TL;DR :mongoengine passe des années à convertir tous les tableaux renvoyés en dicts
Pour tester cela, j'ai construit une collection avec un document avec un DictField avec un grand dict imbriqué . Le doc étant à peu près dans votre gamme de 5 à 10 Mo.
Nous pouvons alors utiliser timeit.timeit
pour confirmer la différence de lectures en utilisant pymongo et mongoengine.
Nous pouvons alors utiliser pycallgraph et GraphViz pour voir ce qui prend mongoengine si longtemps.
Voici le code en entier :
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
Et la sortie prouve que mongoengine est très lent par rapport à pymongo :
pymongo took 0.87s
mongoengine took 25.81118331072267
Le graphique des appels qui en résulte illustre assez clairement où se situe le goulot d'étranglement :
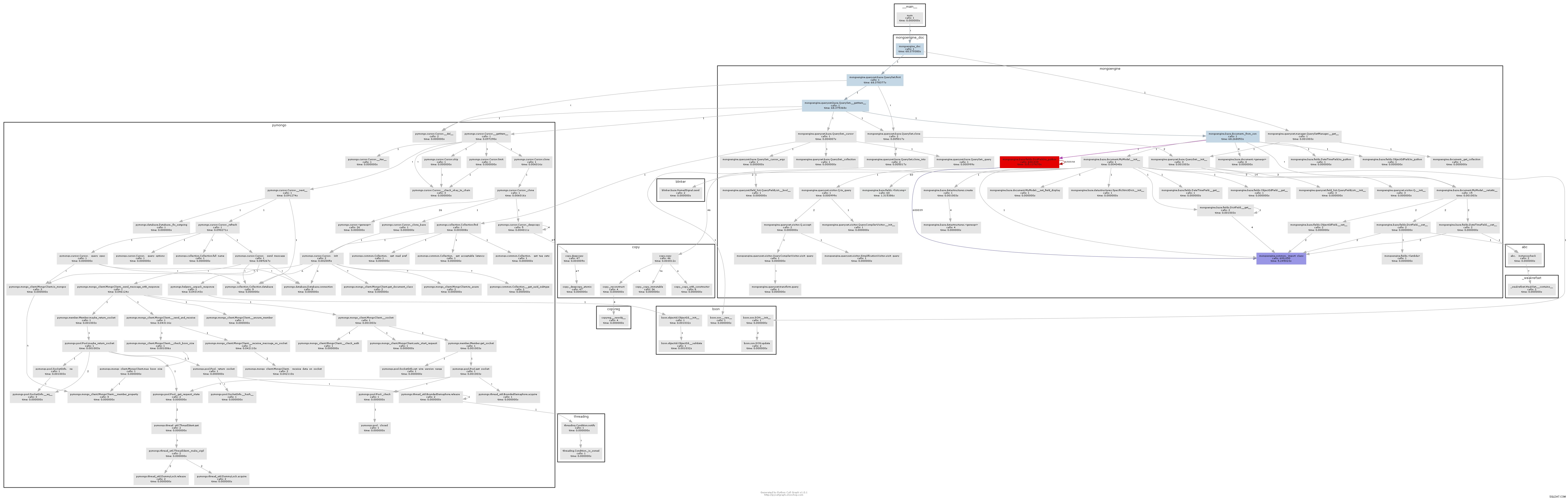
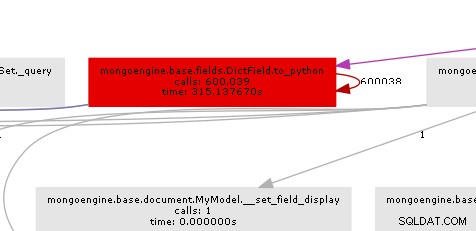
Essentiellement, mongoengine appellera la méthode to_python sur chaque DictField qu'il revient de la base de données. to_python est assez lent et dans notre exemple, il est appelé un nombre insensé de fois.
Mongoengine est utilisé pour mapper élégamment la structure de votre document sur des objets python. Si vous avez de très gros documents non structurés (pour lesquels mongodb est idéal), mongoengine n'est pas vraiment le bon outil et vous devez simplement utiliser pymongo.
Cependant, si vous connaissez la structure, vous pouvez utiliser EmbeddedDocument champs pour obtenir des performances légèrement meilleures de mongoengine. J'ai exécuté un test similaire mais non équivalent code dans cet essentiel
et le résultat est :
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
Vous pouvez donc rendre mongoengine plus rapide, mais pymongo est encore beaucoup plus rapide.
MISE À JOUR
Un bon raccourci vers l'interface pymongo consiste à utiliser le framework d'agrégation :
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]



