Ce message fait partie du didacticiel Oracle SQL et nous discuterons des fonctions analytiques dans oracle (Over by partition) avec des exemples et des explications détaillées.
Nous avons déjà étudié la fonction Oracle Aggregate comme avg, sum, count. Prenons un exemple
Commençons par créer les exemples de données
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Maintenant, l'exemple des fonctions d'agrégation sera donné comme ci-dessous
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Ici, nous pouvons voir que cela réduit le nombre de lignes dans chacune des requêtes. Maintenant, la question est de savoir quoi faire si nous devons également renvoyer toutes les lignes avec count (*)
Pour cet oracle a fourni un ensemble de fonctions analytiques. Donc, pour résoudre le dernier problème, nous pouvons écrire comme
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
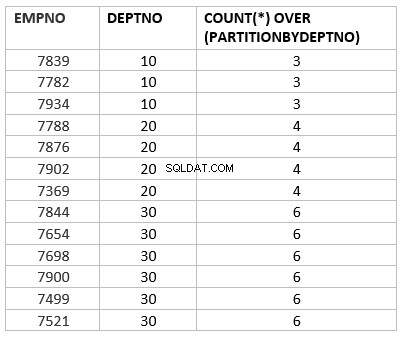
Ici count(*) over (partition by dept_no) est la version analytique de la fonction d'agrégation count. Le travail clé principal qui est différent selon la fonction d'agrégation est sur la partition par
Les fonctions analytiques calculent une valeur agrégée en fonction d'un groupe de lignes. Elles diffèrent des fonctions d'agrégation en ce sens qu'elles renvoient plusieurs lignes pour chaque groupe. Le groupe de lignes est appelé une fenêtre et est défini par la clause analytic_clause.
Voici la syntaxe générale
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Exemple
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Passons en revue chaque partie
query_partition_clause
Il définit le groupe de lignes. Il peut aimer ci-dessous
partition par deptno :groupe de lignes de même deptno
ou
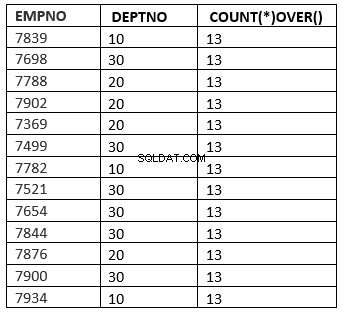
() :Toutes les lignes
SQL> select empno ,deptno , count(*) over () from emp;
[ order_by_clause [ windowing_clause ] ]
Cette clause est utilisée lorsque vous souhaitez ordonner les lignes dans la partition. Ceci est particulièrement utile si vous souhaitez que la fonction analytique considère l'ordre des lignes.
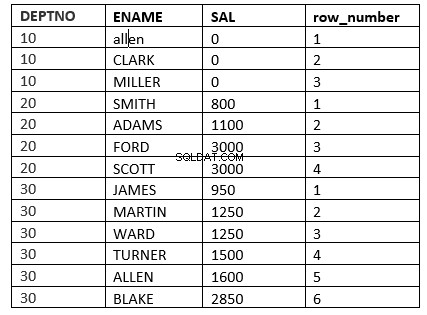
L'exemple sera la fonction row_number
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
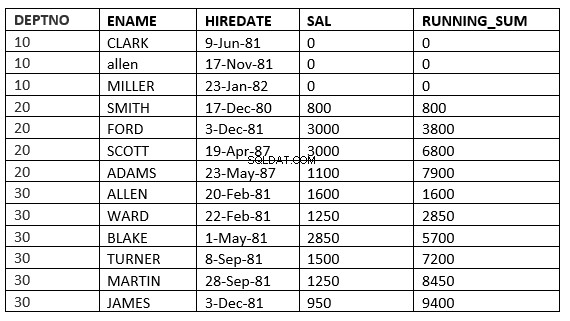
Un autre exemple serait
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Clause_fenêtre
Ceci est toujours utilisé avec la clause order by et donne plus de contrôle sur l'ensemble des lignes du groupe
Avec la clause Windowing, pour chaque ligne, une fenêtre glissante de lignes est définie. La fenêtre détermine la plage de lignes utilisées pour effectuer les calculs pour la ligne actuelle. La taille des fenêtres peut être basée sur un nombre physique de lignes ou sur un intervalle logique tel que le temps.
Lors de l'utilisation de la clause order by et que rien n'est donné pour windowing_clause, la valeur inférieure par défaut de windowing_clause est prise
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ou RANGE UNBOUNDED PRECEDING partition sont les lignes qui doivent être utilisées dans le calcul”
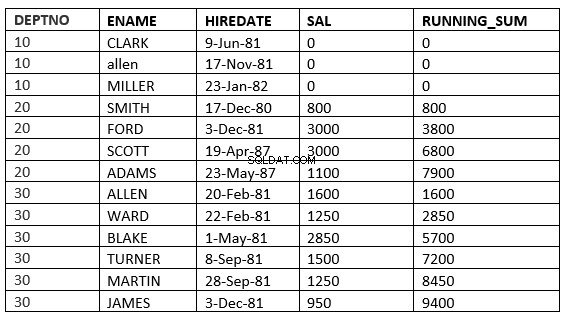
L'exemple ci-dessous le dit clairement. Cela correspond à la moyenne mobile du département
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Désormais, windowing_clause peut être défini de plusieurs façons
Comprenons d'abord la terminologie
LIGNES spécifie la fenêtre en unités physiques (lignes).
