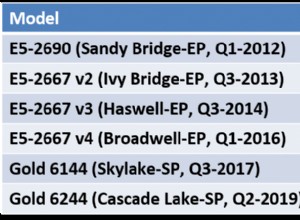
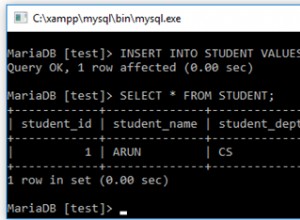
Mise à jour :cette fonctionnalité a été fusionnée dans pandas master et sortira en 0.15 (probablement fin septembre), merci à @artemyk ! Voir https://github.com/pydata/pandas/pull/8062
Donc à partir de 0.15, vous pouvez spécifier le chunksize argument et par ex. faites simplement :
df.to_sql('table', engine, chunksize=20000)