Les tests de version sont généralement l'une des étapes de l'ensemble du processus de déploiement. Vous écrivez le code, puis vous vérifiez son comportement dans un environnement de staging, puis, enfin, vous déployez le nouveau code sur la production. Les bases de données sont internes à tout type d'application et, par conséquent, il est important de vérifier comment les modifications liées à la base de données modifient l'application. Il est possible de le vérifier de plusieurs manières; l'un d'eux serait d'utiliser une réplique dédiée. Voyons comment cela peut être fait.
Évidemment, vous ne voulez pas que ce processus soit manuel - il devrait faire partie des processus CI/CD de votre entreprise. Selon l'application, l'environnement et les processus exacts que vous avez en place, vous pouvez utiliser des répliques créées ad hoc ou des répliques qui font toujours partie de l'environnement de la base de données.
La façon dont Galera Cluster fonctionne est qu'il gère les changements de schéma d'une manière spécifique. Il est possible d'exécuter un changement de schéma sur un seul nœud du cluster, mais c'est délicat, car il ne prend pas en charge tous les changements de schéma possibles, et cela affectera la production en cas de problème. Un tel nœud devrait être entièrement reconstruit à l'aide de SST, ce qui signifie que l'un des nœuds Galera restants devra agir en tant que donneur et transférer toutes ses données sur le réseau.
Une alternative sera d'utiliser une réplique ou même tout un Galera Cluster supplémentaire faisant office de réplique. De toute évidence, le processus doit être automatisé afin de le brancher sur le pipeline de développement. Il existe de nombreuses façons de le faire :des scripts ou de nombreux outils d'orchestration d'infrastructure comme Ansible, Chef, Puppet ou Salt stack. Nous ne les décrirons pas en détail, mais nous aimerions que vous montriez les étapes nécessaires au bon fonctionnement de l'ensemble du processus, et nous vous laisserons la mise en œuvre dans l'un des outils.
Automatisation des tests de version
Tout d'abord, nous voulons pouvoir déployer facilement une nouvelle base de données. Il doit être provisionné avec les données récentes, et cela peut être fait de plusieurs façons - vous pouvez copier les données de la base de données de production vers le serveur de test ; c'est la chose la plus simple à faire. Alternativement, vous pouvez utiliser la sauvegarde la plus récente - une telle approche présente des avantages supplémentaires en testant la restauration de la sauvegarde. La vérification des sauvegardes est indispensable dans tout type de déploiement sérieux, et la reconstruction des configurations de test est un excellent moyen de revérifier le fonctionnement de votre processus de restauration. Cela vous aide également à chronométrer le processus de restauration - savoir combien de temps il faut pour restaurer votre sauvegarde aide à évaluer correctement la situation dans un scénario de reprise après sinistre.
Une fois les données provisionnées dans la base de données, vous souhaiterez peut-être configurer ce nœud en tant que réplica de votre cluster principal. Il a ses avantages et ses inconvénients. Si vous pouviez réexécuter tout votre trafic vers le nœud autonome, ce serait parfait - dans ce cas, il n'est pas nécessaire de configurer la réplication. Certains des équilibreurs de charge, comme ProxySQL, vous permettent de refléter le trafic et d'envoyer sa copie à un autre emplacement. D'un autre côté, la réplication est la meilleure chose à faire. Oui, vous ne pouvez pas exécuter d'écritures directement sur ce nœud, ce qui vous oblige à planifier la manière dont vous allez réexécuter les requêtes, car l'approche la plus simple consistant à simplement y répondre ne fonctionnera pas. D'autre part, toutes les écritures seront éventuellement exécutées via le thread SQL, vous n'avez donc qu'à planifier comment traiter les requêtes SELECT.
Selon le changement exact, vous pouvez tester le processus de changement de schéma. Les modifications de schéma sont assez courantes à effectuer et peuvent même avoir un impact sérieux sur les performances de la base de données. Il est donc important de les vérifier avant de les appliquer à la production. Nous voulons examiner le temps nécessaire pour exécuter le changement et vérifier si le changement peut être appliqué sur les nœuds séparément ou s'il est nécessaire d'effectuer le changement sur l'ensemble de la topologie en même temps. Cela nous indiquera quel processus nous devons utiliser pour un changement de schéma donné.
Utiliser ClusterControl pour améliorer l'automatisation des tests de version
ClusterControl est livré avec un ensemble de fonctionnalités qui peuvent être utilisées pour vous aider à automatiser les tests de version. Voyons ce qu'il propose. Pour être clair, les fonctionnalités que nous allons montrer sont disponibles de plusieurs manières. Le moyen le plus simple est d'utiliser l'interface utilisateur, mais ce que vous voulez faire n'est pas nécessaire si vous avez l'automatisation en tête. Il existe deux autres façons de le faire :l'interface de ligne de commande vers ClusterControl et l'API RPC. Dans les deux cas, les tâches peuvent être déclenchées à partir de scripts externes, ce qui vous permet de les connecter à vos processus CI/CD existants. Cela vous fera également gagner beaucoup de temps, car le déploiement du cluster peut se résumer à l'exécution d'une seule commande au lieu de le configurer manuellement.
