L'efficacité d'une base de données repose non seulement sur le réglage fin des paramètres les plus critiques, mais aussi sur la présentation appropriée des données dans les collections associées. Récemment, j'ai travaillé sur un projet qui développait une application de chat social, et après quelques jours de test, nous avons remarqué un certain décalage lors de la récupération des données de la base de données. Nous n'avions pas autant d'utilisateurs, nous avons donc exclu le réglage des paramètres de la base de données et nous nous sommes concentrés sur nos requêtes pour trouver la cause première.
À notre grande surprise, nous avons réalisé que notre structuration des données n'était pas tout à fait appropriée dans la mesure où nous avions plus d'une requête de lecture pour récupérer des informations spécifiques.
Le modèle conceptuel de mise en place des sections d'application dépend fortement de la structure des collections de la base de données. Par exemple, si vous vous connectez à une application sociale, les données sont introduites dans les différentes sections en fonction de la conception de l'application, comme illustré dans la présentation de la base de données.
En un mot, pour une base de données bien conçue, la structure du schéma et les relations de collection sont des éléments clés pour améliorer sa vitesse et son intégrité, comme nous le verrons dans les sections suivantes.
Nous discuterons des facteurs à prendre en compte lors de la modélisation de vos données.
Qu'est-ce que la modélisation des données ?
La modélisation des données est généralement l'analyse des éléments de données dans une base de données et leur relation avec d'autres objets de cette base de données.
Dans MongoDB par exemple, nous pouvons avoir une collection d'utilisateurs et une collection de profils. La collection d'utilisateurs répertorie les noms des utilisateurs pour une application donnée, tandis que la collection de profils capture les paramètres de profil de chaque utilisateur.
Dans la modélisation des données, nous devons concevoir une relation pour connecter chaque utilisateur au profil correspondant. En un mot, la modélisation des données est l'étape fondamentale de la conception de bases de données en plus de constituer la base de l'architecture de la programmation orientée objet. Cela donne également un indice sur l'apparence de l'application physique au cours de la progression du développement. Une architecture d'intégration application-base de données peut être illustrée ci-dessous.
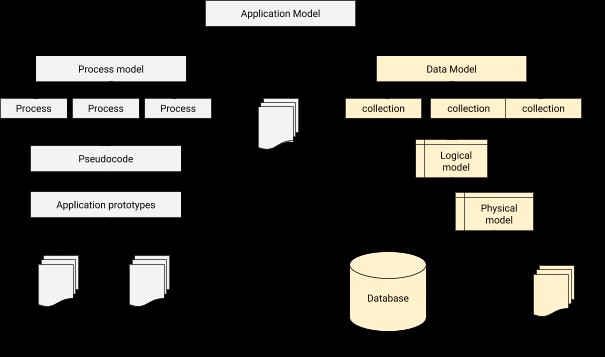
Le processus de modélisation des données dans MongoDB
La modélisation des données s'accompagne d'une amélioration des performances de la base de données, mais au détriment de certaines considérations, notamment :
- Modèles de récupération des données
- Équilibrer les besoins de l'application tels que :les requêtes, les mises à jour et le traitement des données
- Caractéristiques de performance du moteur de base de données choisi
- La structure inhérente des données elles-mêmes
Structure des documents MongoDB
Les documents dans MongoDB jouent un rôle majeur dans la prise de décision sur la technique à appliquer pour un ensemble de données donné. Il existe généralement deux relations entre les données, qui sont :
- Données intégrées
- Données de référence
Données intégrées
Dans ce cas, les données associées sont stockées dans un document unique sous forme de valeur de champ ou de tableau dans le document lui-même. Le principal avantage de cette approche est que les données sont dénormalisées et offrent donc la possibilité de manipuler les données associées en une seule opération de base de données. Par conséquent, cela améliore la vitesse à laquelle les opérations CRUD sont effectuées, donc moins de requêtes sont nécessaires. Prenons un exemple de document ci-dessous :
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}Dans cet ensemble de données, nous avons un étudiant avec son nom et quelques autres informations supplémentaires. Le champ Paramètres a été intégré à un objet et, en outre, le champ placeLocation est également intégré à un objet avec les configurations de latitude et de longitude. Toutes les données de cet étudiant ont été contenues dans un seul document. Si nous avons besoin de récupérer toutes les informations pour cet étudiant, nous exécutons simplement :
db.students.findOne({StudentName : "George Beckonn"})Atouts de l'intégration
- Vitesse d'accès aux données accrue :pour un meilleur taux d'accès aux données, l'intégration est la meilleure option, car une seule opération de requête peut manipuler les données dans le document spécifié avec une seule recherche dans la base de données.
- Réduction de l'incohérence des données :pendant le fonctionnement, en cas de problème (par exemple, une déconnexion du réseau ou une panne de courant), seul un petit nombre de documents peut être affecté, car les critères sélectionnent souvent un seul document.
