Les arrêts de production sont presque garantis à un moment donné. Accepter ce fait et analyser la chronologie et le scénario d'échec de votre panne de base de données peut aider à mieux préparer, diagnostiquer et récupérer de la prochaine. Pour atténuer l'impact des temps d'arrêt, les entreprises ont besoin d'un plan de reprise après sinistre (DR) approprié. La planification DR est une tâche critique pour de nombreux SysOps/DevOps, mais même si elle est prévue; souvent il n'existe pas.
Dans cet article de blog, nous analyserons différents scénarios de sauvegarde et d'échec dans les systèmes de base de données MongoDB. Nous vous guiderons également à travers les procédures de récupération et de basculement pour chaque scénario respectif. Ces cas d'utilisation varieront de la restauration d'un nœud unique à la restauration d'un nœud dans un replicaSet existant et à l'amorçage d'un nouveau nœud dans un replicaSet. J'espère que cela vous permettra de bien comprendre les risques auxquels vous pourriez être confronté et ce qu'il faut prendre en compte lors de la conception de votre infrastructure.
Avant de commencer à discuter des scénarios d'échec possibles, examinons comment MongoDB stocke les données et quels types de sauvegarde sont disponibles.
Comment MongoDB stocke les données
MongoDB est une base de données orientée document. Au lieu de stocker vos données dans des tables constituées de lignes individuelles (comme le fait une base de données relationnelle), elle stocke les données dans des collections constituées de documents individuels. Dans MongoDB, un document est un gros blob JSON sans format ni schéma particulier. De plus, les données peuvent être réparties sur différents nœuds de cluster avec partage ou répliquées sur des serveurs esclaves avec replicaSet.
MongoDB permet des écritures et des mises à jour très rapides par défaut. Le compromis est que souvent vous n'êtes pas explicitement informé des échecs. Par défaut, la plupart des pilotes effectuent des écritures asynchrones et non sécurisées. Cela signifie que le pilote ne renvoie pas directement une erreur, similaire à INSERT DELAYED avec MySQL. Si vous voulez savoir si quelque chose a réussi, vous devez vérifier manuellement les erreurs à l'aide de getLastError.
Pour des performances optimales, il est préférable d'utiliser un SSD plutôt qu'un HDD pour le stockage. Il est nécessaire de prendre soin de savoir si votre stockage est local ou distant et de prendre des mesures en conséquence. Il est préférable d'utiliser RAID pour la protection contre les défauts matériels et les schémas de récupération, mais ne vous y fiez pas entièrement car il n'offre pas de protection contre les défaillances indésirables. Le bon matériel est la pierre angulaire de votre application pour optimiser les performances et éviter une débâcle majeure.
La corruption des données au niveau du disque ou des fichiers de données manquants peuvent empêcher le démarrage des instances mongod, et les fichiers journaux peuvent être insuffisants pour une récupération automatique.
Si vous exécutez avec la journalisation activée, il n'est presque jamais nécessaire d'exécuter une réparation puisque le serveur peut utiliser les fichiers journaux pour restaurer automatiquement les fichiers de données dans un état propre. Cependant, vous devrez peut-être toujours exécuter une réparation dans les cas où vous devez récupérer des données corrompues au niveau du disque.
Si la journalisation n'est pas activée, votre seule option peut être d'exécuter la commande de réparation. mongod --repair ne doit être utilisé que si vous n'avez pas d'autres options car l'opération supprime (et n'enregistre pas) les données corrompues pendant le processus de réparation. Ce type d'opération doit toujours être précédé d'une sauvegarde.
Scénario de reprise après sinistre MongoDB
Dans un plan de récupération après défaillance, votre objectif de point de récupération (RPO) est un paramètre de récupération clé qui dicte la quantité de données que vous pouvez vous permettre de perdre. Le RPO est répertorié dans le temps, de quelques millisecondes à plusieurs jours et dépend directement de votre système de sauvegarde. Il prend en compte l'âge de vos données de sauvegarde que vous devez récupérer afin de reprendre les opérations normales.
Pour estimer le RPO, vous devez vous poser quelques questions. Quand mes données sont-elles sauvegardées ? Quel est le SLA associé à la récupération des données ? La restauration d'une sauvegarde des données est-elle acceptable ou les données doivent-elles être en ligne et prêtes à être interrogées à tout moment ?
