Vous avez peut-être entendu parler du terme « cerveau divisé ». Ce que c'est? Comment cela affecte-t-il vos clusters ? Dans cet article de blog, nous discuterons de quoi il s'agit exactement, du danger qu'il peut représenter pour votre base de données, de la manière dont nous pouvons l'éviter et, si tout se passe mal, de la manière de s'en remettre.
L'époque des instances uniques est révolue depuis longtemps. De nos jours, presque toutes les bases de données fonctionnent dans des groupes ou des clusters de réplication. C'est idéal pour la haute disponibilité et l'évolutivité, mais une base de données distribuée introduit de nouveaux dangers et limitations. Un cas qui peut être mortel est une scission du réseau. Imaginez un cluster de plusieurs nœuds qui, en raison de problèmes de réseau, a été divisé en deux parties. Pour des raisons évidentes (cohérence des données), les deux parties ne doivent pas gérer le trafic en même temps car elles sont isolées l'une de l'autre et les données ne peuvent pas être transférées entre elles. C'est également faux du point de vue de l'application - même si, à terme, il y aurait un moyen de synchroniser les données (bien que la réconciliation de 2 jeux de données ne soit pas anodine). Pendant un certain temps, une partie de l'application ne serait pas au courant des modifications apportées par d'autres hôtes d'application, qui accèdent à l'autre partie du cluster de bases de données. Cela peut entraîner de graves problèmes.
La condition dans laquelle le cluster a été divisé en deux ou plusieurs parties qui sont prêtes à accepter des écritures est appelée "split brain".
Le plus gros problème avec le split brain est la dérive des données, car les écritures se produisent sur les deux parties du cluster. Aucune des versions de MySQL ne fournit de moyen automatisé de fusionner des ensembles de données qui ont divergé. Vous ne trouverez pas une telle fonctionnalité dans la réplication MySQL, la réplication de groupe ou Galera. Une fois que les données ont divergé, la seule option est d'utiliser l'une des parties du cluster comme source de vérité et d'ignorer les modifications exécutées sur l'autre partie - à moins que nous puissions suivre un processus manuel afin de fusionner les données.
C'est pourquoi nous commencerons par la façon d'empêcher le cerveau divisé de se produire. C'est tellement plus facile que d'avoir à corriger toute divergence de données.
Comment prévenir la division du cerveau
La solution exacte dépend du type de base de données et de la configuration de l'environnement. Nous examinerons certains des cas les plus courants pour Galera Cluster et la réplication MySQL.
Pôle Galera
Galera dispose d'un « disjoncteur » intégré pour gérer le cerveau divisé :il s'appuie sur un mécanisme de quorum. Si une majorité (50 % + 1) des nœuds sont disponibles dans le cluster, Galera fonctionnera normalement. S'il n'y a pas de majorité, Galera cessera de desservir le trafic et passera à l'état dit "non primaire". C'est à peu près tout ce dont vous avez besoin pour faire face à une situation de cerveau partagé lors de l'utilisation de Galera. Bien sûr, il existe des méthodes manuelles pour forcer Galera à passer à l'état "Primaire" même s'il n'y a pas de majorité. Le fait est qu'à moins que vous ne fassiez cela, vous devriez être en sécurité.
La façon dont le quorum est calculé a des répercussions importantes - à un seul niveau de centre de données, vous souhaitez avoir un nombre impair de nœuds. Trois nœuds vous donnent une tolérance pour l'échec d'un nœud (2 nœuds correspondent à l'exigence de plus de 50 % des nœuds du cluster disponibles). Cinq nœuds vous donneront une tolérance de défaillance de deux nœuds (5 - 2 =3 soit plus de 50 % à partir de 5 nœuds). D'autre part, l'utilisation de quatre nœuds n'améliorera pas votre tolérance sur un cluster à trois nœuds. Il ne gérerait toujours qu'une défaillance d'un nœud (4 - 1 =3, plus de 50 % de 4) tandis que la défaillance de deux nœuds rendra le cluster inutilisable (4 - 2 =2, seulement 50 %, pas plus).
