plus ils utilisent d'espace de stockage, plus ils paient d'argent par mois.
Par exemple, la dernière fois que j'ai vérifié l'utilisation de MLab, ils facturaient 15 $ par Go. Cela représente donc 15 $ de la poche de vos clients pour l'hébergement de 1 Go d'images.
Pour un énième site e-commerce, on parle de 3GB easy ce qui se traduit par 330 images à peu près, soit 15$ par mois.
Donc, si l'un de leurs chefs de projet met en ligne un nouveau vêtement une fois par jour, on parle très rapidement d'un coût énorme.
Donc, personnellement, je pense que stocker n'importe quel type de fichier directement dans MongoDB n'est vraiment pas une option car cela deviendra très coûteux.
Ce n'est donc qu'une solution possible.
Solution n° 2 en HD attachée au serveur
Examinons donc une deuxième solution qui pourrait s'offrir à vous. Vous pouvez utiliser un disque dur lié à votre serveur Express. Ainsi, lorsque cette application est déployée dans un environnement cloud comme Heroku, Digital Ocean, Linode ou AWS, vous obtenez généralement un disque dur associé à votre application.
Alors peut-être que vous prenez les images et que vous les placez sur le disque dur local. C'est cette approche que préconisent la grande majorité des publications et articles en ligne :
Comment pour télécharger, afficher et enregistrer des images en utilisant node.js et express
https://appdividend. com/2019/02/14/node-express-image-upload-and-resize-tutorial-example/
https://medium.com/@nitinpatel_20236/image-upload -via-nodejs-server-3fe7d3faa642
Juste avec les trois que j'ai rassemblés ci-dessus, vous avez un plan assez robuste pour commencer.
Tout le monde dit de prendre le fichier et de l'enregistrer sur votre disque dur local. Dans cet article particulier :
https://alligator.io/nodejs/uploading-files-multer-express/
ils affichent ce code :
const storage = multer.diskStorage({
destination: 'some-destination',
filename: function (req, file, callback) {
//..
}
});
Ils utilisent la bibliothèque de téléchargement d'images appelée multer qui fournit le diskStorage() moteur de téléchargement d'images sur disque.
C'est donc une approche avec laquelle la communauté du développement dans son ensemble est d'accord.
Il s'agit d'une bonne approche dans le contexte d'un mappage un à un.
Les problèmes avec cette approche commencent à se poser lorsque nous avons plusieurs machines.
Un exemple de ceci est si vous avez plusieurs machines hébergées sur Digital Ocean ou Linode où chaque environnement est une instance distincte.
Si vous avez toutes vos images stockées sur le disque dur fourni et que vous commencez ensuite à faire évoluer votre serveur, elles auront chacune leur propre disque dur séparé.
Ainsi, vous pouvez avoir une demande qui arrive via un équilibreur de charge et l'équilibreur de charge décide où envoyer la demande comme le schéma ci-dessous :
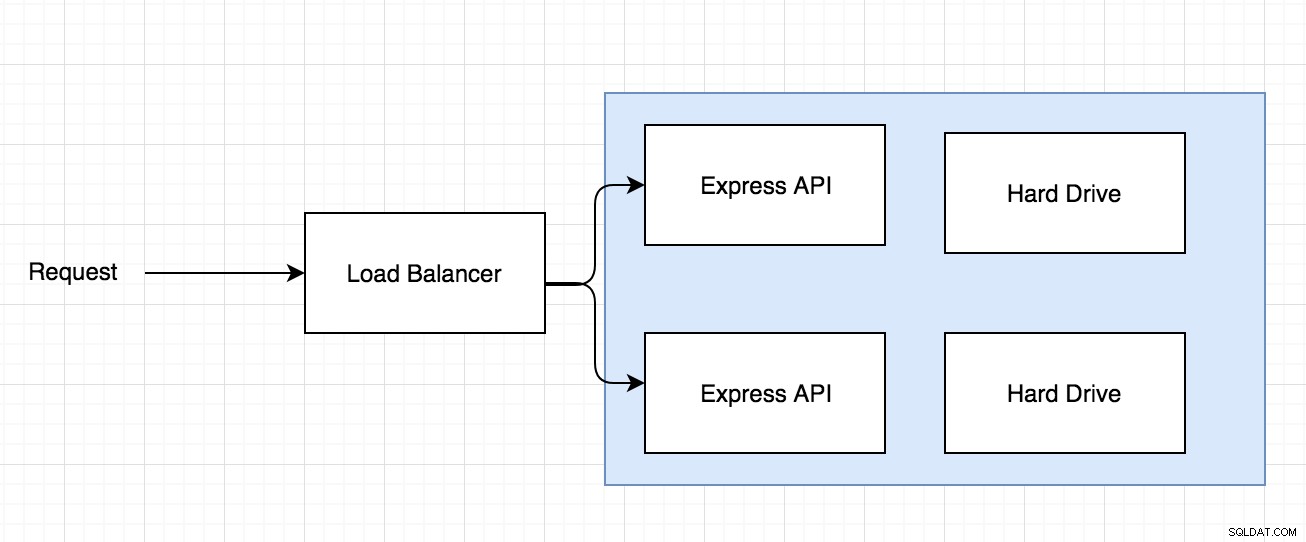
Donc, le problème avec l'architecture ci-dessus est si l'image est enregistrée sur l'un des deux disques durs, puis plus tard, une demande arrive pour accéder à cette même image, mais imaginez que la demande soit acheminée vers l'autre serveur Express avec un disque dur différent où l'image n'existe pas.
C'est un problème qui survient lorsque vous commencez à utiliser un fournisseur de services comme Linode ou Digital Ocean où vous avez un mappage un à un entre le serveur et le disque dur.
C'est une solution à court terme si c'est tout ce dont vous avez besoin pour le moment, mais une fois que cette application commencera à évoluer, cela deviendra un problème.
Solution n° 3 hors magasin de données
Cette troisième solution est celle que j'ai utilisée dans le passé avec les applications React with Node et les applications Ruby on Rails également. En fait, mon site Web de portefeuille Ruby on Rails utilise cette solution et repose sur la plate-forme Heroku.
Ainsi, lorsque l'image est téléchargée, plutôt que l'API Express essaie de stocker le fichier localement comme sur son propre disque dur, elle prend l'image et utilise un magasin de données externe pour stocker toutes les différentes images de l'application.
Celui que j'utilise pour mon site Web de portefeuille et ce que j'ai utilisé pour les applications Node with React a été Amazon S3, mais il existe également Azure File Storage et Google Cloud Storage. Ces systèmes sont conçus pour contenir une énorme quantité de données et il peut s'agir de n'importe quel type de fichier que vous pouvez imaginer. Pas seulement des images comme dans votre cas, mais des fichiers vidéo, des fichiers audio, etc.
Il n'y a pas de limite à la quantité de stockage que vous pouvez avoir avec S3, mais vous n'êtes pas obligé d'utiliser S3, mais il est actuellement considéré comme une norme de l'industrie, mais vous pouvez tout aussi bien utiliser Azure et Google Cloud.
L'avantage de cette solution que je pense que votre client appréciera, c'est qu'Amazon S3 vous facture environ deux centimes par gigaoctet et par mois pour le stockage.



