Tout d'abord, vous devez décider si vous souhaitez maintenir une connexion permanente à MySQL. Ce dernier est plus performant, mais nécessite un peu d'entretien.
Par défaut wait_timeout
dans MySQL est de 8 heures. Chaque fois qu'une connexion est inactive plus longtemps que wait_timeout c'est fermé. Lorsque le serveur MySQL est redémarré, il ferme également toutes les connexions établies. Ainsi, si vous utilisez une connexion persistante, vous devez vérifier avant d'utiliser une connexion si elle est active (et si ce n'est pas le cas, reconnectez-vous). Si vous utilisez une connexion par requête, vous n'avez pas besoin de maintenir l'état de la connexion, car les connexions sont toujours fraîches.
Connexion par demande
Une connexion de base de données non persistante a une surcharge évidente d'ouverture de connexion, d'établissement de liaison, etc. (pour le serveur de base de données et le client) pour chaque requête HTTP entrante.
Voici une citation du tutoriel officiel de Flask concernant les connexions à la base de données :
Notez cependant que le contexte d'application est initialisé par requête (ce qui est en quelque sorte voilé par des problèmes d'efficacité et le jargon de Flask). Et donc, c'est encore très inefficace. Cependant, cela devrait résoudre votre problème. Voici un extrait dépouillé de ce qu'il suggère appliqué à pymysql :
import pymysql
from flask import Flask, g, request
app = Flask(__name__)
def connect_db():
return pymysql.connect(
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per request.'''
if not hasattr(g, 'db'):
g.db = connect_db()
return g.db
@app.teardown_appcontext
def close_db(error):
'''Closes the database connection at the end of request.'''
if hasattr(g, 'db'):
g.db.close()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Connexion persistante
Pour une connexion persistante à la base de données de connexion, il existe deux options principales. Soit vous disposez d'un pool de connexions, soit vous mappez les connexions aux processus de travail. Étant donné que les applications Flask WSGI sont normalement servies par des serveurs threadés avec un nombre fixe de threads (par exemple, uWSGI), le mappage des threads est plus facile et aussi efficace.
Il existe un package, DBUtils
, qui implémente à la fois, et PersistentDB
pour les connexions à mappage de threads.
Une mise en garde importante dans le maintien d'une connexion persistante concerne les transactions. L'API de reconnexion est ping
. C'est sûr pour la validation automatique des déclarations uniques, mais cela peut perturber entre une transaction (un peu plus de détails ici
). DBUtils s'en charge et ne doit se reconnecter que sur dbapi.OperationalError et dbapi.InternalError (par défaut, contrôlé par failures pour initialiser PersistentDB ) généré en dehors d'une transaction.
Voici à quoi ressemblera l'extrait ci-dessus avec PersistentDB .
import pymysql
from flask import Flask, g, request
from DBUtils.PersistentDB import PersistentDB
app = Flask(__name__)
def connect_db():
return PersistentDB(
creator = pymysql, # the rest keyword arguments belong to pymysql
user = 'guest', password = '', database = 'sakila',
autocommit = True, charset = 'utf8mb4',
cursorclass = pymysql.cursors.DictCursor)
def get_db():
'''Opens a new database connection per app.'''
if not hasattr(app, 'db'):
app.db = connect_db()
return app.db.connection()
@app.route('/')
def hello_world():
city = request.args.get('city')
cursor = get_db().cursor()
cursor.execute('SELECT city_id FROM city WHERE city = %s', city)
row = cursor.fetchone()
if row:
return 'City "{}" is #{:d}'.format(city, row['city_id'])
else:
return 'City "{}" not found'.format(city)
Micro-référence
Pour donner un petit indice sur les implications des performances en chiffres, voici un micro-benchmark.
J'ai couru :
uwsgi --http :5000 --wsgi-file app_persistent.py --callable app --master --processes 1 --threads 16uwsgi --http :5000 --wsgi-file app_per_req.py --callable app --master --processes 1 --threads 16
Et testez-les en charge avec la simultanéité 1, 4, 8, 16 via :
siege -b -t 15s -c 16 https://localhost:5000/?city=london
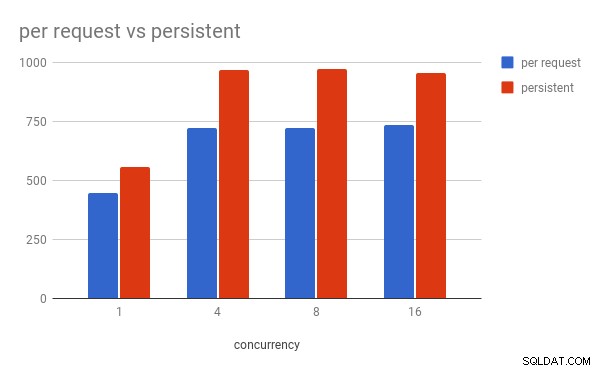
Observations (pour ma configuration locale) :
- Une connexion persistante est ~30 % plus rapide,
- Sur la simultanéité 4 et les versions ultérieures, le processus de travail uWSGI culmine à plus de 100 % d'utilisation du processeur (
pymysqldoit analyser le protocole MySQL en pur Python, ce qui est le goulot d'étranglement), - Sur la concurrence 16,
mysqldL'utilisation du processeur de est d'environ 55 % pour les demandes par requête et d'environ 45 % pour les connexions persistantes.