Les réponses à ces questions vous aideront à choisir le type de solution de sauvegarde dont vous avez besoin.
Solutions de sauvegarde MongoDB
Les techniques de sauvegarde ont des impacts variables sur les performances de la base de données en cours d'exécution. Certaines solutions de sauvegarde dégradent suffisamment les performances de la base de données pour que vous deviez planifier des sauvegardes afin d'éviter les pics d'utilisation ou les fenêtres de maintenance. Vous pouvez décider de déployer de nouveaux serveurs secondaires uniquement pour prendre en charge les sauvegardes.
Les trois solutions les plus courantes pour sauvegarder votre serveur/cluster MongoDB sont...
- Mongodump/Mongorestore - sauvegarde logique.
- Mongo Management System (Cloud) :les bases de données de production peuvent être sauvegardées à l'aide de MongoDB Ops Manager ou, si vous utilisez le service MongoDB Atlas, vous pouvez utiliser une solution de sauvegarde entièrement gérée.
- Instantanés de base de données (sauvegarde au niveau du disque)
Mongodump/Mongorestore
Lors de l'exécution d'un mongodump, toutes les collections des bases de données désignées seront vidées en tant que sortie BSON. Si aucune base de données n'est spécifiée, MongoDB videra toutes les bases de données à l'exception des bases de données d'administration, de test et locales car elles sont réservées à un usage interne.
Par défaut, mongodump créera un répertoire appelé dump, avec un répertoire pour chaque base de données contenant un fichier BSON par collection dans cette base de données. Alternativement, vous pouvez dire à mongodump de stocker la sauvegarde dans un seul fichier d'archive. Le paramètre archive concaténera la sortie de toutes les bases de données et collections en un seul flux de données binaires. De plus, le paramètre gzip peut naturellement compresser cette archive à l'aide de gzip. Dans ClusterControl, nous diffusons toutes nos sauvegardes, nous activons donc les paramètres archive et gzip.
Similaire à mysqldump avec MySQL, si vous créez une sauvegarde dans MongoDB, cela gèlera les collections tout en vidant le contenu dans le fichier de sauvegarde. Comme MongoDB ne prend pas en charge les transactions (modifié en 4.2), vous ne pouvez pas effectuer une sauvegarde entièrement cohérente à 100 % à moins de créer la sauvegarde avec le paramètre oplog. L'activer sur la sauvegarde inclut les transactions de l'oplog qui s'exécutaient lors de la sauvegarde.
Pour une meilleure automatisation et Vous pouvez exécuter MongoDB à partir de la ligne de commande ou utiliser des outils externes comme ClusterControl. ClusterControl est l'option recommandée pour la gestion et l'automatisation des sauvegardes, car elle permet de créer des stratégies de sauvegarde avancées pour divers systèmes de bases de données open source.
ClusterControl vous permet de télécharger votre sauvegarde sur le cloud. Il prend en charge la sauvegarde complète et restaure le cryptage de mongodump. Si vous voulez voir comment cela fonctionne, il y a une démo sur notre site Web.