- Opérations CRUD réduites. C'est-à-dire que les opérations de lecture seront en fait plus nombreuses que les écritures. En outre, il est possible de mettre à jour les données associées en une seule opération d'écriture atomique. C'est-à-dire que pour les données ci-dessus, nous pouvons mettre à jour le numéro de téléphone et également augmenter la distance avec cette seule opération :
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Faiblesses de l'intégration
- Taille de document limitée. Tous les documents dans MongoDB sont limités à la taille BSON de 16 mégaoctets. Par conséquent, la taille globale du document ainsi que les données intégrées ne doivent pas dépasser cette limite. Sinon, pour certains moteurs de stockage tels que MMAPv1, les données peuvent devenir trop nombreuses et entraîner une fragmentation des données en raison de performances d'écriture dégradées.
- Duplication des données :plusieurs copies des mêmes données compliquent l'interrogation des données répliquées et le filtrage des documents intégrés peut prendre plus de temps, ce qui surpasse l'avantage principal de l'intégration.
Notation par points
La notation par points est la caractéristique d'identification des données intégrées dans la partie programmation. Il est utilisé pour accéder aux éléments d'un champ intégré ou d'un tableau. Dans l'exemple de données ci-dessus, nous pouvons renvoyer les informations de l'étudiant dont l'emplacement est "Ambassade" avec cette requête en utilisant la notation par points.
db.users.find({'Settings.location': 'Embassy'})Données de référence
La relation de données dans ce cas est que les données associées sont stockées dans différents documents, mais un lien de référence est émis vers ces documents associés. Pour les exemples de données ci-dessus, nous pouvons les reconstruire de telle manière que :
Fiche utilisateur
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Document de paramètres
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Il existe 2 documents différents, mais ils sont liés par la même valeur pour les champs _id et id. Le modèle de données est ainsi normalisé. Cependant, pour que nous puissions accéder aux informations d'un document connexe, nous devons émettre des requêtes supplémentaires et, par conséquent, cela entraîne une augmentation du temps d'exécution. Par exemple, si nous voulons mettre à jour le ParentPhone et les paramètres de distance associés, nous aurons au moins 3 requêtes, c'est-à-dire
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Atouts du référencement
- Cohérence des données. Pour chaque document, une forme canonique est conservée, ce qui réduit considérablement les risques d'incohérence des données.
- Amélioration de l'intégrité des données. Grâce à la normalisation, il est facile de mettre à jour les données quelle que soit la durée de l'opération et donc de garantir des données correctes pour chaque document sans causer de confusion.
- Amélioration de l'utilisation du cache. Les documents canoniques consultés fréquemment sont stockés dans le cache plutôt que pour les documents intégrés qui sont consultés plusieurs fois.
- Utilisation efficace du matériel. Contrairement à l'incorporation, qui peut entraîner une croissance excessive du document, le référencement ne favorise pas la croissance du document et réduit donc l'utilisation du disque et de la RAM.
- Flexibilité améliorée, en particulier avec un grand nombre de sous-documents.
- Écriture plus rapide.
Faiblesses du référencement
- Recherches multiples :étant donné que nous devons rechercher dans un certain nombre de documents qui correspondent aux critères, le temps de lecture augmente lors de la récupération à partir du disque. En outre, cela peut entraîner des échecs de cache.
- De nombreuses requêtes sont émises pour réaliser certaines opérations. Par conséquent, les modèles de données normalisés nécessitent davantage d'allers-retours vers le serveur pour effectuer une opération spécifique.
Normalisation des données
La normalisation des données fait référence à la restructuration d'une base de données conformément à certaines formes normales afin d'améliorer l'intégrité des données et de réduire les événements de redondance des données.
La modélisation des données s'articule autour de 2 techniques majeures de normalisation à savoir :
-
Modèles de données normalisés
Telle qu'appliquée aux données de référence, la normalisation divise les données en plusieurs collections avec des références entre les nouvelles collections. Une seule mise à jour de document sera émise pour l'autre collection et appliquée en conséquence au document correspondant. Cela fournit une représentation efficace de la mise à jour des données et est couramment utilisé pour les données qui changent assez souvent.
-
Modèles de données dénormalisés
Les données contiennent des documents intégrés, ce qui rend les opérations de lecture assez efficaces. Cependant, il est associé à une plus grande utilisation de l'espace disque et à des difficultés de synchronisation. Le concept de dénormalisation peut être bien appliqué aux sous-documents dont les données ne changent pas assez souvent.
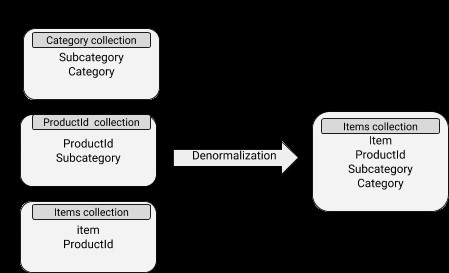
Schéma MongoDB
Un schéma est essentiellement un squelette de champs et de type de données que chaque champ doit contenir pour un ensemble de données donné. Du point de vue SQL, toutes les lignes sont conçues pour avoir les mêmes colonnes et chaque colonne doit contenir le type de données défini. Cependant, dans MongoDB, nous avons un schéma flexible par défaut qui ne détient pas la même conformité pour tous les documents.
