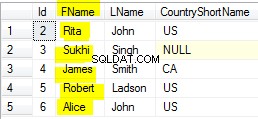
Il n'y a aucune différence entre ces deux instructions, et l'optimiseur transformera le IN au = quand IN contient un seul élément.
Cependant, lorsque vous avez une question comme celle-ci, exécutez simplement les deux instructions, exécutez leur plan d'exécution et voyez les différences. Ici - vous n'en trouverez pas.
Après une grande recherche en ligne, j'ai trouvé un document sur SQL pour le supporter (je suppose que cela s'applique à tous les SGBD) :
Voici le plan d'exécution des deux requêtes dans Oracle (la plupart des SGBD traiteront cela de la même manière) :
EXPLAIN PLAN FOR
select * from dim_employees t
where t.identity_number = '123456789'
Plan hash value: 2312174735
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| DIM_EMPLOYEES |
| 2 | INDEX UNIQUE SCAN | SYS_C0029838 |
-----------------------------------------------------
Et pour IN() :
EXPLAIN PLAN FOR
select * from dim_employees t
where t.identity_number in('123456789');
Plan hash value: 2312174735
-----------------------------------------------------
| Id | Operation | Name |
-----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| DIM_EMPLOYEES |
| 2 | INDEX UNIQUE SCAN | SYS_C0029838 |
-----------------------------------------------------
Comme vous pouvez le voir, les deux sont identiques. C'est sur une colonne indexée. Il en va de même pour une colonne non indexée (uniquement une analyse complète de la table).