MongoDB est une base de données NoSQL qui prend en charge une grande variété de sources d'ensembles de données d'entrée. Il est capable de stocker des données dans des documents flexibles de type JSON, ce qui signifie que les champs ou les métadonnées peuvent varier d'un document à l'autre et que la structure des données peut être modifiée au fil du temps. Le modèle de document facilite l'utilisation des données en les mappant aux objets du code d'application. MongoDB est également connu comme une base de données distribuée à la base, de sorte que la haute disponibilité, la mise à l'échelle horizontale et la distribution géographique sont intégrées et faciles à utiliser. Il est livré avec la possibilité de modifier de manière transparente les paramètres de formation du modèle. Les Data Scientists peuvent facilement fusionner la structuration des données avec cette génération de modèles.
Qu'est-ce que l'apprentissage automatique ?
L'apprentissage automatique est la science qui permet aux ordinateurs d'apprendre et d'agir comme les humains et d'améliorer leur apprentissage au fil du temps de manière autonome. Le processus d'apprentissage commence par des observations ou des données, telles que des exemples, une expérience directe ou des instructions, afin de rechercher des modèles dans les données et de prendre de meilleures décisions à l'avenir sur la base des exemples que nous fournissons. L'objectif principal est de permettre aux ordinateurs d'apprendre automatiquement sans intervention ou assistance humaine et d'ajuster les actions en conséquence.
Un modèle de programmation et de requête riche
MongoDB propose à la fois des pilotes natifs et des connecteurs certifiés pour les développeurs et les data scientists qui créent des modèles d'apprentissage automatique avec les données de MongoDB. PyMongo est une excellente bibliothèque pour intégrer la syntaxe MongoDB dans le code Python. Nous pouvons importer toutes les fonctions et méthodes de MongoDB pour les utiliser dans notre code d'apprentissage automatique. C'est une excellente technique pour obtenir des fonctionnalités multilingues dans un seul code. L'avantage supplémentaire est que vous pouvez utiliser les fonctionnalités essentielles de ces langages de programmation pour créer une application efficace.
Le langage de requête MongoDB avec des index secondaires riches permet aux développeurs de créer des applications capables d'interroger et d'analyser les données dans plusieurs dimensions. Les données sont accessibles par clés uniques, plages, recherche de texte, graphique et requêtes géospatiales via des agrégations complexes et des tâches MapReduce, renvoyant des réponses en quelques millisecondes.
Pour paralléliser le traitement des données sur un cluster de bases de données distribuées, MongoDB fournit le pipeline d'agrégation et MapReduce. Le pipeline d'agrégation MongoDB est modélisé selon le concept de pipelines de traitement de données. Les documents entrent dans un pipeline à plusieurs étapes qui transforme les documents en un résultat agrégé à l'aide d'opérations natives exécutées dans MongoDB. Les étapes de pipeline les plus élémentaires fournissent des filtres qui fonctionnent comme des requêtes et des transformations de document qui modifient la forme du document de sortie. D'autres opérations de pipeline fournissent des outils pour regrouper et trier des documents par champs spécifiques ainsi que des outils pour agréger le contenu de tableaux, y compris des tableaux de documents. En outre, les étapes pipseline peuvent utiliser des opérateurs pour des tâches telles que le calcul de la moyenne ou des écarts-types entre des collections de documents et la manipulation de chaînes. MongoDB fournit également des opérations MapReduce natives dans la base de données, en utilisant des fonctions JavaScript personnalisées pour effectuer la carte et réduire les étapes.
En plus de son cadre de requête natif, MongoDB propose également un connecteur hautes performances pour Apache Spark. Le connecteur expose toutes les bibliothèques de Spark, y compris Python, R, Scala et Java. Les données MongoDB sont matérialisées sous forme de DataFrames et d'ensembles de données pour analyse avec l'apprentissage automatique, les graphiques, le streaming et les API SQL.
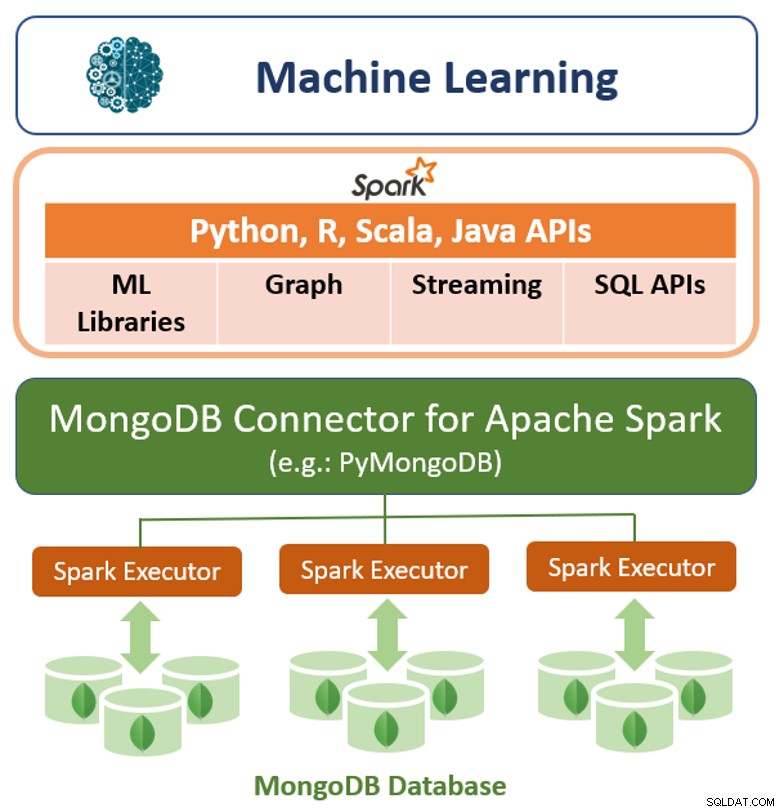
Le connecteur MongoDB pour Apache Spark peut tirer parti du pipeline d'agrégation de MongoDB et des des index pour extraire, filtrer et traiter uniquement la gamme de données dont il a besoin - par exemple, analyser tous les clients situés dans une zone géographique spécifique. Ceci est très différent des magasins de données NoSQL simples qui ne prennent en charge ni les index secondaires ni les agrégations de base de données. Dans ces cas, Spark devrait extraire toutes les données basées sur une simple clé primaire, même si seul un sous-ensemble de ces données est requis pour le processus Spark. Cela signifie plus de temps de traitement, plus de matériel et plus de temps pour obtenir des informations pour les scientifiques et les ingénieurs des données. Pour optimiser les performances sur de grands ensembles de données distribués, le connecteur MongoDB pour Apache Spark peut colocaliser des ensembles de données distribués résilients (RDD) avec le nœud MongoDB source, minimisant ainsi le mouvement des données dans le cluster et réduisant la latence.