Déployer le cluster de test
Avant tout, ClusterControl est livré avec une option pour déployer un nouveau cluster et le provisionner avec les données de la base de données existante. Cette fonctionnalité à elle seule vous permet d'implémenter facilement le provisionnement du serveur intermédiaire.
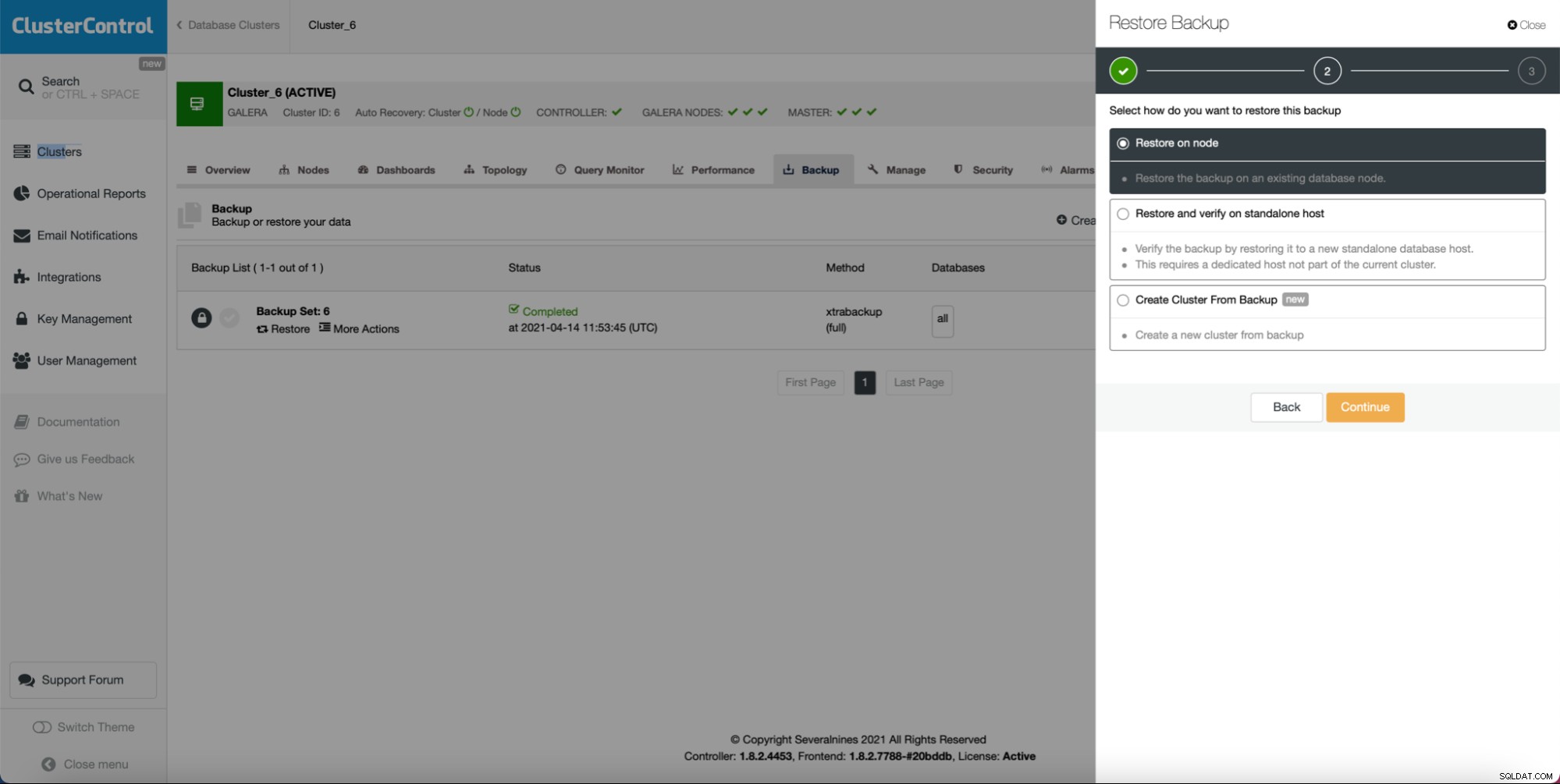