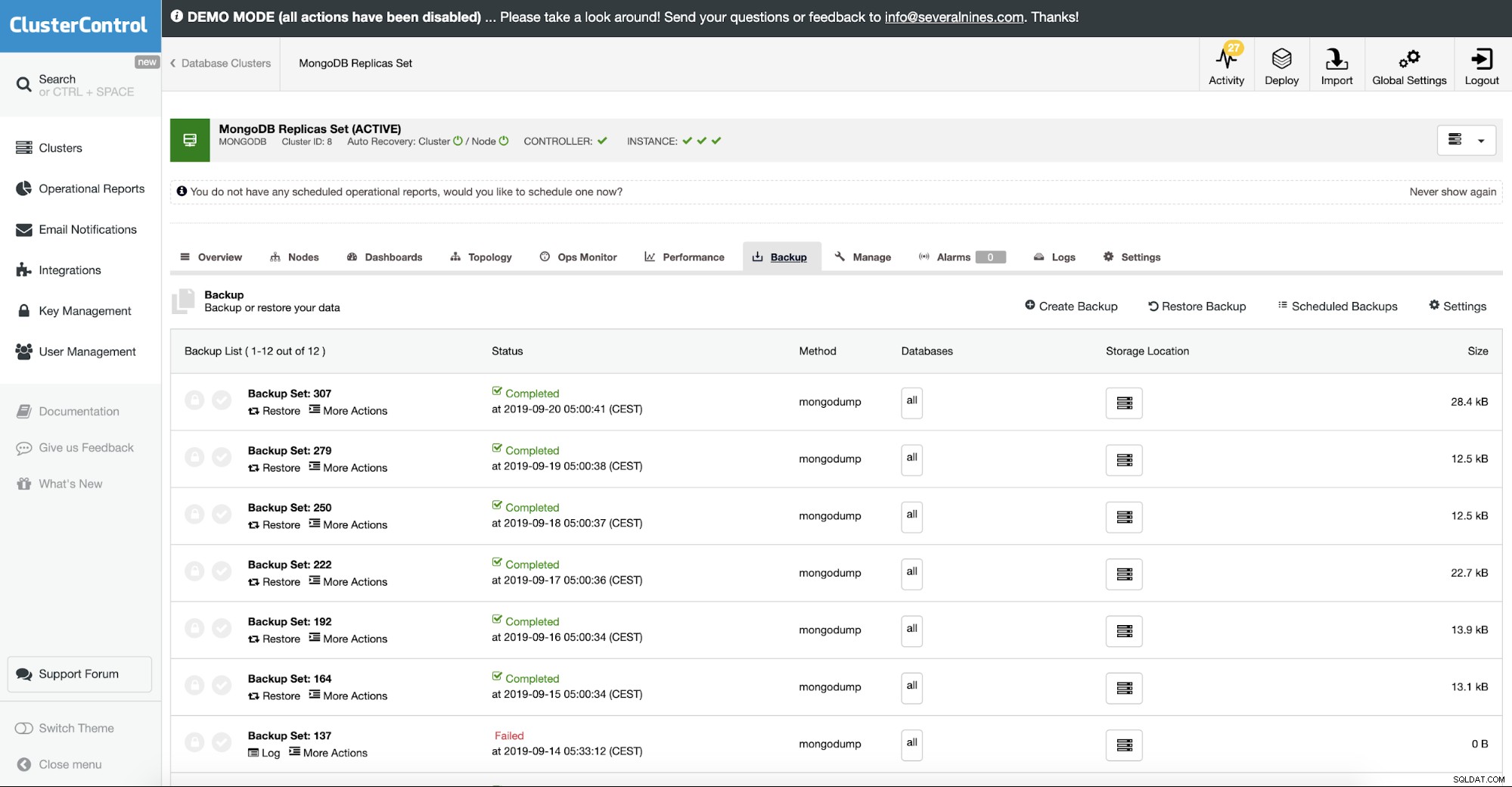
Restauration de MongoDB à partir d'une sauvegarde
Il existe essentiellement deux façons d'utiliser un vidage au format BSON :
- Exécutez mongod directement depuis le répertoire de sauvegarde
- Exécutez mongorestore et restaurez la sauvegarde
Exécuter mongod directement à partir d'une sauvegarde
Une condition préalable à l'exécution de mongod directement à partir de la sauvegarde est que la cible de la sauvegarde soit un vidage standard et qu'elle ne soit pas compressée.
Le démon MongoDB vérifiera alors l'intégrité du répertoire de données, ajoutera la base de données d'administration, les journaux, les catalogues de collection et d'index et quelques autres fichiers nécessaires pour exécuter MongoDB. Si vous exécutiez auparavant WiredTiger comme moteur de stockage, il exécutera désormais les collections existantes en tant que MMAP. Pour les vidages de données simples ou les contrôles d'intégrité, cela fonctionne bien.
Exécuter mongorestore
Une meilleure façon de restaurer serait évidemment de restaurer le nœud à l'aide d'un mongorestore.
mongorestore dump/Cela restaurera la sauvegarde dans les paramètres de serveur par défaut (localhost, port 27017) et écrasera toutes les bases de données de la sauvegarde qui résident sur ce serveur. Il existe maintenant des tonnes de paramètres pour manipuler le processus de restauration, et nous aborderons certains des plus importants.
