Voici comment ces deux approches seront physiquement représentées dans la base de données :
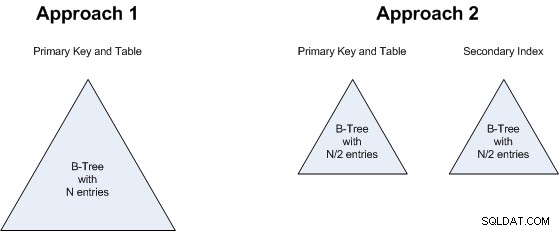
Analysons les deux approches...
Approche 1 (les deux directions stockées dans le tableau) :
- PRO :requêtes plus simples.
- Contre :les données peuvent être corrompues en insérant/mettant à jour/supprimant uniquement une direction.
- MINOR PRO :ne nécessite pas de contraintes supplémentaires pour s'assurer qu'une amitié ne peut pas être dupliquée.
- Analyse complémentaire nécessaire :
- TIE :Un index couvre dans les deux sens, vous n'avez donc pas besoin d'un index secondaire.
- TIE :exigences de stockage.
- TIE :performances.
Approche 2 (une seule direction stockée dans la table) :
- Contre :requêtes plus compliquées.
- PRO :Impossible de corrompre les données en oubliant de gérer la direction opposée, car il n'y a pas de direction opposée .
- Contre MINEUR :Nécessite
CHECK(UID < FriendID), donc une même amitié ne peut jamais être représentée de deux manières différentes, et la clé sur(UID, FriendID)peut faire son travail. - Analyse complémentaire nécessaire :
- TIE :deux index sont nécessaires pour couvrir
les deux sens d'interrogation (index composite sur
{UID, FriendID}et index composite sur{FriendID, UID}). - TIE :exigences de stockage.
- TIE :performances.
- TIE :deux index sont nécessaires pour couvrir
les deux sens d'interrogation (index composite sur
Le point 1 présente un intérêt particulier. MySQL/InnoDB toujours clusters données, et les index secondaires peuvent être coûteux dans les tables en cluster (voir "Inconvénients du clustering" dans cet article ), il peut donc sembler que l'index secondaire de l'approche 2 absorbe tous les avantages d'un nombre inférieur de lignes. Cependant , l'index secondaire contient exactement les mêmes champs que le primaire (seulement dans l'ordre inverse) donc il n'y a pas de surcharge de stockage dans ce cas particulier. Il n'y a pas non plus de pointeur vers le tas de table (puisqu'il n'y a pas de tas de table), il est donc probablement encore moins cher en termes de stockage qu'un index normal basé sur le tas. Et en supposant que la requête est couverte par l'index, il n'y aura pas non plus de double recherche normalement associée à un index secondaire dans une table en cluster. Donc, c'est fondamentalement une égalité (ni l'approche 1 ni l'approche 2 n'a un avantage significatif).
Le point 2 est lié au point 1 :peu importe si nous aurons un B-Tree de N valeurs ou deux B-Trees, chacun avec N/2 valeurs. Il s'agit donc également d'une égalité :les deux approches utiliseront à peu près la même quantité de stockage.
Le même raisonnement s'applique au point 3 :que nous recherchions un arbre B plus grand ou 2 plus petits, cela ne fait pas beaucoup de différence, donc c'est aussi une égalité.
Donc, pour la robustesse, et malgré des requêtes un peu plus laides et un besoin de CHECK supplémentaire , j'opterais pour l'approche 2.