Dans le précédent article de blog, nous avons couvert les bases de la mise à l'échelle - qu'est-ce que c'est, quels sont les types, qu'est-ce qui est indispensable si nous voulons évoluer. Cet article de blog se concentrera sur les défis et les moyens par lesquels nous pouvons évoluer.
Défi de la montée en charge
La mise à l'échelle des bases de données n'est pas la tâche la plus facile pour plusieurs raisons. Concentrons-nous un peu sur les défis liés à la mise à l'échelle de votre infrastructure de base de données.
Service avec état
Nous pouvons distinguer deux types de services différents :sans état et avec état. Les services sans état sont ceux qui ne reposent sur aucun type de données existantes. Vous pouvez simplement aller de l'avant, démarrer un tel service et cela fonctionnera avec plaisir. Vous n'avez pas à vous soucier de l'état des données ni du service. S'il est activé, il fonctionnera correctement et vous pourrez facilement répartir le trafic sur plusieurs instances de service simplement en ajoutant plus de clones ou de copies de machines virtuelles, de conteneurs ou similaires existants. Un exemple d'un tel service peut être une application Web - déployée à partir du dépôt, ayant un serveur Web correctement configuré, ce service démarrera et fonctionnera correctement.
Le problème avec les bases de données est que la base de données est tout sauf sans état. Les données doivent être insérées dans la base de données, elles doivent être traitées et conservées. L'image de la base de données n'est rien de plus que quelques packages installés sur l'image du système d'exploitation et, sans données et configuration appropriée, elle est plutôt inutile. Cela ajoute à la complexité de la mise à l'échelle de la base de données. Pour les services sans état, il suffit de les déployer et de configurer certains équilibreurs de charge pour inclure de nouvelles instances dans la charge de travail. Pour les bases de données qui déploient la base de données, l'instance n'est que le point de départ. Plus loin dans la voie se trouve la gestion des données - vous devez transférer les données de votre instance de base de données existante vers la nouvelle. Cela peut représenter une partie importante du problème et du temps nécessaire aux nouvelles instances pour commencer à gérer le trafic. Ce n'est qu'après le transfert des données que nous pouvons configurer les nouveaux nœuds pour qu'ils fassent partie de la topologie de réplication existante - les données doivent être mises à jour en temps réel, en fonction du trafic qui atteint les autres nœuds.
Temps nécessaire pour passer à l'échelle
Le fait que les bases de données soient des services avec état est une raison directe du deuxième défi auquel nous sommes confrontés lorsque nous voulons faire évoluer l'infrastructure de base de données. Services sans état - vous venez de les démarrer et c'est tout. C'est un processus assez rapide. Pour les bases de données, vous devez transférer les données. Combien de temps cela prendra-t-il, cela dépend de plusieurs facteurs. Quelle est la taille de l'ensemble de données ? Quelle est la vitesse de stockage ? Quelle est la vitesse du réseau ? Quelles sont les autres étapes nécessaires pour provisionner le nouveau nœud avec les nouvelles données ? Les données sont-elles compressées/décompressées ou chiffrées/déchiffrées au cours du processus ? Dans le monde réel, le provisionnement des données sur un nouveau nœud peut prendre de quelques minutes à plusieurs heures. Cela limite considérablement les cas où vous pouvez faire évoluer votre environnement de base de données. Des pics de charge soudains et temporaires ? Pas vraiment, ils peuvent être partis depuis longtemps avant que vous ne puissiez démarrer des nœuds de base de données supplémentaires. Augmentation soudaine et constante de la charge ? Oui, il sera possible d'y faire face en ajoutant plus de nœuds, mais cela peut prendre même des heures pour les mettre en place et les laisser prendre en charge le trafic des nœuds de base de données existants.