Dans ClusterControl, cela se fait dans l'option de sauvegarde de restauration. Vous pouvez choisir la machine lorsque la sauvegarde sera restaurée et traiter en prenant soin du reste. Cela inclut la sauvegarde chiffrée alors que normalement vous auriez également besoin de déchiffrer votre sauvegarde.
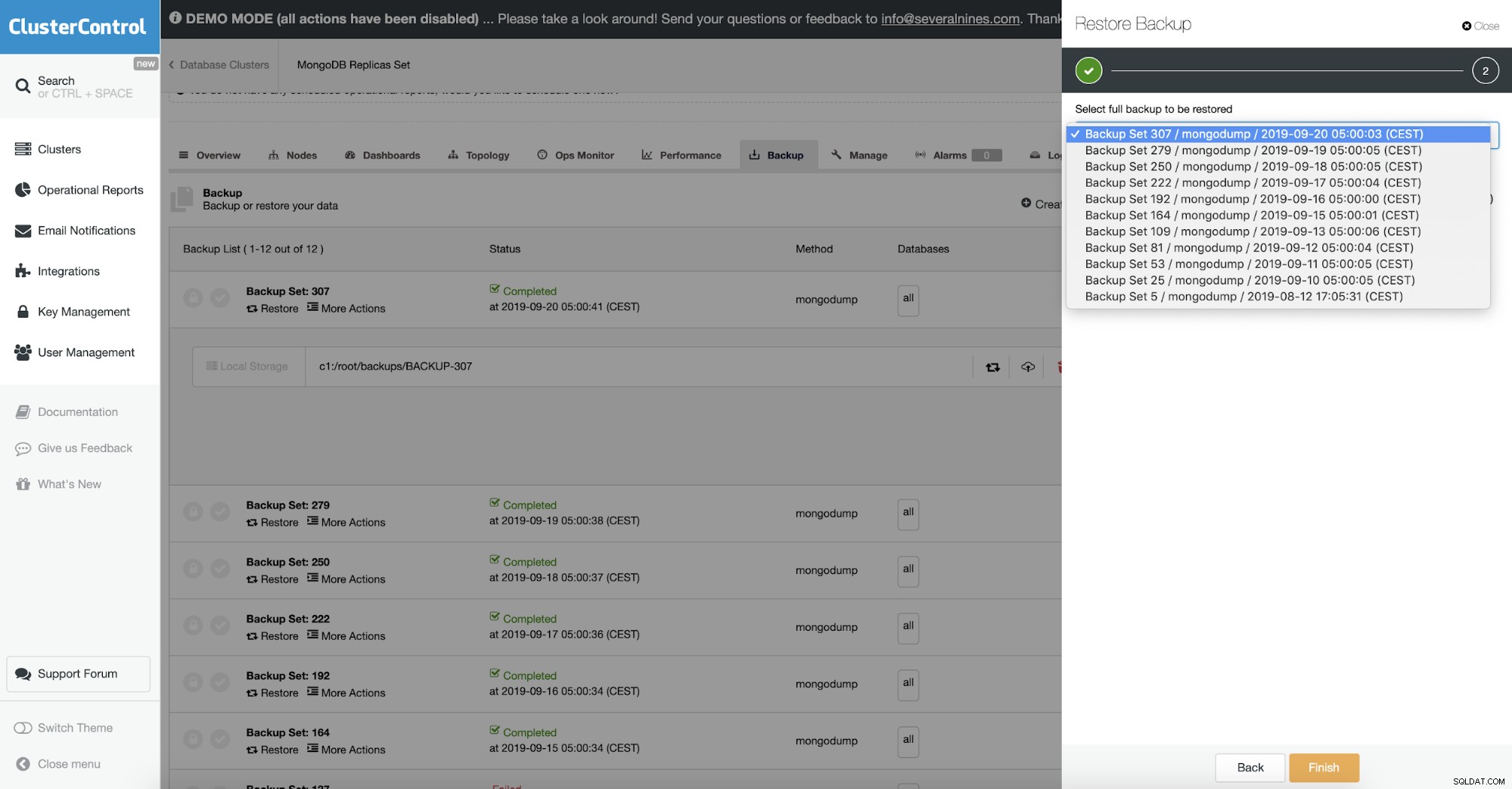
Validation d'objet
Comme la sauvegarde contient des données BSON, vous vous attendez à ce que le contenu de la sauvegarde soit correct. Cependant, il se peut que le document qui a été jeté ait été mal formé, pour commencer. Mongodump ne vérifie pas l'intégrité des données qu'il vide.
