La réplication hybride, c'est-à-dire combinant Galera et la réplication MySQL asynchrone dans la même configuration, est devenue beaucoup plus facile depuis l'introduction de GTID dans MySQL 5.6. Bien qu'il soit assez simple de répliquer d'un serveur MySQL autonome vers un cluster Galera, le faire dans l'autre sens (Galera → MySQL autonome) était un peu plus difficile. Au moins jusqu'à l'arrivée de GTID.
Il y a quelques bonnes raisons d'attacher un esclave asynchrone à un cluster Galera. D'une part, les requêtes de type reporting/OLAP de longue durée sur un nœud Galera peuvent ralentir un cluster entier, si la charge de reporting est si intense que le nœud doit déployer des efforts considérables pour y faire face. Ainsi, les requêtes de rapport peuvent être envoyées à un serveur autonome, isolant efficacement Galera de la charge de rapport. Dans une approche ceintures et bretelles, un esclave asynchrone peut également servir de sauvegarde en direct à distance.
Dans cet article de blog, nous vous montrerons comment répliquer un cluster Galera sur un serveur MySQL avec GTID et comment basculer la réplication en cas de défaillance du nœud maître.
Réplication hybride dans MySQL 5.5
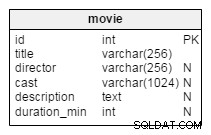
Dans MySQL 5.5, la reprise d'une réplication interrompue nécessite que vous déterminiez le dernier fichier journal binaire et sa position, qui sont distincts sur tous les nœuds Galera si la journalisation binaire est activée. Nous pouvons illustrer cette situation avec la figure suivante :
 Topologie esclave asynchrone du cluster Galera sans GTID
Topologie esclave asynchrone du cluster Galera sans GTID Si le maître MySQL tombe en panne, la réplication s'interrompt et l'esclave devra basculer vers un autre maître. Vous devrez choisir un nouveau nœud Galera et déterminer manuellement un nouveau fichier journal binaire et la position de la dernière transaction exécutée par l'esclave. Une autre option consiste à vider les données du nouveau nœud maître, à les restaurer sur l'esclave et à démarrer la réplication avec le nouveau nœud maître. Ces options sont bien sûr réalisables, mais peu pratiques en production.
Comment GTID résout le problème
GTID (Global Transaction Identifier) fournit un meilleur mappage des transactions entre les nœuds et est pris en charge dans MySQL 5.6. Dans Galera Cluster, tous les nœuds généreront différents fichiers binlog. Les événements binlog sont identiques et dans le même ordre, mais les noms et décalages des fichiers binlog peuvent varier. Avec GTID, les esclaves peuvent voir une transaction unique provenant de plusieurs maîtres et cela pourrait facilement être mappé dans la liste d'exécution des esclaves s'il doit redémarrer ou reprendre la réplication.
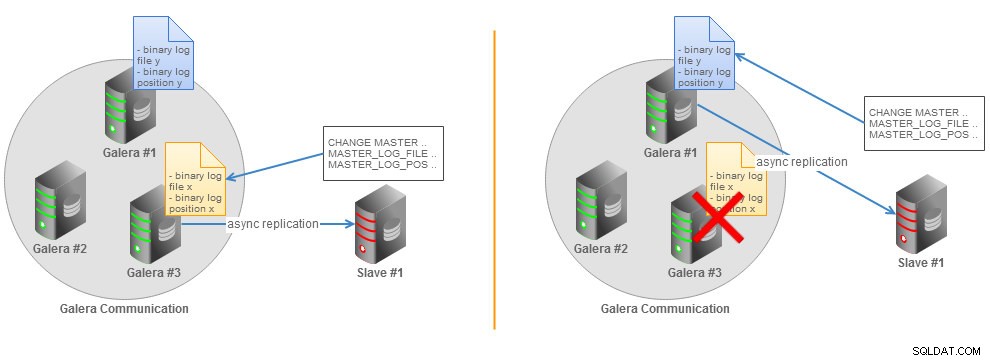
 Topologie esclave asynchrone du cluster Galera avec basculement GTID
Topologie esclave asynchrone du cluster Galera avec basculement GTID Toutes les informations nécessaires à la synchronisation avec le maître sont obtenues directement à partir du flux de réplication. Cela signifie que lorsque vous utilisez des GTID pour la réplication, vous n'avez pas besoin d'inclure les options MASTER_LOG_FILE ou MASTER_LOG_POS dans l'instruction CHANGE MASTER TO. Au lieu de cela, il suffit d'activer l'option MASTER_AUTO_POSITION. Vous pouvez trouver plus de détails sur le GTID dans la page de documentation MySQL.
Configuration manuelle de la réplication hybride
Assurez-vous que les nœuds Galera (maîtres) et les esclaves fonctionnent sur MySQL 5.6 avant de procéder à cette configuration. Nous avons une base de données appelée sbtest dans Galera, que nous répliquerons sur le nœud esclave.