Comme vous pouvez le voir, tant que vous avez créé une sauvegarde, vous peut créer un nouveau cluster et le provisionner en utilisant les données de la sauvegarde :
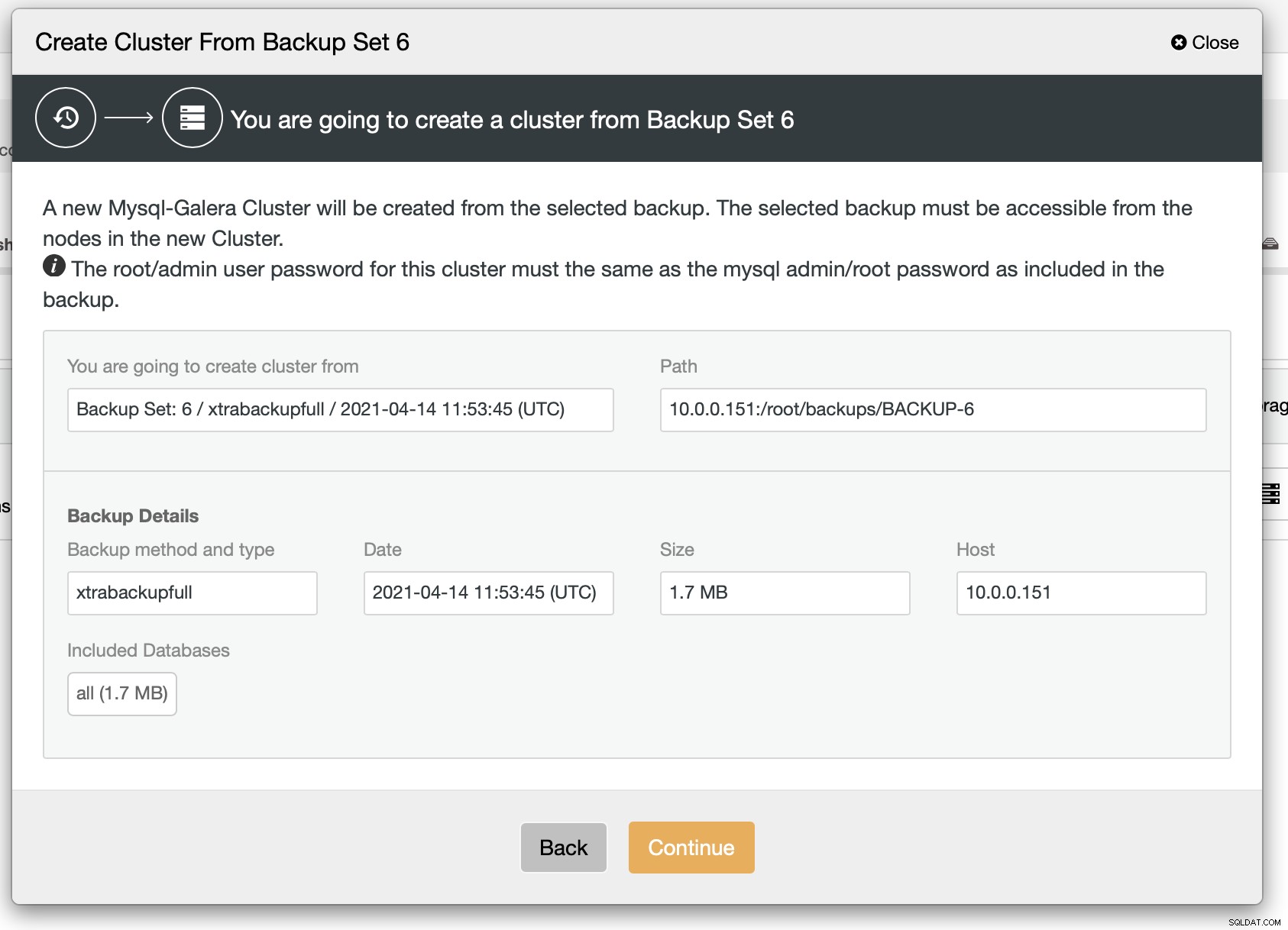
Comme nous pouvons le voir, il y a un bref résumé de ce qui va se passer. Si vous cliquez sur Continuer, vous continuerez.
