J'ai mis en place un exemple de transformation (clic droit et choisissez enregistrer le lien) en fonction de ce que vous avez fourni. La seule étape sur laquelle je me sens un peu incertain est la dernière entrée de table. J'écris essentiellement les données de jointure dans la table et je les laisse échouer si une relation spécifique existe déjà.
remarque :
Cette solution ne répond pas vraiment au "Toutes les approches doivent inclure une partie de la validation et une stratégie de restauration en cas d'échec d'une insertion ou d'échec du maintien de l'intégrité référentielle". critères, bien qu'il n'échouera probablement pas. Si vous voulez vraiment configurer quelque chose de complexe, nous pouvons le faire, mais cela devrait certainement vous permettre de démarrer avec ces transformations.

Flux de données par étape
1. Nous commençons par lire dans votre dossier. Dans mon cas, je l'ai converti en CSV mais l'onglet est bien aussi. 
2. Nous allons maintenant insérer les noms des employés dans la table Employee en utilisant une combination lookup/update .Après l'insertion, nous ajoutons l'employee_id à notre flux de données en tant que id et supprimez le EmployeeName du flux de données.

3. Ici, nous utilisons simplement une étape Sélectionner des valeurs pour renommer le id champ à employee_id 
4. Insérez les titres de poste comme nous l'avons fait pour les employés et ajoutez l'identifiant du titre à notre flux de données en supprimant également le JobLevelHistory du flux de données.

5. Renommer simplement l'identifiant du titre en title_id (voir étape 3) 
6. Insérez des bureaux, obtenez des identifiants, supprimez OfficeHistory du flux.

7. Renommer simplement l'identifiant du bureau en office_id (voir étape 3)

8. Copiez les données de la dernière étape dans deux flux avec les valeurs employee_id,office_id et employee_id,title_id respectivement.

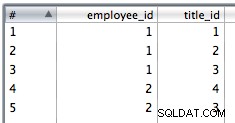
9. Utilisez une insertion de table pour insérer les données de jointure. Je l'ai sélectionné pour ignorer les erreurs d'insertion car il pourrait y avoir des doublons et les contraintes PK feront échouer certaines lignes.
Tableaux de sortie