Schéma flexible
Un schéma flexible dans MongoDB définit que les documents n'ont pas nécessairement besoin d'avoir les mêmes champs ou types de données, car un champ peut différer d'un document à l'autre au sein d'une collection. L'avantage principal de ce concept est qu'il est possible d'ajouter de nouveaux champs, de supprimer ceux qui existent déjà ou de modifier les valeurs des champs en un nouveau type et donc de mettre à jour le document dans une nouvelle structure.
Par exemple on peut avoir ces 2 documents dans la même collection :
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}Dans le premier document, nous avons un champ âge alors que dans le deuxième document il n'y a pas de champ âge. De plus, le type de données pour le champ ParentPhone est un nombre alors que dans le deuxième document, il a été défini sur false, qui est un type booléen.
La flexibilité du schéma facilite le mappage des documents sur un objet et chaque document peut correspondre aux champs de données de l'entité représentée.
Schéma rigide
Bien que nous ayons dit que ces documents peuvent différer les uns des autres, vous pouvez parfois décider de créer un schéma rigide. Un schéma rigide définira que tous les documents d'une collection partageront la même structure, ce qui vous donnera une meilleure chance de définir des règles de validation de document afin d'améliorer l'intégrité des données lors des opérations d'insertion et de mise à jour.
Types de données de schéma
Lorsque vous utilisez certains pilotes de serveur pour MongoDB tels que mongoose, certains types de données fournis vous permettent de valider les données. Les types de données de base sont :
- Chaîne
- Numéro
- Booléen
- Date
- Tampon
- ObjectId
- Tableau
- Mixte
- Décimale128
- Carte
Jetez un oeil à l'exemple de schéma ci-dessous
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Exemple de cas d'utilisation
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Validation du schéma
Autant que vous pouvez effectuer la validation des données du côté de l'application, il est toujours recommandé d'effectuer également la validation du côté du serveur. Nous y parvenons en utilisant les règles de validation du schéma.
Ces règles sont appliquées lors des opérations d'insertion et de mise à jour. Ils sont déclarés sur une base de collecte lors du processus de création normalement. Cependant, vous pouvez également ajouter les règles de validation de document à une collection existante à l'aide de la commande collMod avec les options de validation, mais ces règles ne sont pas appliquées aux documents existants jusqu'à ce qu'une mise à jour leur soit appliquée.
De même, lors de la création d'une nouvelle collection à l'aide de la commande db.createCollection(), vous pouvez émettre l'option validator. Jetez un œil à cet exemple lors de la création d'une collection pour les étudiants. Depuis la version 3.6, MongoDB prend en charge la validation du schéma JSON, il vous suffit donc d'utiliser l'opérateur $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})Dans cette conception de schéma, si nous essayons d'insérer un nouveau document comme :
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})La fonction de rappel renverra l'erreur ci-dessous, en raison de certaines règles de validation violées telles que la valeur de l'année fournie n'est pas dans les limites spécifiées.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})De plus, vous pouvez ajouter des expressions de requête à votre option de validation à l'aide d'opérateurs de requête, à l'exception de $where, $text, near et $nearSphere, c'est-à-dire :
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Niveaux de validation de schéma
Comme mentionné précédemment, la validation est émise pour les opérations d'écriture, normalement.
Cependant, la validation peut également être appliquée à des documents déjà existants.
Il existe 3 niveaux de validation :
- Strict :il s'agit du niveau de validation MongoDB par défaut et il applique les règles de validation à toutes les insertions et mises à jour.
- Modéré :les règles de validation sont appliquées lors des insertions, des mises à jour et aux documents déjà existants qui remplissent les critères de validation uniquement.
- Off :ce niveau définit les règles de validation pour un schéma donné sur null, aucune validation ne sera donc effectuée sur les documents.
Exemple :
Insérons les données ci-dessous dans une collection client.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Si nous appliquons le niveau de validation modéré en utilisant :
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Les règles de validation seront appliquées uniquement au document avec _id de 1 puisqu'il correspondra à tous les critères.
Pour le deuxième document, puisque les règles de validation ne sont pas respectées avec les critères émis, le document ne sera pas validé.
Actions de validation de schéma
Après avoir effectué la validation des documents, certains peuvent enfreindre les règles de validation. Il est toujours nécessaire de fournir une action lorsque cela se produit.
MongoDB fournit deux actions qui peuvent être émises pour les documents qui échouent aux règles de validation :
- Erreur :il s'agit de l'action MongoDB par défaut, qui rejette toute insertion ou mise à jour en cas de violation des critères de validation.
-
Avertir :cette action enregistrera la violation dans le journal MongoDB, mais permettra de terminer l'opération d'insertion ou de mise à jour. Par exemple :
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Si nous essayons d'insérer un document comme celui-ci :
db.students.insert( { name: "Amanda", status: "Updated" } );Le gpa est manquant indépendamment du fait qu'il s'agit d'un champ obligatoire dans la conception du schéma, mais comme l'action de validation a été définie sur avertir, le document sera enregistré et un message d'erreur sera enregistré dans le journal MongoDB.



