Les systèmes de base de données fonctionnent mieux lorsqu'il y a une charge de travail répartie entre un certain nombre d'instances en cours d'exécution ou que les données sont plutôt catégorisées de manière simple. MongoDB utilise le sharding de sorte que les données d'une base de données donnée soient regroupées en fonction d'une clé. Le sharding améliore la mise à l'échelle horizontale, ce qui se traduit par de meilleures performances et une fiabilité accrue. En général, MongoDB offre une mise à l'échelle horizontale et verticale par opposition au SGBD SQL, par exemple MySQL, qui ne favorise que la mise à l'échelle verticale.
MongoDB a un modèle de cohérence plus lâche dans lequel un document d'une collection peut avoir une clé supplémentaire qui serait absente des autres documents de la même collection.
Partage
Le sharding consiste essentiellement à partitionner les données en morceaux séparés, puis à définir une plage de morceaux sur différents serveurs de fragments. Une clé de partition qui est souvent un champ présent dans tous les documents de la base de données à partitionner est utilisée pour regrouper les données. Le sharding fonctionne main dans la main avec la réplication pour accélérer le débit de lecture en garantissant une charge de travail répartie entre plusieurs serveurs plutôt que de dépendre d'un seul serveur. En outre, la réplication garantit que des copies des données écrites sont disponibles.
Supposons que nous ayons 120 documents dans une collection, ces données peuvent être partagées de sorte que nous ayons 3 jeux de répliques et chacun a 40 documents, comme illustré dans la configuration de configuration ci-dessous. Si deux clients envoient des requêtes, l'un pour récupérer un document qui est dans l'index 35 et l'autre dont l'index est à 92, la requête est reçue par le routeur de requête (un processus mongos) qui à son tour contacte le nœud de configuration qui conserve un enregistrement de comment les plages de morceaux sont réparties entre les fragments. Lorsque l'identité du document spécifié est trouvée, elle est ensuite extraite de la partition associée. Par exemple ci-dessus, le document du premier client sera récupéré à partir de la partition A et pour le client B, le document sera récupéré à partir de la partition C. En général, il y aura une charge de travail distribuée définie comme une mise à l'échelle horizontale.
Pour les fragments donnés, si la taille d'une collection dans un fragment dépasse le chunk_size, la collection sera automatiquement divisée et équilibrée entre les fragments à l'aide de la clé de fragment définie. Dans la configuration du déploiement, pour l'exemple ci-dessous, nous aurons besoin de 3 jeux de répliques chacun avec un primaire et quelques secondaires. Les nœuds principaux agissent également en tant que serveurs de partitionnement.
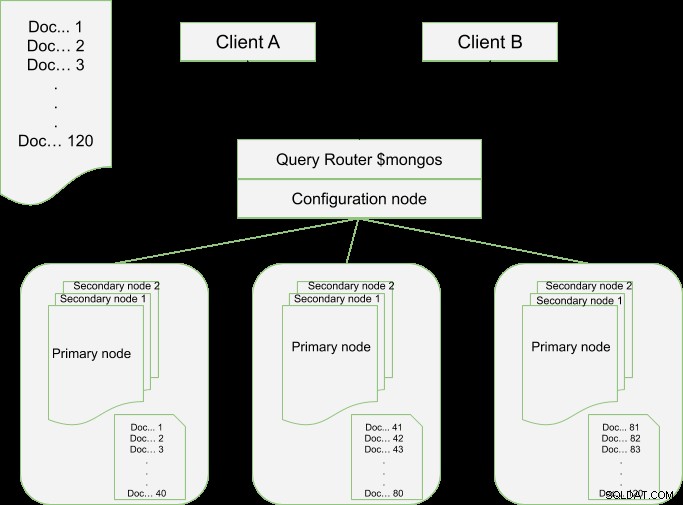
La configuration minimale recommandée pour un déploiement de production MongoDB sera d'au moins trois serveurs de partitions chacun avec un jeu de réplicas. Pour de meilleures performances, les serveurs mongos sont déployés sur des serveurs séparés tandis que les nœuds de configuration sont intégrés aux fragments.
Déployer des fragments MongoDB avec Ansible
La configuration séparée des fragments et des jeux de réplicas d'un cluster est une entreprise fastidieuse, c'est pourquoi nous résolvons dans des outils simples comme Ansible pour obtenir les résultats requis avec beaucoup de facilité. Les playbooks sont utilisés pour écrire les configurations et les tâches requises que le logiciel Ansible exécutera.
Le processus systématique du playbook doit être :
- Installer les packages de base mongo (no-server, pymongo et interface de ligne de commande)
- Installez le serveur mongodb. Suivez ce guide pour commencer.
- Configurez des instances mongod et leurs jeux de réplicas correspondants.
