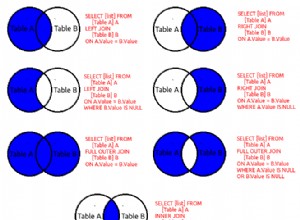
Spark peut lire et écrire données vers/depuis des bases de données relationnelles à l'aide de la source de données JDBC (comme vous l'avez fait dans votre premier exemple de code).
De plus (et complètement séparément), spark permet d'utiliser SQL pour interroger les vues qui ont été créés sur des données déjà chargées dans un DataFrame à partir d'une source. Par exemple :
val df = Seq(1,2,3).toDF("a") // could be any DF, loaded from file/JDBC/memory...
df.createOrReplaceTempView("my_spark_table")
spark.sql("select a from my_spark_table").show()
Seules les "tables" (appelées vues, à partir de Spark 2.0.0) créées de cette manière peuvent être interrogées à l'aide de SparkSession.sql .
Si vos données sont stockées dans une base de données relationnelle, Spark devra d'abord les lire à partir de là, et ce n'est qu'alors qu'il pourra exécuter tout calcul distribué sur la copie chargée. En bout de ligne - nous pouvons charger les données de la table en utilisant read , créez une vue temporaire, puis interrogez-la :
ss.read
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1/database_name")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.load()
.createOrReplaceTempView("my_spark_table")
// and then you can query the view:
val df = ss.sql("select * from my_spark_table where ... ")