Pour répondre à cette utilisation -- objcheck qui force mongorestore à valider toutes les demandes des clients dès réception pour s'assurer que les clients n'insèrent jamais de documents invalides dans la base de données. Cela peut avoir un léger impact sur les performances.
Relecture d'Oplog
Oplog sur votre sauvegarde vous permettra d'effectuer une sauvegarde cohérente et d'effectuer une récupération ponctuelle. Activez le paramètre oplogReplay pour appliquer l'oplog pendant le processus de restauration. Pour contrôler la distance de relecture de l'oplog, vous pouvez définir un horodatage dans le paramètre oplogLimit. Seules les transactions jusqu'à l'horodatage seront alors appliquées.
Restauration d'un ReplicaSet complet à partir d'une sauvegarde
La restauration d'un replicaSet n'est pas très différente de la restauration d'un seul nœud. Soit vous devez d'abord configurer le replicaSet et restaurer directement dans le replicaSet. Ou vous restaurez d'abord un seul nœud, puis utilisez ce nœud restauré pour créer un replicaSet.
Restaurez d'abord le nœud, puis créez replicaSet
Maintenant, les deuxième et troisième nœuds synchroniseront leurs données à partir du premier nœud. Une fois la synchronisation terminée, notre replicaSet a été restauré.
Créez d'abord un ReplicaSet, puis restaurez
différent du processus précédent, vous pouvez d'abord créer le replicaSet. Configurez d'abord les trois hôtes avec le replicaSet activé, démarrez les trois démons et lancez le replicaSet sur le premier nœud :
Maintenant que nous avons créé le replicaSet, nous pouvons directement y restaurer notre sauvegarde :
À notre avis, restaurer un replicaSet de cette manière est beaucoup plus élégant. C'est plus proche de la façon dont vous configureriez normalement un nouveau replicaSet à partir de zéro, puis le rempliriez avec des données (de production).
Amorçage d'un nouveau nœud dans un ReplicaSet
Lors de la mise à l'échelle d'un cluster en ajoutant un nouveau nœud dans MongoDB, la synchronisation initiale de l'ensemble de données doit avoir lieu. Avec la réplication MySQL et Galera, nous sommes tellement habitués à utiliser une sauvegarde pour amorcer la synchronisation initiale. Avec MongoDB, cela est possible, mais uniquement en faisant une copie binaire du répertoire de données. Si vous n'avez pas les moyens de faire un instantané du système de fichiers, vous devrez faire face à des temps d'arrêt sur l'un des nœuds existants. Le processus, avec temps d'arrêt, est décrit ci-dessous.
Semer avec une sauvegarde
Que se passerait-il donc si vous restaurez le nouveau nœud à partir d'une sauvegarde mongodump à la place, puis que vous le faisiez rejoindre un replicaSet ? La restauration à partir d'une sauvegarde devrait, en théorie, donner le même jeu de données. Comme ce nouveau nœud a été restauré à partir d'une sauvegarde, il lui manquera le replicaSetId et MongoDB le remarquera. Comme MongoDB ne voit pas ce nœud comme faisant partie du replicaSet, la commande rs.add() déclenchera alors toujours la synchronisation initiale de MongoDB. La synchronisation initiale déclenchera toujours la suppression de toutes les données existantes sur le nœud MongoDB.
Le replicaSetId est généré lors du lancement d'un replicaSet et ne peut malheureusement pas être défini manuellement. C'est dommage car la récupération à partir d'une sauvegarde (y compris la relecture de l'oplog) nous donnerait théoriquement un ensemble de données 100% identique. Ce serait bien si la synchronisation initiale était facultative dans MongoDB pour satisfaire ce cas d'utilisation.