RANGE spécifie la fenêtre comme décalage logique. la clause de fenêtrage RANGE ne peut être utilisée qu'avec les clauses ORDER BY contenant des colonnes ou des expressions de types de données numériques ou de date
PRECEDING – obtenir les lignes avant la ligne actuelle.
SUIVANT – obtenir les lignes après la ligne actuelle.
UNBOUNDED – lorsqu'il est utilisé avec PRECEDING ou FOLLOWING, il renvoie tout avant ou après. LIGNE ACTUELLE
Il est donc généralement défini comme
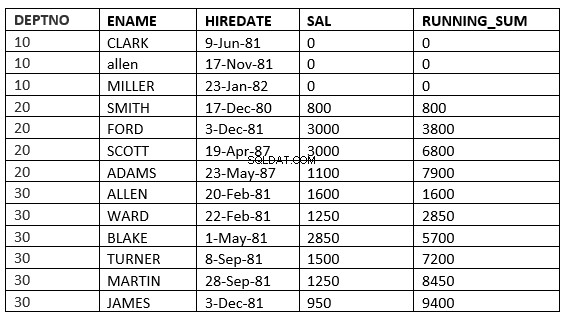
LIGNES PRÉCÉDENTES NON LIMITÉES :Les lignes actuelles et précédentes de la partition actuelle sont les lignes qui doivent être utilisées dans le calcul
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
RANGE UNBOUNDED PRECEDING :Les lignes actuelles et précédentes de la partition actuelle sont les lignes qui doivent être utilisées dans le calcul. De plus, puisque la plage est spécifiée, tout prend les valeurs qui sont égales aux lignes actuelles.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
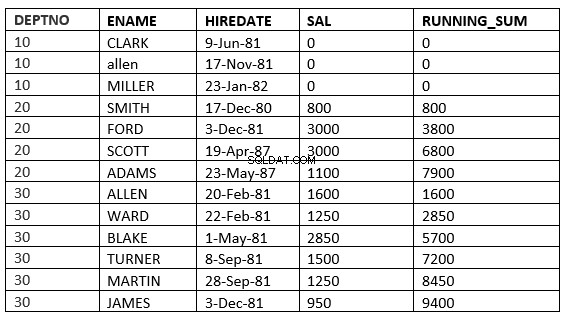
Il se peut que vous ne voyiez pas la différence entre la plage et les lignes car la date de location est différente pour tous. La différence deviendra plus claire si nous utilisons sal comme clause order by
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
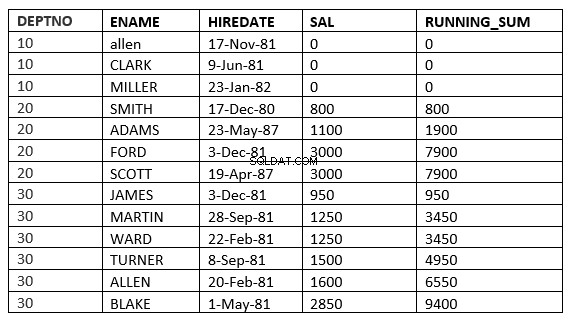
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
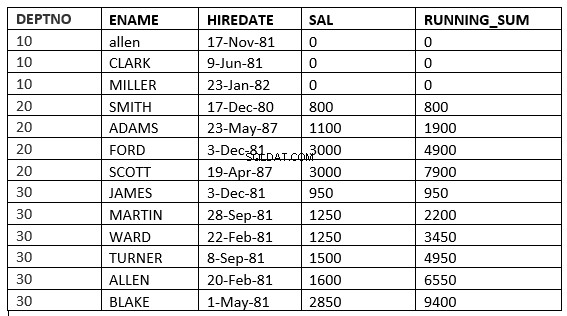
Vous pouvez trouver la différence à la ligne 6
RANGE value_expr PRECEDING :La fenêtre commence par la ligne dont la valeur ORDER BY est une expression numérique lignes inférieures ou précédant la ligne actuelle et se termine par la ligne actuelle en cours de traitement.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
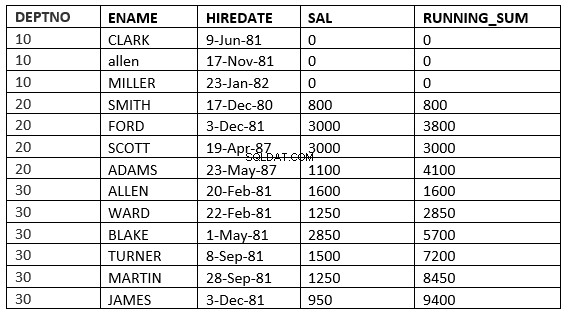
Ici, il prend toutes les lignes où la valeur de l'embauche tombe dans les 365 jours précédant la valeur de l'embauche de la ligne actuelle