- Configurer et paramétrer les serveurs de configuration
- Configurer et configurer le service de routage Mongos.
- Ajoutez les partitions à votre cluster.
Le playbook de niveau supérieur devrait ressembler à ceci
- name: install mongo base packages include: mongod.yml
tags: - mongod
- name: configure config server
include: configServer.yml
when: inventory_hostname in groups['mongoc-servers']
tags:
- cs
- name: configure mongos server
include: configMongos.yml
when: inventory_hostname in groups['mongos-server'] tags:
- mongos
- name: add shards
include: addShards.yml
when: inventory_hostname in groups['mongos-servers']
tags:
- mongos
- shardsNous pouvons enregistrer le fichier ci-dessus sous le nom mongodbCluster.yml.
Plusieursnines Devenez un administrateur de base de données MongoDB – Amener MongoDB en productionDécouvrez ce que vous devez savoir pour déployer, surveiller, gérer et faire évoluer MongoDBDélécharger gratuitementUn simple fichier mongodb.yml ressemblera à :
---
- hosts: ansible-test
remote_user: root
become: yes
tasks:
- name: Import the public key used by the package management system
apt_key: keyserver=hkp://keyserver.ubuntu.com:80 id=7F0CEB10 state=present
- name: Add MongoDB repository
apt_repository: repo='deb <a class="vglnk" href="https://downloads-distro.mongodb.org/repo/ubuntu-upstart" rel="nofollow"><span>http</span><span>://</span><span>downloads</span><span>-</span><span>distro</span><span>.</span><span>mongodb</span><span>.</span><span>org</span><span>/</span><span>repo</span><span>/</span><span>ubuntu</span><span>-</span><span>upstart</span></a> dist 10gen' state=present
- name: install mongodb
apt: pkg=mongodb-org state=latest update_cache=yes
notify:
- start mongodb
handlers:
- name: start mongodb
service: name=mongod state=startedAux paramètres généraux requis dans le déploiement d'un jeu de répliques, nous avons besoin de ces deux autres afin d'ajouter les fragments.
- fragment : par défaut, il est nul. Il s'agit d'une chaîne de connexion de partition qui doit être au format
/host:port. Par exemple replica0/siteurl1.com:27017 - indiquer : par défaut, la valeur est présente, ce qui dicte que le fragment doit être présent, sinon on peut le définir comme absent.
Après avoir déployé un jeu de répliques comme expliqué dans ce blog, vous pouvez procéder à l'ajout des fragments.
# add a replicaset shard named replica0 with a member running on port 27017 on mongodb0.example.net
- mongodb_shard:
login_user: admin
login_password: root
shard: "replica0/mongodb1.example.net:27017"
state: present
# add a standalone mongod shard running on port 27018 of mongodb2.example.net
- mongodb_shard:
login_user: admin
login_password: root
shard: "mongodb2.example.net:27018"
state: present
# Single node shard running on localhost
- name: Ensure shard replica0 exists
mongodb_shard:
login_user: admin
login_password: root
shard: "replica0/localhost:3001"
state: present
# Single node shard running on localhost
- name: Ensure shard replica0 exists
mongodb_shard:
login_user: admin
login_password: root
shard: "replica0/localhost:3002"
state: presentAprès avoir configuré toutes ces configurations, nous exécutons le playbook avec la commande
ansible-playbook -i hosts mongodbCluster.ymlUne fois le playbook terminé, nous pouvons nous connecter à n'importe lequel des serveurs mongos et émettre la commande sh.status(). Si la sortie est quelque chose comme ci-dessous, les fragments ont été déployés. De plus, vous pouvez voir la clé mongodb_shard si elle a été évaluée avec succès.
mongos> sh.status()
--- Sharding Status ---
sharding version: { "_id" : 1, "version" : 3 }
shards:
{ "_id" : "shardA", "host" : "locahhost1/web2:2017,locahhost3:2017" }
{ "_id" : "shardB", "host" : "locahhost3/web2:2018,locahhost3:2019" }
{ "_id" : "shardC", "host" : "locahhost3/web2:2019,locahhost3:2019" }
databases:
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }Pour supprimer un fragment appelé replica0
- mongodb_shard:
login_user: admin
login_password: root
shard: replica0
state: absentConclusion
Ansible a joué un rôle majeur dans la simplification du processus de déploiement, car nous n'avons qu'à définir les tâches à exécuter. Imaginez par exemple si vous aviez 40 membres d'un jeu de réplicas et que vous deviez ajouter des fragments à chacun. Suivre la voie normale vous prendra des années et est sujet à de nombreuses erreurs humaines. Avec ansible, vous définissez simplement ces tâches dans un simple fichier appelé playbook et ansible s'occupera des tâches lorsque le fichier sera exécuté.