1. Activez les options de réplication requises en spécifiant les lignes suivantes dans le fichier my.cnf de chaque nœud de base de données (y compris le nœud esclave) :
Pour les nœuds maîtres (Galera) :
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=1 # 1 for master1, 2 for master2, 3 for master3
binlog_format=ROWPour le nœud esclave :
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=101 # 101 for slave
binlog_format=ROW
replicate_do_db=sbtest
slave_net_timeout=602. Effectuez un redémarrage progressif du cluster Galera Cluster (depuis ClusterControl UI> Gérer> Mettre à niveau> Redémarrage progressif). Cela rechargera chaque nœud avec les nouvelles configurations et activera GTID. Redémarrez également l'esclave.
3. Créez un utilisateur de réplication esclave et exécutez l'instruction suivante sur l'un des nœuds Galera :
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slavepassword';4. Connectez-vous à la base de données esclave et videz sbtest depuis l'un des nœuds Galera :
$ mysqldump -uroot -p -h192.168.0.201 --single-transaction --skip-add-locks --triggers --routines --events sbtest > sbtest.sql5. Restaurez le fichier de vidage sur le serveur esclave :
$ mysql -uroot -p < sbtest.sql6. Démarrez la réplication sur le nœud esclave :
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.201', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Pour vérifier que la réplication s'exécute correctement, examinez la sortie de l'état de l'esclave :
mysql> SHOW SLAVE STATUS\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...Configuration de la réplication hybride à l'aide de ClusterControl
Dans le paragraphe précédent, nous avons décrit toutes les étapes nécessaires pour activer les journaux binaires, redémarrer le cluster nœud par nœud, copier les données, puis configurer la réplication. La procédure est une tâche fastidieuse et vous pouvez facilement faire des erreurs dans l'une de ces étapes. Dans ClusterControl, nous avons automatisé toutes les étapes nécessaires.
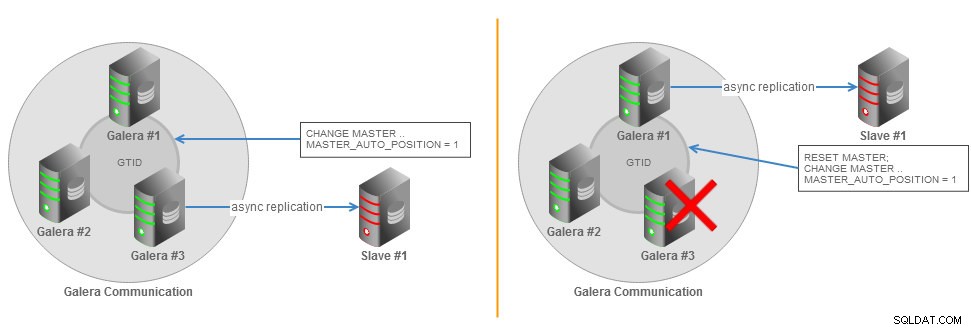
1. Pour les utilisateurs de ClusterControl, vous pouvez accéder aux nœuds de la page Nœuds et activer la journalisation binaire.
 Activer la journalisation binaire sur le cluster Galera à l'aide de ClusterControl
Activer la journalisation binaire sur le cluster Galera à l'aide de ClusterControl Cela ouvrira une boîte de dialogue qui vous permettra de définir l'expiration du journal binaire, d'activer le GTID et le redémarrage automatique.
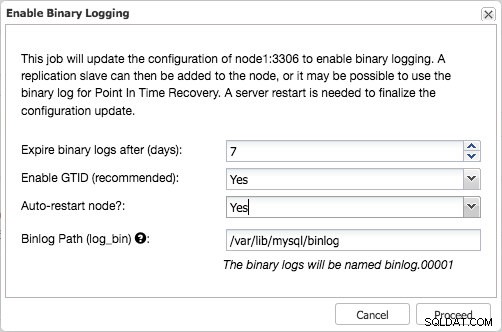 Activer la journalisation binaire avec GTID activé
Activer la journalisation binaire avec GTID activé Cela lance une tâche, qui écrira en toute sécurité ces modifications dans la configuration, créera des utilisateurs de réplication avec les autorisations appropriées et redémarrera le nœud en toute sécurité.
 Description de la photo
Description de la photo Répétez ce processus pour chaque nœud Galera du cluster, jusqu'à ce que tous les nœuds indiquent qu'ils sont maîtres.
