Maintenant, notre communauté d'analyse de données volumineuses a commencé à utiliser Apache Spark à plein régime pour le traitement de données volumineuses. Le traitement peut s'appliquer aux requêtes ad hoc, aux requêtes prédéfinies, au traitement de graphes, à l'apprentissage automatique et même au streaming de données.
Par conséquent, la compréhension de Spark Job Submission est très vitale pour la communauté. Étendre à cela heureux de partager avec vous les apprentissages des étapes impliquées dans la soumission de travail Apache Spark.
Fondamentalement, il comporte deux étapes,

Soumission de travail
Le travail Spark est soumis automatiquement lorsqu'une action telle que count () est effectuée sur un RDD.
RunJob() en interne doit être appelé sur le SparkContext, puis appelé le planificateur qui s'exécute dans le cadre du dérivé.
/> Le planificateur est composé de 2 parties :le planificateur DAG et le planificateur de tâches.
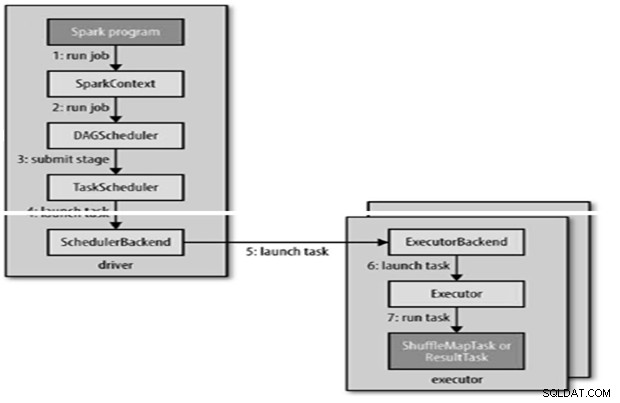
Construction DAG
Il existe deux types de constructions DAG,

- Le travail Spark simple est celui qui n'a pas besoin d'être mélangé et n'a donc qu'une seule étape composée de tâches de résultat, comme le travail de carte uniquement dans MapReduce
- La tâche Spark complexe implique le regroupement d'opérations et nécessite une ou plusieurs étapes de remaniement.
- Le planificateur DAG de Spark transforme la tâche en deux étapes.
- Le planificateur DAG est chargé de diviser une étape en tâches à soumettre au planificateur de tâches.
- Chaque tâche se voit attribuer une préférence de placement par le planificateur DAG pour permettre au planificateur de tâches de tirer parti de la localité des données.
- Les étapes enfants ne sont soumises qu'une fois que leurs parents ont terminé avec succès.
Planification des tâches
- Le planificateur de tâches enverra un ensemble de tâches ; il utilise sa liste d'exécuteurs en cours d'exécution pour l'application et construit un mappage des tâches aux exécuteurs qui prend en compte les préférences de placement.
- Le planificateur de tâches attribue aux exécuteurs qui ont des cœurs libres, chaque tâche se voit allouer un cœur par défaut. Il peut être modifié par le paramètre spark.task.cpus.
- Spark utilise Akka, qui est une plate-forme basée sur des acteurs pour créer des applications distribuées hautement évolutives basées sur des événements.
- Spark n'utilise pas Hadoop RPC pour les appels à distance.
Exécution de la tâche
Un exécuteur exécute une tâche comme suit,
- Il s'assure que le JAR et les dépendances de fichiers pour la tâche sont à jour.
- Désérialise le code de tâche.
- Le code de la tâche est exécuté.
- La tâche renvoie les résultats au pilote, qui les assemble en un résultat final à renvoyer à l'utilisateur.
Référence
- Le guide définitif Hadoop
- Communauté Open Source Analytics et Big Data
Cet article a été initialement publié ici. Republié avec autorisation. Soumettez vos réclamations pour atteinte aux droits d'auteur ici.