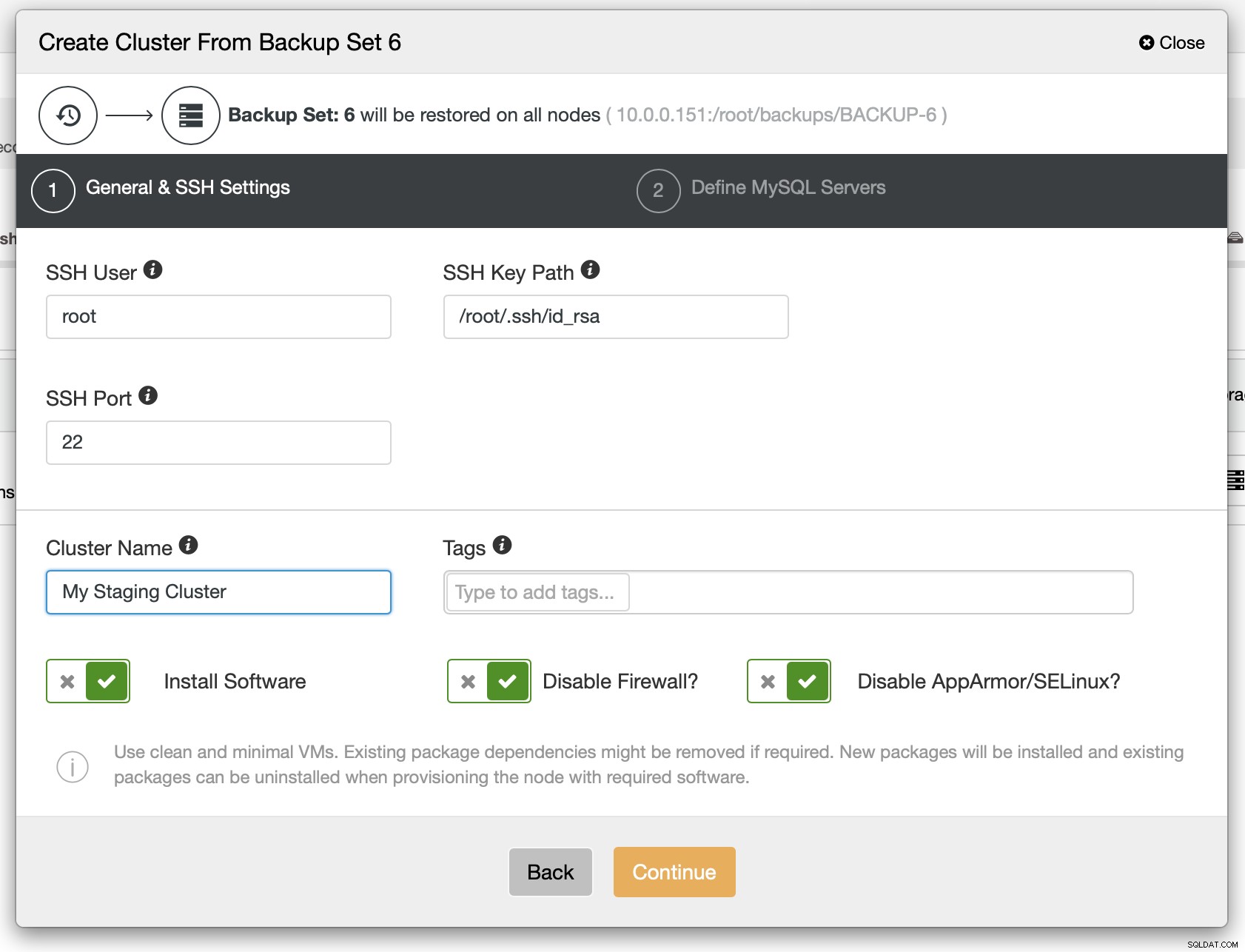
A l'étape suivante, vous devez définir la connectivité SSH - elle doit être en place avant que ClusterControl puisse déployer les nœuds.
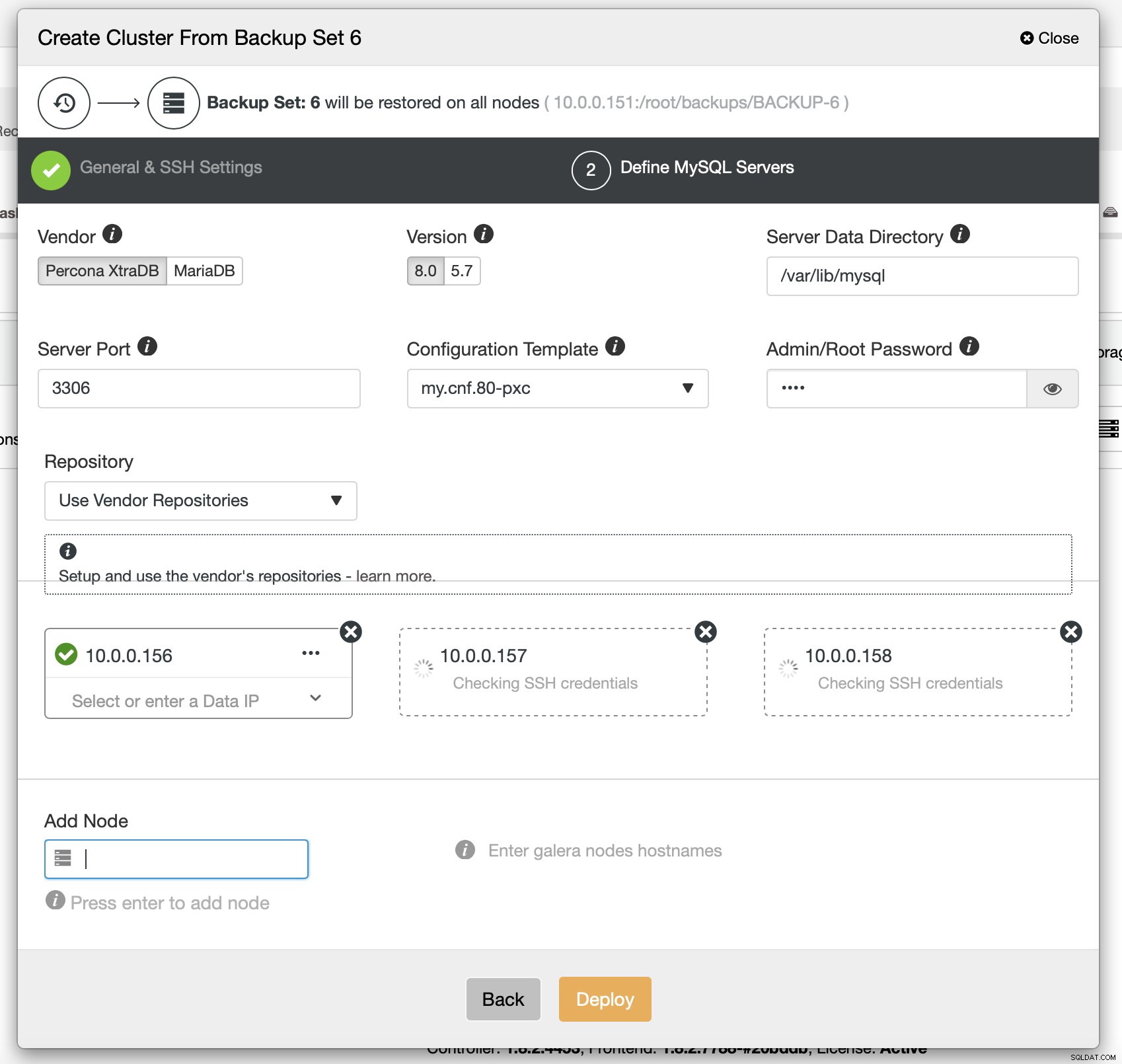
Enfin, vous devez choisir (entre autres) le fournisseur, la version et les noms d'hôte des nœuds que vous souhaitez utiliser dans le cluster. C'est juste ça.
La commande CLI qui accomplirait la même chose ressemble à ceci :
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Configurer ProxySQL pour refléter le trafic
