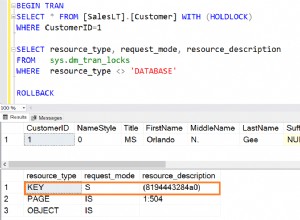
Vous devez vérifier les plans d'exécution. Cependant, je m'attendrais à ce que les plans d'exécution soient différents - ou du moins ils devraient l'être dans certaines circonstances.
La première requête :
SELECT DISTINCT a, b, c FROM table1
UNION DISTINCT
SELECT DISTINCT a, b, c FROM table2
peut facilement tirer parti des index sur table1(a, b, c) et table2(a, b, c) avant faire le dernier UNION . Cela devrait accélérer l'union finale en réduisant la taille des données. La deuxième requête n'a pas cet avantage.
En fait, la façon la plus efficace d'écrire cette requête serait probablement d'avoir les deux index et d'utiliser :
SELECT DISTINCT a, b, c FROM table1 t1
UNION ALL
SELECT DISTINCT a, b, c
FROM table2 t2
WHERE NOT EXISTS (SELECT 1 FROM table1 t1 WHERE t2.a = t1.a and t2.b = t1.b and t2.c = t1.c)
Ceci est presque identique, bien qu'il puisse gérer NULL les valeurs du deuxième tableau un peu différemment.