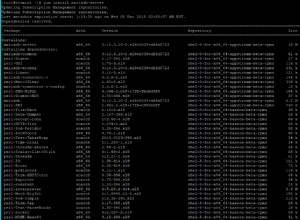
CREATE DEFINER = 'root'@'localhost'
PROCEDURE test.GetHierarchyUsers(IN StartKey INT)
BEGIN
-- prepare a hierarchy level variable
SET @hierlevel := 00000;
-- prepare a variable for total rows so we know when no more rows found
SET @lastRowCount := 0;
-- pre-drop temp table
DROP TABLE IF EXISTS MyHierarchy;
-- now, create it as the first level you want...
-- ie: a specific top level of all "no parent" entries
-- or parameterize the function and ask for a specific "ID".
-- add extra column as flag for next set of ID's to load into this.
CREATE TABLE MyHierarchy AS
SELECT U.ID
, U.Parent
, U.`name`
, 00 AS IDHierLevel
, 00 AS AlreadyProcessed
FROM
Users U
WHERE
U.ID = StartKey;
-- how many rows are we starting with at this tier level
-- START the cycle, only IF we found rows...
SET @lastRowCount := FOUND_ROWS();
-- we need to have a "key" for updates to be applied against,
-- otherwise our UPDATE statement will nag about an unsafe update command
CREATE INDEX MyHier_Idx1 ON MyHierarchy (IDHierLevel);
-- NOW, keep cycling through until we get no more records
WHILE @lastRowCount > 0
DO
UPDATE MyHierarchy
SET
AlreadyProcessed = 1
WHERE
IDHierLevel = @hierLevel;
-- NOW, load in all entries found from full-set NOT already processed
INSERT INTO MyHierarchy
SELECT DISTINCT U.ID
, U.Parent
, U.`name`
, @hierLevel + 1 AS IDHierLevel
, 0 AS AlreadyProcessed
FROM
MyHierarchy mh
JOIN Users U
ON mh.Parent = U.ID
WHERE
mh.IDHierLevel = @hierLevel;
-- preserve latest count of records accounted for from above query
-- now, how many acrual rows DID we insert from the select query
SET @lastRowCount := ROW_COUNT();
-- only mark the LOWER level we just joined against as processed,
-- and NOT the new records we just inserted
UPDATE MyHierarchy
SET
AlreadyProcessed = 1
WHERE
IDHierLevel = @hierLevel;
-- now, update the hierarchy level
SET @hierLevel := @hierLevel + 1;
END WHILE;
-- return the final set now
SELECT *
FROM
MyHierarchy;
-- and we can clean-up after the query of data has been selected / returned.
-- drop table if exists MyHierarchy;
END
Cela peut sembler fastidieux, mais pour l'utiliser, faites
call GetHierarchyUsers( 5 );
(ou quel que soit l'ID de clé pour lequel vous souhaitez trouver l'arborescence hiérarchique).
Le principe est de commencer avec la clé avec laquelle vous travaillez. Ensuite, utilisez-le comme base pour rejoindre à nouveau la table des utilisateurs, mais en fonction de l'ID PARENT de la première entrée. Une fois trouvée, mettez à jour la table temporaire pour ne pas essayer de rejoindre à nouveau cette clé lors du prochain cycle. Continuez ensuite jusqu'à ce que plus aucune clé d'identification "parente" ne soit trouvée.
Cela renverra toute la hiérarchie des enregistrements jusqu'au parent, quelle que soit la profondeur de l'imbrication. Cependant, si vous ne voulez que le parent FINAL, vous pouvez utiliser la variable @hierlevel pour ne renvoyer que le dernier dans le fichier ajouté, ou ORDER BY et LIMIT 1