Si vous recherchez un algorithme d'approximation, je suggère de rechercher un algorithme k-means ou un cluster hiérarchique, en particulier une courbe monstre ou une courbe de remplissage d'espace. Tout d'abord, vous pouvez calculer un arbre couvrant minimal du graphe, puis supprimer les arêtes les plus longues et les plus chères. Ensuite, l'arbre forme de nombreux petits arbres et vous pouvez utiliser les k-means pour calculer un groupe de points, c'est-à-dire des clusters.
"L'algorithme de k-clustering à liaison unique ... est précisément l'algorithme de Kruskal ... équivalent à trouver un MST et à supprimer les k-1 arêtes les plus chères." Voir par exemple ici :https://stats.stackexchange.com/ questions/1475/logiciel-de-visualisation-pour-le-clustering .
Un bon exemple de courbe monstre est la courbe de Hilbert. La forme de base de cette courbe est une forme en U et en en copiant plusieurs ensemble et en la faisant tourner, la courbe remplit l'espace euklidien. Étonnamment, un code gris peut aider à connaître l'orientation de cette forme en U. Vous pouvez consulter la courbe de hilbert quadtree de l'index spatial de Nick article de blog sur plus de détails . Au lieu de calculer l'indice de la courbe, vous pouvez assembler un quadkey comme dans les cartes bing. La quadkey est unique pour chaque coordonnée et peut être utilisée avec des opérations normales sur les chaînes. Chaque position dans la clé fait partie de la courbe en forme de U et vous pouvez donc sélectionner cette région de points à partir de sélectionner partiellement de gauche à droite à partir du quadkey.
Dans cette image, vous pouvez voir que le polygone vert est trouvé à l'aide d'une courbe de Hilbert :
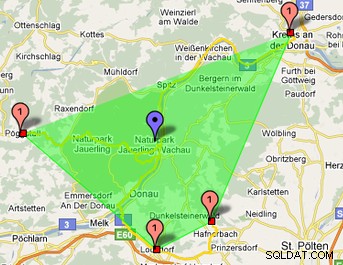
Vous pouvez trouver mes cours php ici :https://www.phpclasses.org/package/6202-PHP-Generate-points-of-an-Hilbert-curve.html