Performances, évolutivité et redondance
Le temps de formation du modèle peut être réduit en créant la plate-forme d'apprentissage automatique au-dessus d'une couche de base de données performante et évolutive. MongoDB propose un certain nombre d'innovations pour maximiser le débit et minimiser la latence des charges de travail de machine learning :
- WiredTiger est connu comme le moteur de stockage par défaut pour MongoDB, développé par les architectes de Berkeley DB, le logiciel de gestion de données embarqué le plus largement déployé au monde. WiredTiger s'adapte aux architectures multicœurs modernes. En utilisant une variété de techniques de programmation telles que les pointeurs de danger, les algorithmes sans verrouillage, le verrouillage rapide et la transmission de messages, WiredTiger maximise le travail de calcul par cœur de processeur et cycle d'horloge. Pour minimiser la surcharge et les E/S sur le disque, WiredTiger utilise des formats de fichiers compacts et une compression de stockage.
- Pour les applications d'apprentissage automatique les plus sensibles à la latence, MongoDB peut être configuré avec le moteur de stockage en mémoire. Basé sur WiredTiger, ce moteur de stockage offre aux utilisateurs les avantages de l'informatique en mémoire, sans sacrifier la grande flexibilité des requêtes, l'analyse en temps réel et la capacité évolutive offertes par les bases de données classiques sur disque.
- Pour paralléliser la formation de modèles et mettre à l'échelle les ensembles de données d'entrée au-delà d'un seul nœud, MongoDB utilise une technique appelée sharding, qui distribue le traitement et les données sur des clusters de matériel de base. Le partitionnement MongoDB est entièrement élastique, rééquilibrant automatiquement les données dans le cluster à mesure que l'ensemble de données d'entrée augmente ou que des nœuds sont ajoutés et supprimés.
- Au sein d'un cluster MongoDB, les données de chaque partition sont automatiquement distribuées à plusieurs répliques hébergées sur des nœuds distincts. Les jeux d'instances dupliquées MongoDB fournissent une redondance pour récupérer les données de formation en cas de panne, ce qui réduit la surcharge des points de contrôle.
La cohérence ajustable de MongoDB
MongoDB est fortement cohérent par défaut, permettant aux applications d'apprentissage automatique de lire immédiatement ce qui a été écrit dans la base de données, évitant ainsi la complexité imposée aux développeurs par des systèmes cohérents à terme. Une cohérence forte fournira les résultats les plus précis pour les algorithmes d'apprentissage automatique ; cependant, dans certains scénarios, il est acceptable d'échanger la cohérence contre des objectifs de performances spécifiques en répartissant les requêtes sur un cluster de membres du jeu de réplicas secondaires MongoDB.
Modèle de données flexible dans MongoDB
Le modèle de données de document de MongoDB permet aux développeurs et aux spécialistes des données de stocker et d'agréger facilement des données de toute forme de structure à l'intérieur de la base de données, sans renoncer à des règles de validation sophistiquées pour régir la qualité des données. Le schéma peut être modifié dynamiquement sans interruption de l'application ou de la base de données résultant de modifications de schéma coûteuses ou d'une refonte encourue par les systèmes de base de données relationnelles.
Enregistrer des modèles dans une base de données et les charger à l'aide de python est également une méthode simple et indispensable. Choisir MongoDB est également un avantage car il s'agit d'une base de données de documents open source et également d'une base de données NoSQL de premier plan. MongoDB sert également de connecteur pour le framework distribué apache spark.
La nature dynamique de MongoDB
La nature dynamique de MongoDB permet son utilisation dans les tâches de manipulation de base de données dans le développement d'applications d'apprentissage automatique. C'est un moyen très efficace et facile d'effectuer une analyse d'ensembles de données et de bases de données. Le résultat de l'analyse peut être utilisé dans la formation de modèles d'apprentissage automatique. Il a été recommandé aux analystes de données et aux programmeurs d'apprentissage automatique de maîtriser MongoDB et de l'appliquer dans de nombreuses applications différentes. Le cadre d'agrégation de MongoDB est utilisé pour le workflow de science des données afin d'effectuer des analyses de données pour de nombreuses applications.
Conclusion
MongoDB offre plusieurs fonctionnalités différentes telles que :un modèle de données flexible, une programmation riche, un modèle de données, un modèle de requête et sa cohérence ajustable qui rendent la formation et l'utilisation d'algorithmes d'apprentissage automatique beaucoup plus faciles qu'avec les bases de données relationnelles traditionnelles. L'exécution de MongoDB en tant que base de données principale permettra de stocker et d'enrichir les données d'apprentissage automatique pour une persistance et une efficacité accrue.