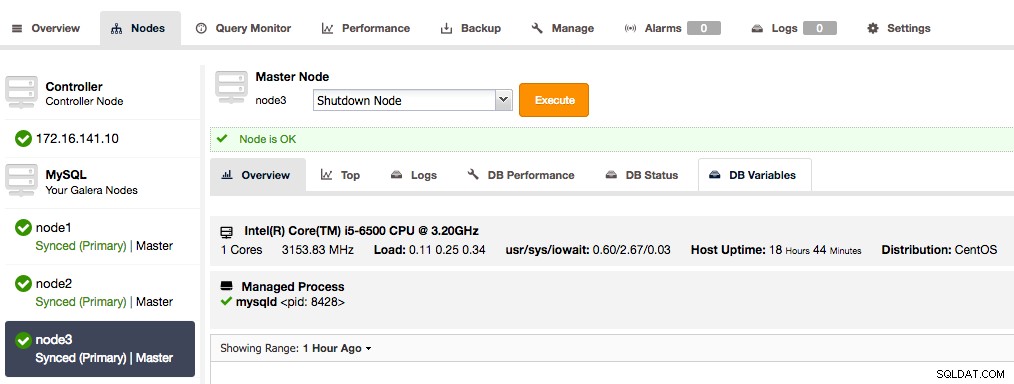 Tous les nœuds Galera Cluster sont désormais maîtres
Tous les nœuds Galera Cluster sont désormais maîtres 2. Ajouter l'esclave de réplication asynchrone au cluster
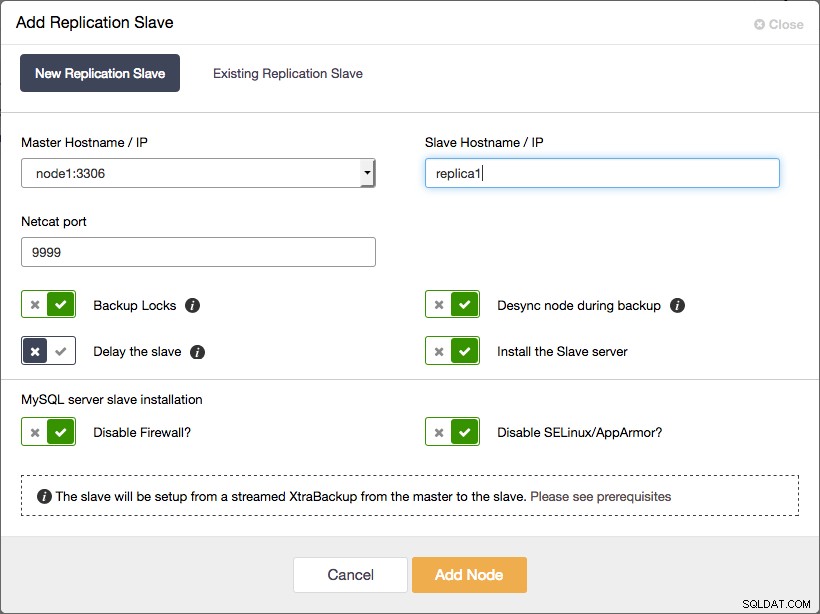 Ajout d'un esclave de réplication asynchrone à Galera Cluster à l'aide de ClusterControl
Ajout d'un esclave de réplication asynchrone à Galera Cluster à l'aide de ClusterControl Et c'est tout ce que vous avez à faire. L'ensemble du processus décrit dans le paragraphe précédent a été automatisé par ClusterControl.
Changer de maître
Si le maître désigné tombe en panne, l'esclave réessayera de se reconnecter à nouveau avec la valeur slave_net_timeout (notre configuration est de 60 secondes - la valeur par défaut est de 1 heure). Vous devriez voir l'erreur suivante sur l'état de l'esclave :
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 1Étant donné que nous utilisons Galera avec GTID activé, le basculement principal est pris en charge via ClusterControl lors de la récupération automatique du cluster et du nœud a été activé. Que le maître échoue en raison de la connectivité réseau ou pour toute autre raison, ClusterControl basculera automatiquement vers l'autre nœud maître le plus approprié du cluster.
Si vous souhaitez effectuer le basculement manuellement, changez simplement le nœud maître comme suit :
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Dans certains cas, vous pouvez rencontrer une erreur "Entrée en double .. pour la clé" après la modification du nœud maître :
Last_Errno: 1062
Last_Error: Could not execute Write_rows event on table sbtest.sbtest; Duplicate entry '1089775' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysqld-bin.000009, end_log_pos 85789000Dans les anciennes versions de MySQL, vous pouvez simplement utiliser SET GLOBAL SQL_SLAVE_SKIP_COUNTER =n pour ignorer les instructions, mais cela ne fonctionne pas avec GTID. Miguel de Percona a écrit un excellent article de blog sur la façon de réparer cela en injectant des transactions vides.
Une autre approche, pour les bases de données plus petites, pourrait également consister à simplement obtenir un nouveau vidage à partir de l'un des nœuds Galera disponibles, à le restaurer et à utiliser l'instruction RESET MASTER :
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> DROP SCHEMA sbtest; CREATE SCHEMA sbtest; USE sbtest;
mysql> SOURCE /root/sbtest_from_galera2.sql; -- repeat step #4 above to get this dump
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Vous pouvez également utiliser pt-table-checksum pour vérifier l'intégrité de la réplication, plus d'informations dans cet article de blog.
Remarque :Étant donné que dans la réplication MySQL, l'applicateur esclave est toujours monothread par défaut, ne vous attendez pas à ce que les performances de la réplication asynchrone soient les mêmes que celles de la réplication parallèle de Galera. Pour MySQL 5.6 et 5.7, il existe des options pour que la réplication asynchrone soit exécutée en parallèle sur les nœuds esclaves, mais en principe, cette réplication dépend toujours de l'ordre correct des transactions à l'intérieur du même schéma. Si la charge de réplication est intensive et continue, le retard de l'esclave ne fera que croître. Nous avons vu des cas où l'esclave ne pouvait jamais rattraper le maître.