Si nous avons déployé un cluster, nous pouvons vouloir lui envoyer le trafic de production pour vérifier comment le nouveau schéma gère le trafic existant. Une façon de le faire est d'utiliser ProxySQL.
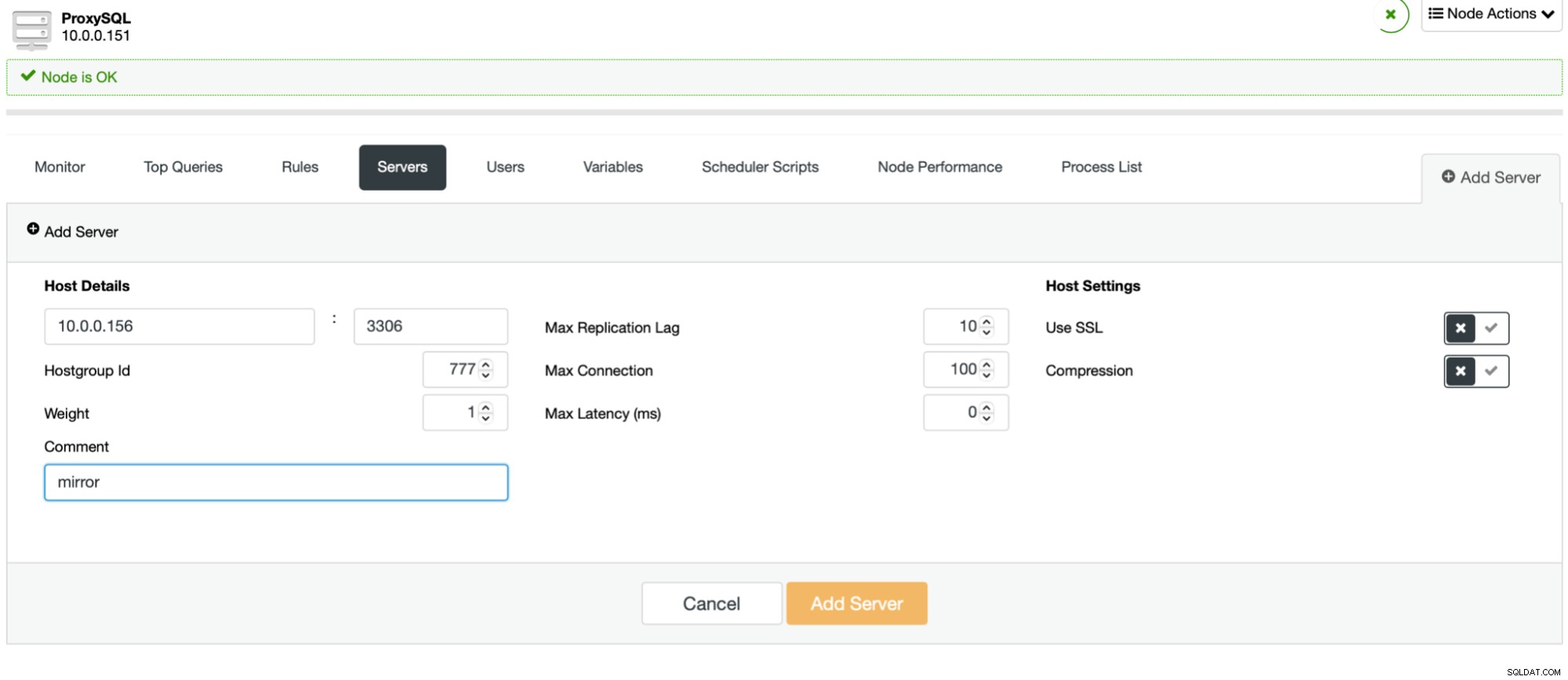
Le processus est simple. Tout d'abord, vous devez ajouter les nœuds à ProxySQL. Ils doivent appartenir à un groupe d'hôtes distinct qui n'est pas encore utilisé. Assurez-vous que l'utilisateur du moniteur ProxySQL pourra y accéder.
