Si vous aviez un massif problèmes avec votre approche, il vous manque très probablement un index sur la colonne clean.id , qui est requis pour votre approche lorsque le MERGE utilise dual comme source pour chaque ligne.
C'est moins probable lorsque vous prononcez le id est une clé primaire .
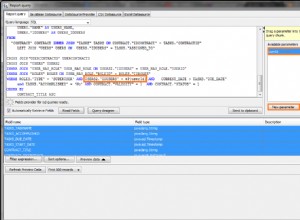
Donc essentiellement vous faites la bonne réflexion et vous verrez plan d'exécution similaire à celui ci-dessous :
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | | | 2 (100)| |
| 1 | MERGE | CLEAN | | | | |
| 2 | VIEW | | | | | |
| 3 | NESTED LOOPS OUTER | | 1 | 40 | 2 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | DUAL | 1 | 2 | 2 (0)| 00:00:01 |
| 5 | VIEW | VW_LAT_A18161FF | 1 | 38 | 0 (0)| |
| 6 | TABLE ACCESS BY INDEX ROWID| CLEAN | 1 | 38 | 0 (0)| |
|* 7 | INDEX UNIQUE SCAN | CLEAN_UX1 | 1 | | 0 (0)| |
---------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
7 - access("CLEAN"."ID"=:ID)
Le plan d'exécution est donc correct et fonctionne efficacement, mais il a un problème.
N'oubliez pas que vous utilisez toujours un index, vous serez heureux de traiter quelques lignes, mais il ne sera pas mis à l'échelle .
Si vous traitez un millions des enregistrements, vous pouvez revenir à un traitement en deux étapes,
-
insérer toutes les lignes dans une table temporaire
-
effectuer un seul
MERGEinstruction utilisant la table temporaire
Le grand avantage est qu'Oracle peut ouvrir une hash join et se débarrasser de l'accès à l'index pour chacun des millions lignes.
Voici un exemple de test du clean table initiée avec 1M id (non illustré) et effectuant des insertions 1M et des mises à jour 1M :
n = 1000000
data2 = [{"id" : i, "xcount" :1} for i in range(2*n)]
sql3 = """
insert into tmp (id,count)
values (:id,:xcount)"""
sql4 = """MERGE into clean USING tmp on (clean.id = tmp.id)
when not matched then insert (id, count) values (tmp.id, tmp.count)
when matched then update set clean.count= clean.count + tmp.count"""
cursor.executemany(sql3, data2)
cursor.execute(sql4)
Le test dure env. 10 secondes, soit moins de la moitié de votre approche avec MERGE en utilisant dual .
Si cela ne suffit toujours pas, vous devrez utiliser l'option parallèle .