Charge supplémentaire causée par le processus de mise à l'échelle
Il est très important de garder à l'esprit que le temps nécessaire à la mise à l'échelle n'est qu'un aspect du problème. L'autre côté est la charge causée par le processus de mise à l'échelle. Comme nous l'avons mentionné précédemment, vous devez transférer l'ensemble des données vers les nœuds nouvellement ajoutés. Ce n'est pas quelque chose que vous pouvez ignorer, après tout, cela peut prendre des heures pour lire les données du disque, les envoyer sur le réseau et les stocker dans un nouvel emplacement. Si le donneur, le nœud à partir duquel vous lisez les données, est surchargé, vous devez vous demander comment il se comportera s'il est forcé d'effectuer une activité d'E/S lourde supplémentaire ? Votre cluster pourra-t-il supporter une charge de travail supplémentaire s'il est déjà sous forte pression et dispersé ? La réponse n'est peut-être pas facile à obtenir car la charge sur les nœuds peut prendre différentes formes. La charge liée au processeur sera le meilleur scénario car l'activité d'E/S doit être faible et les opérations de disque supplémentaires seront gérables. La charge liée aux E/S, en revanche, peut ralentir considérablement le transfert de données, ce qui a un impact sérieux sur la capacité d'évolution du cluster.
Échelle d'écriture
Le processus de mise à l'échelle que nous avons mentionné précédemment se limite à peu près à la mise à l'échelle des lectures. Il est primordial de comprendre que la mise à l'échelle des écritures est une histoire complètement différente. Vous pouvez mettre à l'échelle les lectures en ajoutant simplement plus de nœuds et en répartissant les lectures sur plus de nœuds principaux. Les écritures ne sont pas si faciles à mettre à l'échelle. Pour commencer, vous ne pouvez pas faire évoluer les écritures comme ça. Chaque nœud contenant l'ensemble de données complet est, bien entendu, tenu de gérer toutes les écritures effectuées quelque part dans le cluster, car ce n'est qu'en appliquant toutes les modifications à l'ensemble de données qu'il peut maintenir la cohérence. Donc, quand on y pense, quelle que soit la façon dont vous concevez votre cluster et la technologie que vous utilisez, chaque membre du cluster doit exécuter chaque écriture. Qu'il s'agisse d'un réplica, répliquant toutes les écritures de son maître ou nœud dans un cluster multi-maître comme Galera ou InnoDB Cluster exécutant toutes les modifications apportées à l'ensemble de données effectuées sur tous les autres nœuds du cluster, le résultat est le même. Les écritures n'évoluent pas simplement en ajoutant plus de nœuds au cluster.
Comment pouvons-nous faire évoluer la base de données ?
Donc, nous savons à quel genre de défis nous sommes confrontés. Quelles sont les options que nous avons? Comment pouvons-nous faire évoluer la base de données ?
En ajoutant des répliques
Tout d'abord, nous allons évoluer simplement en ajoutant plus de nœuds. Bien sûr, cela prendra du temps et bien sûr, ce n'est pas un processus auquel vous pouvez vous attendre à ce qu'il se produise immédiatement. Bien sûr, vous ne pourrez pas faire évoluer les écritures comme ça. D'autre part, le problème le plus courant auquel vous serez confronté est la charge CPU causée par les requêtes SELECT et, comme nous l'avons vu, les lectures peuvent simplement être mises à l'échelle en ajoutant simplement plus de nœuds au cluster. Plus de nœuds à partir desquels lire signifie que la charge sur chacun d'eux sera réduite. Lorsque vous êtes au début de votre voyage dans le cycle de vie de votre application, supposez simplement que c'est ce à quoi vous aurez affaire. Charge CPU, requêtes non efficaces. Il est très peu probable que vous ayez besoin de faire évoluer les écritures jusqu'à une étape ultérieure du cycle de vie, lorsque votre application a déjà mûri et que vous devez gérer le nombre de clients.
Par partitionnement
L'ajout de nœuds ne résoudra pas le problème d'écriture, c'est ce que nous avons établi. Ce que vous devez faire à la place, c'est le sharding - diviser l'ensemble de données sur le cluster. Dans ce cas, chaque nœud ne contient qu'une partie des données, pas tout. Cela nous permet enfin de commencer à dimensionner les écritures. Disons que nous avons quatre nœuds, chacun contenant la moitié de l'ensemble de données.