Lors du déploiement du cluster Galera dans un seul centre de données, gardez à l'esprit que, idéalement, vous souhaitez répartir les nœuds sur plusieurs zones de disponibilité (source d'alimentation, réseau, etc.) - tant qu'ils existent dans votre centre de données, c'est-à-dire . Une configuration simple peut ressembler à celle ci-dessous :
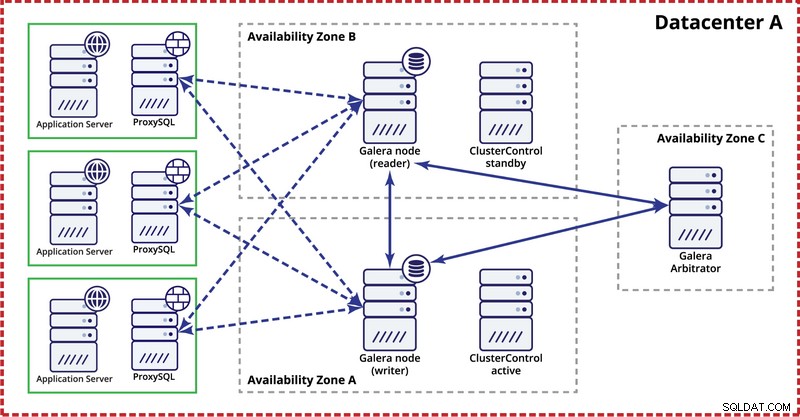
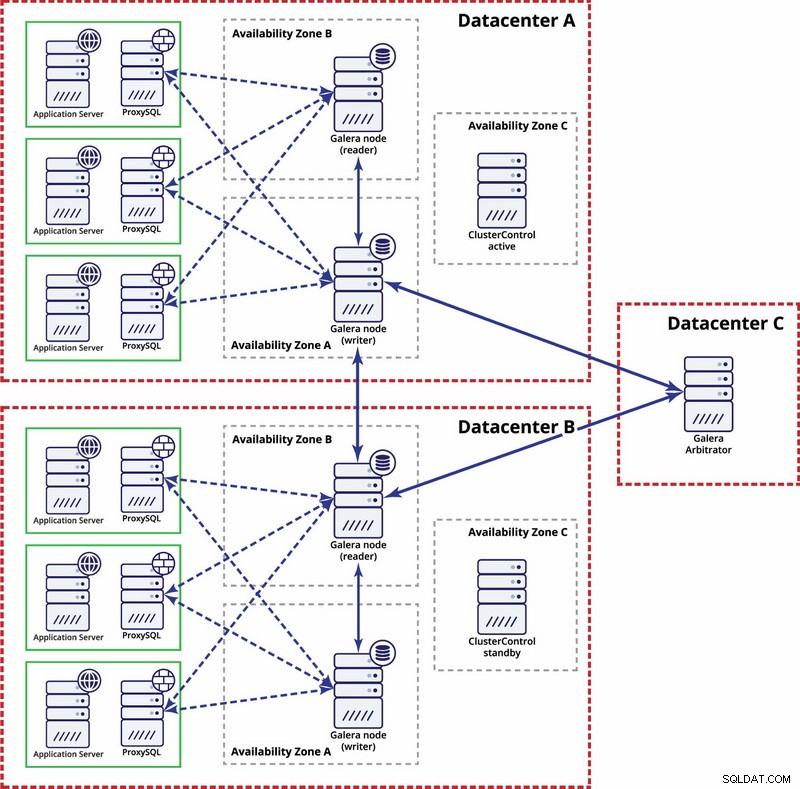
Au niveau multi-centre de données, ces considérations sont également applicables. Si vous souhaitez que le cluster Galera gère automatiquement les défaillances du centre de données, vous devez utiliser un nombre impair de centres de données. Pour réduire les coûts, vous pouvez utiliser un arbitre Galera dans l'un d'eux au lieu d'un nœud de base de données. Galera arbitre (garbd) est un processus qui participe au calcul du quorum mais il ne contient aucune donnée. Cela permet de l'utiliser même sur de très petites instances car il ne consomme pas beaucoup de ressources - bien que la connectivité réseau doive être bonne car il "voit" tout le trafic de réplication. Un exemple de configuration peut ressembler au schéma ci-dessous :
Réplication MySQL
Avec la réplication MySQL, le plus gros problème est qu'il n'y a pas de mécanisme de quorum intégré, comme c'est le cas dans le cluster Galera. Par conséquent, d'autres étapes sont nécessaires pour s'assurer que votre configuration ne sera pas affectée par un split brain.