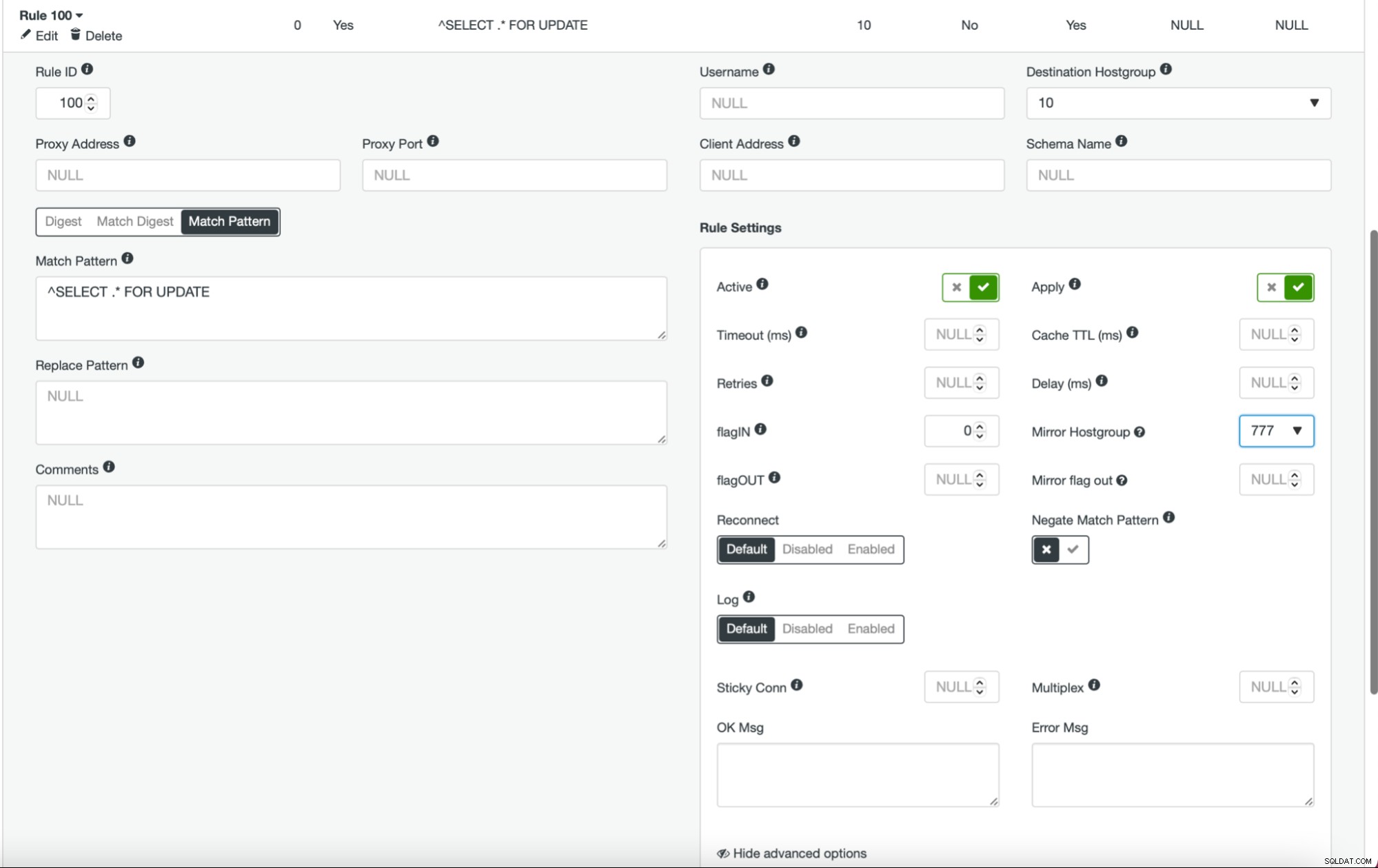
Une fois que cela est fait et que tous (ou certains) de vos nœuds sont configurés dans le groupe d'hôtes, vous pouvez modifier les règles de requête et définir le groupe d'hôtes miroir (il est disponible dans les options avancées). Si vous souhaitez le faire pour tout le trafic, vous souhaiterez probablement modifier toutes vos règles de requête de cette manière. Si vous souhaitez mettre en miroir uniquement les requêtes SELECT, vous devez modifier les règles de requête appropriées. Une fois cette opération effectuée, votre cluster intermédiaire devrait commencer à recevoir le trafic de production.