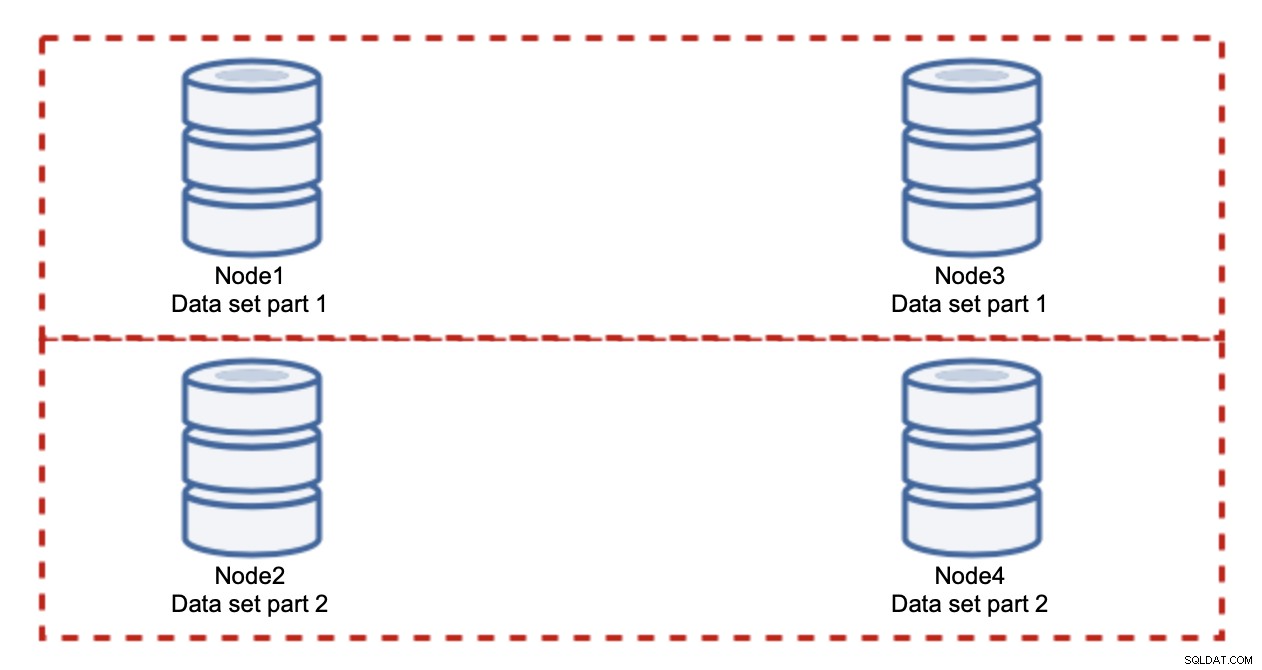
Comme vous pouvez le voir, l'idée est simple. Si l'écriture est liée à la partie 1 de l'ensemble de données, elle sera exécutée sur node1 et node3. S'il est lié à la partie 2 du jeu de données, il sera exécuté sur node2 et node4. Vous pouvez considérer les nœuds de base de données comme des disques dans un RAID. Ici, nous avons un exemple de RAID10, deux paires de miroirs, pour la redondance. Dans une implémentation réelle, cela peut être plus complexe, vous pouvez avoir plus d'une réplique des données pour une haute disponibilité améliorée. L'essentiel est, en supposant une répartition parfaitement équitable des données, la moitié des écritures atteindra le nœud 1 et le nœud 3 et l'autre moitié les nœuds 2 et 4. Si vous souhaitez diviser encore plus la charge, vous pouvez introduire la troisième paire de nœuds :
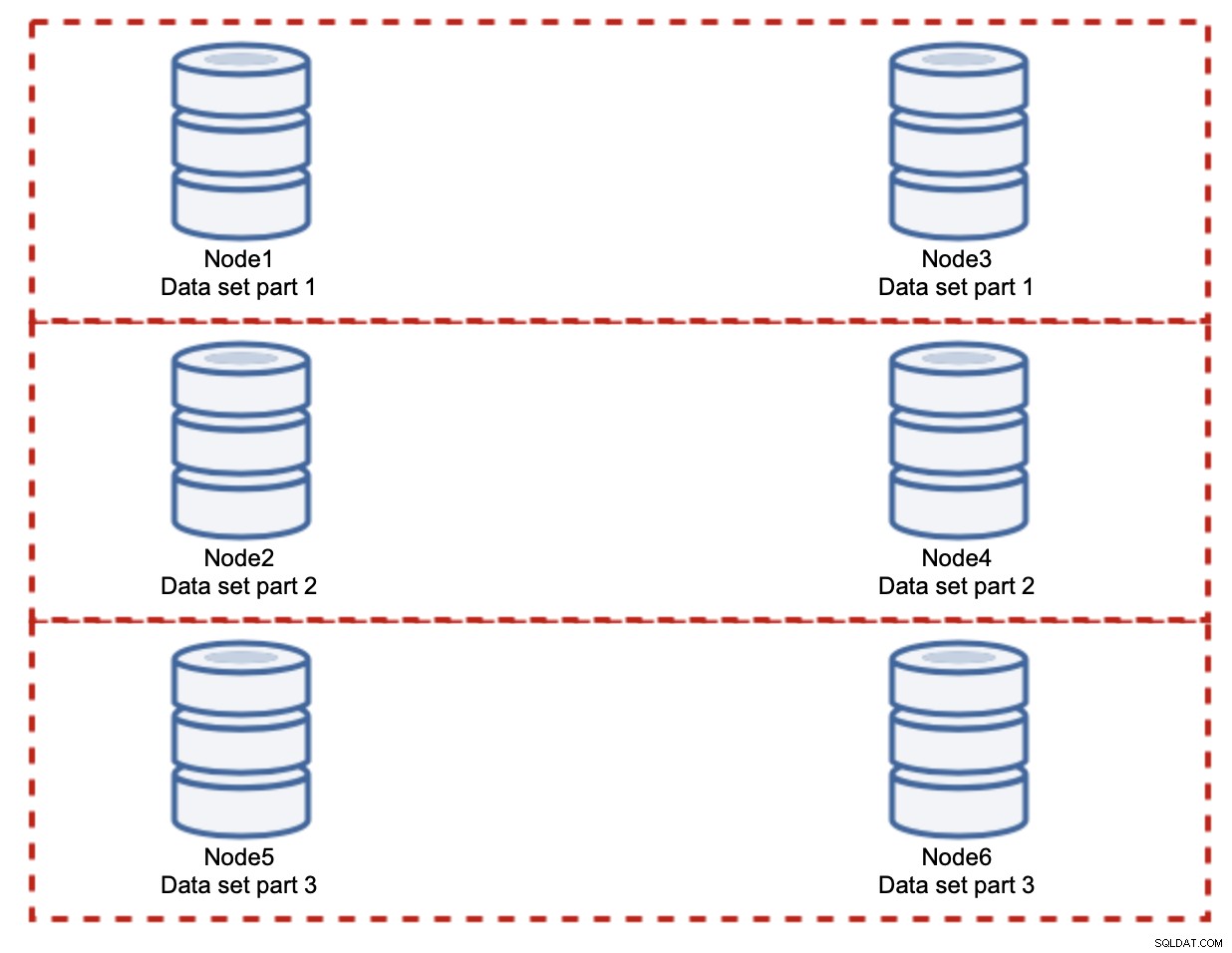
Dans ce cas, encore une fois, en supposant une répartition parfaitement équitable, chaque paire sera être responsable de 33 % de toutes les écritures sur le cluster.
Cela résume assez bien l'idée du sharding. Dans notre exemple, en ajoutant plus de partitions, nous pouvons réduire l'activité d'écriture sur les nœuds de la base de données à 33 % de la charge d'E/S d'origine. Comme vous pouvez l'imaginer, cela ne va pas sans inconvénients.
Comment vais-je savoir sur quelle partition se trouvent mes données ? Les détails sortent du cadre de cet appel mais en bref, vous pouvez soit implémenter une sorte de fonction sur une colonne donnée (modulo ou hachage sur la colonne 'id') ou vous pouvez créer une métadatabase séparée où vous stockerez les détails de la façon dont les données sont distribuées.
Nous espérons que vous avez trouvé cette courte série de blogs instructive et que vous avez mieux compris les différents défis auxquels nous sommes confrontés lorsque nous voulons faire évoluer l'environnement de base de données. Si vous avez des commentaires ou des suggestions sur ce sujet, n'hésitez pas à commenter sous cet article et à partager votre expérience