ROWS value_expr PRECEDING :La fenêtre commence par la ligne donnée et se termine par la ligne en cours de traitement
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
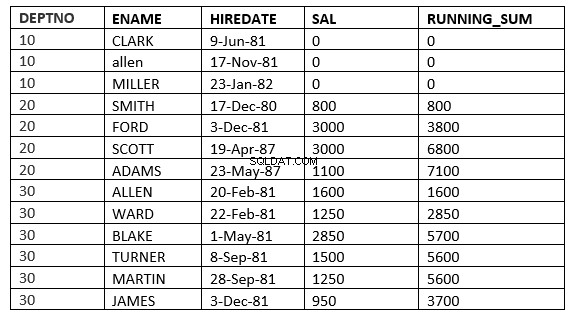
Ici la fenêtre commence à partir de 2 lignes précédant la ligne courante
RANGE BETWEEN CURRENT ROW et value_expr FOLLOWING :La fenêtre commence par la ligne actuelle et se termine par la ligne dont la valeur ORDER BY est l'expression numérique lignes inférieures à ou suivantes
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
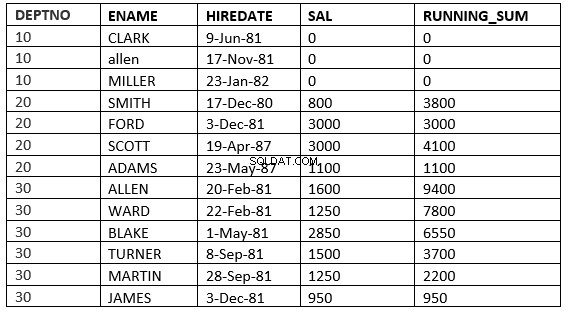
LIGNES ENTRE LA LIGNE ACTUELLE et value_expr SUIVANT :La fenêtre commence par la ligne courante et se termine par les lignes après la ligne courante
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
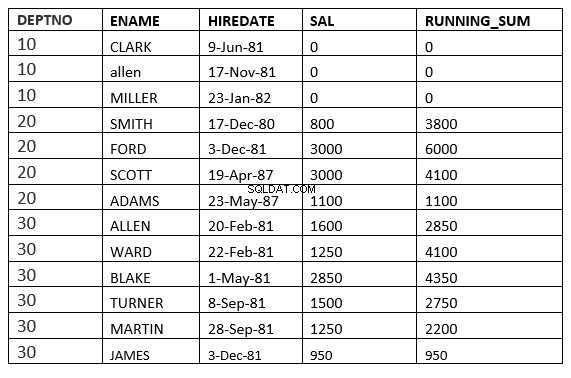
GAMME ENTRE UNBOUNDED PRECEDING et UNBOUNDED FOLLOWING
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
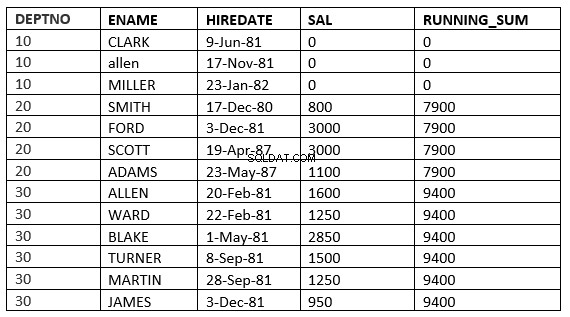
PLAGE ENTRE value_expr PRECEDING et value_expr FOLLOWING
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Quelques remarques importantes
(1)Les fonctions analytiques sont le dernier ensemble d'opérations effectuées dans une requête, à l'exception de la clause ORDER BY finale. Toutes les jointures et toutes les clauses WHERE, GROUP BY et HAVING sont terminées avant le traitement des fonctions analytiques. Par conséquent, les fonctions analytiques ne peuvent apparaître que dans la liste de sélection ou la clause ORDER BY.
(2)Les fonctions analytiques sont couramment utilisées pour calculer des agrégats cumulatifs, mobiles, centrés et de rapport.
J'espère que vous aimez cette explication détaillée des fonctions analytiques dans oracle (sur par Partition Clause)
Articles connexes
Fonction LEAD dans Oracle
Fonction DENSE dans Oracle
Fonction Oracle LISTAGG
Agrégation de données à l'aide de fonctions de groupe
https://docs.oracle.com/cd/E11882_01/ serveur.112/e41084/fonctions004.htm