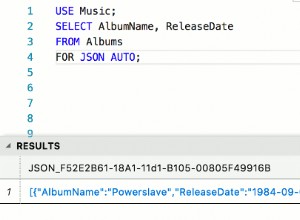
Vous souffrez de "double encodage".
Voici ce qui s'est passé.
- Le client avait des caractères encodés en utf8 ; et
SET NAMES latin1a menti en prétendant que le client avait un encodage latin1 ; et- La colonne de la table déclarée
CHARACTER SET utf8.
Passons en revue ce qui arrive à e-acute :é .
- L'hexadécimal pour cela, en utf8 est de 2 octets :
C3A9. SET NAMES latin1l'a vu comme 2 caractères encodés en latin1Ãet©(hexadécimal :C3etA9)- Puisque la cible était
CHARACTER SET utf8, ces 2 caractères devaient être convertis.Ãa été converti en utf8 (hexC383) et©(hexadécimalC2A9) - Donc, 4 octets ont été stockés (hex
C383C2A9)
Lors de la relecture, les étapes inverses ont été effectuées et l'utilisateur final n'a peut-être rien remarqué d'anormal. Qu'est-ce qui ne va pas :
- Les données stockées sont 2 fois plus volumineuses qu'elles ne le devraient (3 x pour les langues asiatiques).
- Les comparaisons pour égal, supérieur à, etc. peuvent ne pas fonctionner comme prévu.
ORDER BYpeut ne pas fonctionner comme prévu.
Quelque chose comme ceci réparera vos données :
UPDATE ... SET col = CONVERT(BINARY(CONVERT(
CONVERT(UNHEX(col) USING utf8)
USING latin1)) USING utf8);
Plus de discussion etPlus d'exemples de correction