Déployer le cluster en tant qu'esclave
Comme nous en avons discuté précédemment, une solution alternative serait de créer un nouveau cluster qui agira comme une réplique de la configuration existante. Avec une telle approche, nous pouvons tester automatiquement toutes les écritures, en utilisant la réplication. Les SELECT peuvent être testés en utilisant l'approche décrite ci-dessus - mise en miroir via ProxySQL.
Le déploiement d'un cluster esclave est assez simple.
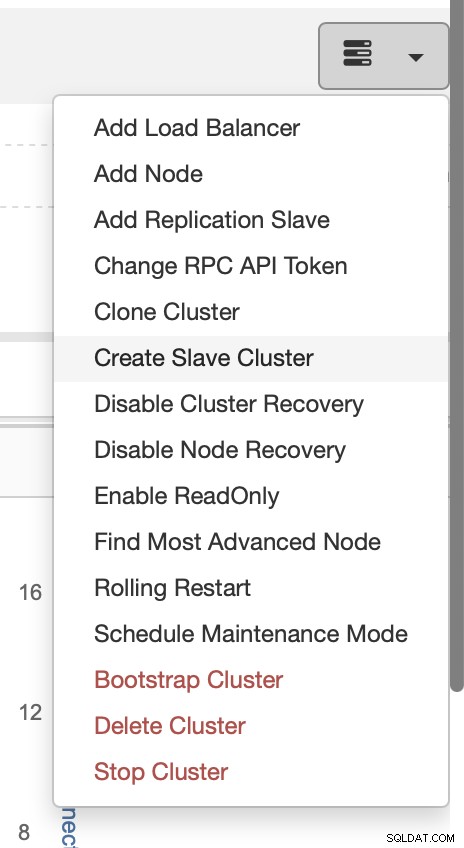
Choisissez la tâche Créer un cluster esclave.
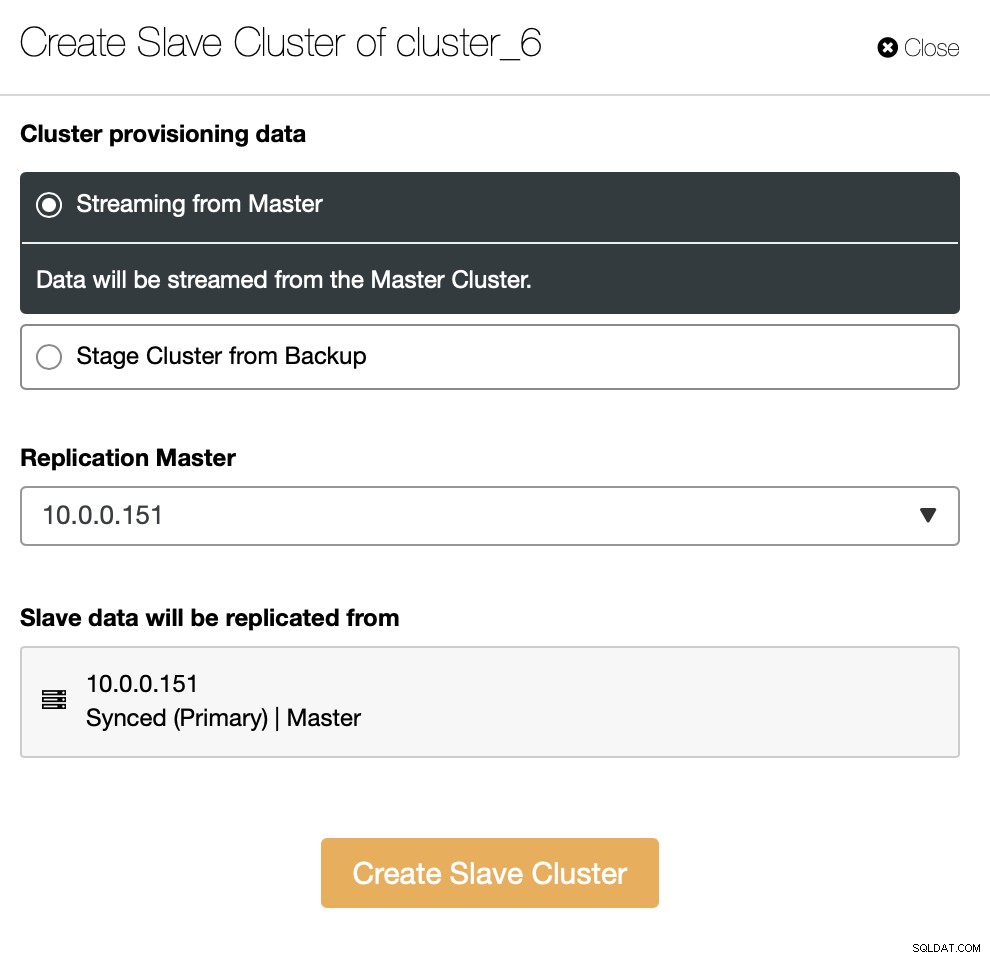
Vous devez décider comment vous voulez que la réplication soit définie. Vous pouvez faire transférer toutes les données du maître vers les nouveaux nœuds.
