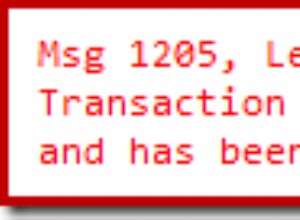
Vous devriez envisager de stocker vos données dans un schéma normalisé. Dans votre cas, le tableau devrait ressembler à :
| id | k | v |
|----|---|----------|
| 1 | A | 10 |
| 1 | B | 20 |
| 1 | C | 30 |
| 2 | A | Positive |
| 2 | B | Negative |
Ce schéma est plus souple et vous comprendrez pourquoi.
Alors, comment convertir les données données dans le nouveau schéma ? Vous aurez besoin d'une table d'aide contenant des numéros de séquence. Puisque votre colonne est varchar(255) vous ne pouvez y stocker que 128 valeurs (+ 127 délimiteurs). Mais créons simplement 1000 nombres. Vous pouvez utiliser n'importe quelle table avec suffisamment de lignes. Mais puisque tout serveur MySQL a le information_schema.columns table, je vais l'utiliser.
drop table if exists helper_sequence;
create table helper_sequence (i int auto_increment primary key)
select null as i
from information_schema.columns c1
join information_schema.columns c2
limit 1000;
Nous utiliserons ces nombres comme position des valeurs dans votre chaîne en joignant les deux tables.
Pour extraire une valeur d'une chaîne délimitée, vous pouvez utiliser le substring_index() une fonction. La valeur à la position i sera
substring_index(substring_index(t.options, '|', i ), '|', -1)
Dans votre chaîne, vous avez une séquence de clés suivie de ses valeurs. La position d'une clé est un nombre impair. Donc si la position de la clé est i , la position de la valeur correspondante sera i+1
Pour obtenir le nombre de délimiteurs dans la chaîne et limiter notre jointure, nous pouvons utiliser
char_length(t.options) - char_length(replace(t.options, '|', ''))
La requête pour stocker les données sous une forme normalisée serait :
create table normalized_table
select t.id
, substring_index(substring_index(t.options, '|', i ), '|', -1) as k
, substring_index(substring_index(t.options, '|', i+1), '|', -1) as v
from old_table t
join helper_sequence s
on s.i <= char_length(t.options) - char_length(replace(t.options, '|', ''))
where s.i % 2 = 1
Maintenant, exécutez select * from normalized_table et vous obtiendrez ceci :
| id | k | v |
|----|---|----------|
| 1 | A | 10 |
| 1 | B | 20 |
| 1 | C | 30 |
| 2 | A | Positive |
| 2 | B | Negative |
Alors pourquoi ce format est-il un meilleur choix ? Outre de nombreuses autres raisons, l'une est que vous pouvez facilement le convertir en votre ancien schéma avec
select id, group_concat(concat(k, '|', v) order by k separator '|') as options
from normalized_table
group by id;
| id | options |
|----|-----------------------|
| 1 | A|10|B|20|C|30 |
| 2 | A|Positive|B|Negative |
ou au format souhaité
select id, group_concat(concat(k, '|', v) order by k separator ',') as options
from normalized_table
group by id;
| id | options |
|----|-----------------------|
| 1 | A|10,B|20,C|30 |
| 2 | A|Positive,B|Negative |
Si vous ne vous souciez pas de la normalisation et que vous souhaitez simplement que cette tâche soit effectuée, vous pouvez mettre à jour votre table avec
update old_table o
join (
select id, group_concat(concat(k, '|', v) order by k separator ',') as options
from normalized_table
group by id
) n using (id)
set o.options = n.options;
Et déposez le normalized_table .
Mais alors vous ne pourrez pas utiliser des requêtes simples comme
select *
from normalized_table
where k = 'A'