Une méthode consiste à éviter les basculements automatisés entre centres de données. Vous pouvez configurer votre solution de basculement (elle peut être via ClusterControl, ou MHA ou Orchestrator) pour basculer uniquement dans un seul centre de données. S'il y avait une panne complète du centre de données, il appartiendrait à l'administrateur de décider comment basculer et comment s'assurer que les serveurs du centre de données défaillant ne seront pas utilisés.
Il existe des options pour le rendre plus automatisé. Vous pouvez utiliser Consul pour stocker des données sur les nœuds dans la configuration de réplication, et lequel d'entre eux est le maître. Il appartiendra ensuite à l'administrateur (ou via des scripts) de mettre à jour cette entrée et de déplacer les écritures vers le deuxième centre de données. Vous pouvez bénéficier d'une configuration Orchestrator/Raft dans laquelle les nœuds Orchestrator peuvent être répartis sur plusieurs centres de données et détecter le split brain. Sur cette base, vous pouvez prendre différentes mesures comme, comme nous l'avons mentionné précédemment, mettre à jour les entrées dans notre Consul ou etcd. Le fait est qu'il s'agit d'un environnement beaucoup plus complexe à configurer et à automatiser que le cluster Galera. Vous trouverez ci-dessous un exemple de configuration multi-centre de données pour la réplication MySQL.
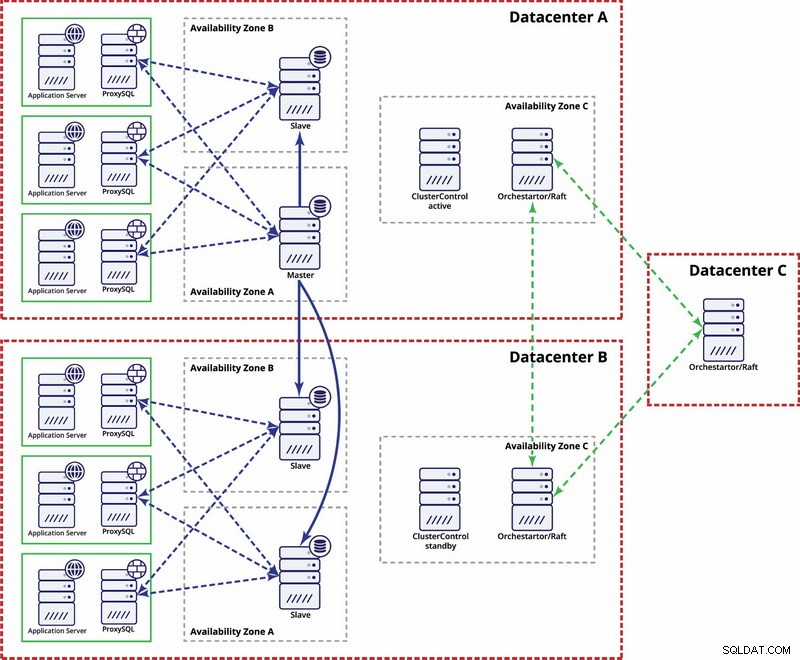
Veuillez garder à l'esprit que vous devez toujours créer des scripts pour le faire fonctionner, c'est-à-dire surveiller les nœuds Orchestrator pour un cerveau divisé et prendre les mesures nécessaires pour implémenter STONITH et vous assurer que le maître du centre de données A ne sera pas utilisé une fois que le réseau convergera et que la connectivité sera être restauré.
Split Brain Happened - Que faire ensuite ?
Le pire scénario s'est produit et nous avons une dérive des données. Nous allons essayer de vous donner quelques conseils sur ce qui peut être fait ici. Malheureusement, les étapes exactes dépendront principalement de la conception de votre schéma, il ne sera donc pas possible d'écrire un guide pratique précis.
Ce que vous devez garder à l'esprit, c'est que le but ultime sera de copier les données d'un maître à l'autre et de recréer toutes les relations entre les tables.
