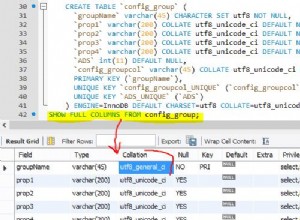
Il est préférable d'utiliser le utf8_bin classement car, même si ce n'est pas possible en UTF-8, dans le cas général, c'est théoriquement possible (comme c'est le cas avec UTF-16) pour le same chaîne à représenter par différent encodages, qu'une comparaison binaire ne comprendrait pas mais qu'un classement binaire comprendrait. Comme documenté sous Jeux de caractères Unicode
:
Par conséquent, si les comparaisons impliquant ces colonnes seront toujours être sensible à la casse, vous devez définir le classement de la colonne sur utf8_bin (afin qu'ils restent sensibles à la casse même si vous oubliez de préciser le contraire dans votre requête); ou si seules des requêtes particulières sont sensibles à la casse, vous pouvez spécifier que le utf8_bin le classement doit être utilisé en utilisant le COLLATE mot-clé :
SELECT * FROM table WHERE id = 'iSZ6fX' COLLATE utf8_bin