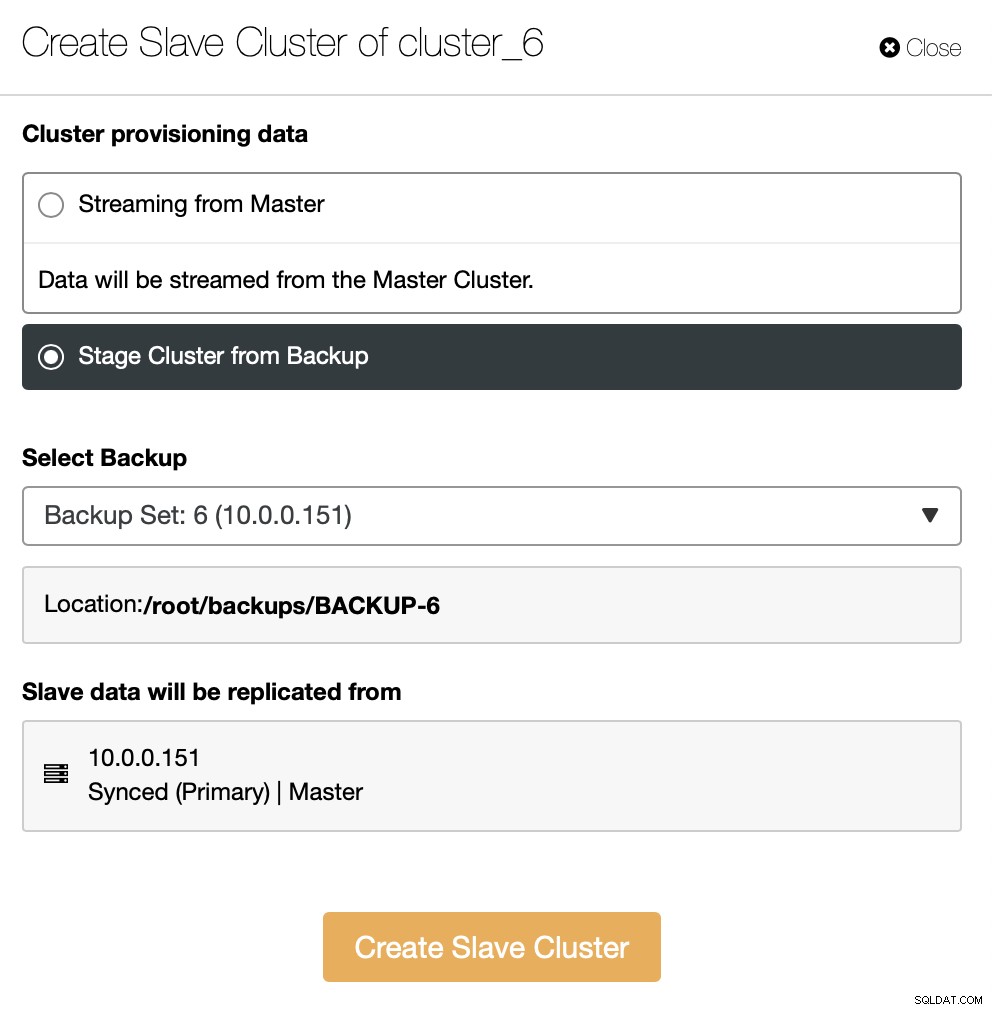
Vous pouvez également utiliser une sauvegarde existante pour provisionner le nouveau cluster. Cela aidera à réduire la charge de travail sur le nœud maître - au lieu de transférer toutes les données, seules les transactions qui ont été exécutées entre le moment où la sauvegarde a été créée et le moment où la réplication a été configurée devront être transférées.
Le reste consiste à suivre l'assistant de déploiement standard, en définissant la connectivité SSH, la version, le fournisseur, les hôtes, etc. Une fois déployé, vous verrez le cluster dans la liste.
Une solution alternative à l'interface utilisateur consiste à accomplir cela via RPC.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Aller de l'avant
Si vous souhaitez en savoir plus sur les façons dont vous pouvez intégrer vos processus avec le ClusterControl, nous aimerions vous diriger vers la documentation, où nous avons une section entière sur le développement de solutions où ClusterControl joue un rôle rôle important :
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Nous espérons que vous avez trouvé ce court blog instructif et utile. Si vous avez des questions concernant l'intégration de ClusterControl dans votre environnement, veuillez nous contacter et nous ferons de notre mieux pour vous aider.