Tout d'abord, vous devez identifier quel nœud continuera à servir les données en tant que maître. Il s'agit d'un jeu de données dans lequel vous fusionnerez les données stockées sur l'autre instance "maître". Une fois cela fait, vous devez identifier les données de l'ancien maître qui manquent sur le maître actuel. Ce sera un travail manuel. Si vous avez des horodatages dans vos tables, vous pouvez les exploiter pour identifier les données manquantes. En fin de compte, les journaux binaires contiendront toutes les modifications de données afin que vous puissiez vous y fier. Vous devrez peut-être également vous fier à votre connaissance de la structure des données et des relations entre les tables. Si vos données sont normalisées, un enregistrement d'une table peut être lié à des enregistrements d'autres tables. Par exemple, votre application peut insérer des données dans la table "utilisateur" qui est liée à la table "adresse" en utilisant user_id. Vous devrez trouver toutes les lignes associées et les extraire.
La prochaine étape consistera à charger ces données dans le nouveau maître. Voici la partie délicate - si vous avez préparé vos configurations à l'avance, cela pourrait être simplement une question d'exécution de quelques insertions. Sinon, cela peut être assez complexe. Tout est question de clé primaire et de valeurs d'index uniques. Si vos valeurs de clé primaire sont générées comme uniques sur chaque serveur à l'aide d'une sorte de générateur d'UUID ou à l'aide des paramètres auto_increment_increment et auto_increment_offset dans MySQL, vous pouvez être sûr que les données de l'ancien maître que vous devez insérer ne causeront pas de clé primaire ou unique la clé est en conflit avec les données du nouveau maître. Sinon, vous devrez peut-être modifier manuellement les données de l'ancien fichier maître pour vous assurer qu'elles peuvent être insérées correctement. Cela semble complexe, alors regardons un exemple.
Imaginons que nous insérions des lignes en utilisant auto_increment sur le nœud A, qui est un maître. Par souci de simplicité, nous nous concentrerons sur une seule ligne. Il y a des colonnes 'id' et 'value'.
Si nous l'insérons sans aucune configuration particulière, nous verrons des entrées comme ci-dessous :
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Ceux-ci seront répliqués sur l'esclave (B). Si le cerveau divisé se produit et que les écritures seront exécutées à la fois sur l'ancien et le nouveau maître, nous nous retrouverons dans la situation suivante :
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Comme vous pouvez le voir, il n'y a aucun moyen de simplement vider les enregistrements avec les identifiants 1004, 1005 et 1006 du nœud A et de les stocker sur le nœud B car nous nous retrouverons avec des entrées de clé primaire dupliquées. Ce qu'il faut faire, c'est changer les valeurs de la colonne id dans les lignes qui seront insérées à une valeur supérieure à la valeur maximale de la colonne id de la table. C'est tout ce qui est nécessaire pour les rangées simples. Pour les relations plus complexes, impliquant plusieurs tables, vous devrez peut-être apporter les modifications à plusieurs emplacements.
D'autre part, si nous avions anticipé ce problème potentiel et configuré nos nœuds pour stocker les identifiants impairs sur le nœud A et les identifiants pairs sur le nœud B, le problème aurait été tellement plus facile à résoudre.
Le nœud A a été configuré avec auto_increment_offset =1 et auto_increment_increment =2
Le nœud B a été configuré avec auto_increment_offset =2 et auto_increment_increment =2
Voici à quoi ressembleraient les données sur le nœud A avant le split brain :
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Lorsque le cerveau divisé s'est produit, cela ressemblera à ci-dessous.
Nœud A :
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Nœud B :
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Maintenant, nous pouvons facilement copier les données manquantes du nœud A :
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Et chargez-le sur le nœud B pour obtenir l'ensemble de données suivant :
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Bien sûr, les lignes ne sont pas dans l'ordre d'origine, mais cela devrait être correct. Dans le pire des cas, vous devrez trier par colonne "valeur" dans les requêtes et peut-être y ajouter un index pour accélérer le tri.
Maintenant, imaginez des centaines ou des milliers de lignes et une structure de table hautement normalisée - pour restaurer une ligne, vous devrez peut-être en restaurer plusieurs dans des tables supplémentaires. Avec un besoin de changer les identifiants (parce que vous n'aviez pas de paramètres de protection en place) sur toutes les lignes associées et tout cela étant un travail manuel, vous pouvez imaginer que ce n'est pas la meilleure situation dans laquelle se trouver. Il faut du temps pour récupérer et c'est un processus sujet aux erreurs. Heureusement, comme nous en avons discuté au début, il existe des moyens de minimiser les risques que le cerveau divisé ait un impact sur votre système ou de réduire le travail qui doit être fait pour synchroniser vos nœuds. Assurez-vous de les utiliser et restez prêt.