Les benchmarks sont l'une des activités effectuées par les administrateurs de bases de données. Vous les exécutez pour voir comment votre matériel se comporte, vous les exécutez pour voir comment votre application et votre base de données fonctionnent ensemble sous pression. Vous les exécutez dans de nombreuses situations différentes. Parlons un peu d'eux, quels sont les défis auxquels vous allez être confrontés, quels sont les problèmes que vous devriez éviter.
Types de benchmarks
Chaque benchmark est différent. Ils servent à des fins différentes et cela doit être pris en compte lorsque vous envisagez d'en exécuter un. En général, vous pouvez définir deux principaux types de benchmark :un benchmark synthétique et, disons-le, un benchmark "du monde réel".
Les benchmarks synthétiques sont généralement des outils qui simulent une sorte de charge de travail. Il peut s'agir d'une charge de travail OLTP comme dans le cas de Sysbench, il peut s'agir d'un benchmark "standard" comme dans TPC-C ou TPC-H. Habituellement, l'idée est qu'un tel benchmark simule une sorte de charge de travail et cela peut être utile si votre charge de travail réelle suit le même schéma. Il peut également être utilisé pour déterminer comment votre combinaison de configuration matérielle et de base de données fonctionne ensemble sous un type de charge de travail donné. Les avantages des benchmarks synthétiques sont assez clairs. Vous pouvez les exécuter partout, ils ne dépendent pas d'une configuration ou d'une conception de schéma particulière. Eh bien, ils le font, mais ils proposent des outils pour tout configurer à partir du serveur de base de données vide. Le principal inconvénient est que ce n'est pas votre charge de travail. Si vous envisagez d'exécuter des tests OLTP à l'aide de Sysbench, vous devez garder à l'esprit que votre application ne sera jamais Sysbench. Il peut également exécuter une charge de travail OLTP, mais la combinaison de requêtes sera différente. Jamais, en aucune circonstance, un benchmark synthétique ne vous dira exactement comment votre application se comportera sur un mélange matériel/configuration donné.
À l'autre extrémité du spectre, nous avons ce que nous appelons des références du "monde réel". Nous entendons ici par là un benchmark qui utilise un ensemble de données et des requêtes liées à votre application. Il ne dispose pas toujours d'un ensemble de données complet et d'un mélange complet de requêtes. Vous voudrez peut-être vous concentrer sur certaines parties de votre application, mais l'idée principale derrière cela est que vous voulez comprendre les interactions exactes entre l'application, le matériel et la configuration de la base de données, soit en général, soit dans un aspect particulier.
Comme nous l'avons mentionné ci-dessus, nous avons deux principaux types de benchmarks différents, mais ils ont tout de même des éléments communs que vous devez prendre en compte lorsque vous essayez d'exécuter les benchmarks.
-
Décidez ce que vous voulez tester
Tout d'abord, le benchmarking pour le plaisir d'exécuter des benchmarks est inutile. Il doit être conçu pour accomplir réellement quelque chose. Que voulez-vous retirer de la course de référence ? Voulez-vous régler les requêtes ? Vous souhaitez peaufiner la configuration ? Vous souhaitez évaluer la scalabilité de votre stack ? Voulez-vous préparer votre pile pour une charge plus élevée ? Souhaitez-vous effectuer un réglage de configuration générique pour un nouveau projet ? Vous souhaitez déterminer les meilleurs paramètres pour votre matériel ? Ce sont des exemples d'objectifs que vous voudrez peut-être atteindre. Chacun d'entre eux nécessitera une approche différente et une configuration de référence différente.
-
Effectuer une modification à la fois
Quoi que vous testiez et peaufiniez, il est de la plus haute importance que vous ne fassiez qu'un seul changement de configuration à la fois. C'est vraiment critique. Le benchmark est destiné à vous donner une idée de la performance. Requêtes par seconde, latence, 99 centiles, tout cela vous indique à quelle vitesse vous pouvez exécuter les requêtes et à quel point la charge de travail est stable et prévisible. Il est facile de dire si la modification que vous avez apportée à la configuration, au matériel ou à la combinaison de requêtes change quoi que ce soit :les métriques du benchmark seront différentes. Le fait est que si vous apportez quelques modifications en même temps, il n'y a aucun moyen de savoir lequel est responsable du résultat global. Cela peut aller encore plus loin que cela. Supposons que vous avez modifié deux valeurs dans la configuration de la base de données. Valeur A et B. L'amélioration globale est de 20%, ce qui est assez bon pour un simple changement de configuration. Sous le capot, cependant, le changement de la valeur A a apporté une amélioration de 30 % tandis que le changement supplémentaire de la valeur B l'a ramenée à 20 %. Avec plusieurs changements en même temps, vous ne pouvez qu'observer leur impact commun, ce n'est pas le moyen de déterminer correctement le résultat de chaque changement que vous avez effectué. Bien sûr, cela augmente considérablement le temps que vous passerez à exécuter le benchmark, mais c'est comme ça.
-
Effectuer plusieurs exécutions de référence
Les ordinateurs sont des systèmes complexes en eux-mêmes. Ils ont plusieurs composants qui interagissent les uns avec les autres :mémoire, CPU, disque, réseau. Ajoutons ensuite à cette virtualisation, la conteneurisation. Puis logiciel - système d'exploitation, application, base de données. Couche sur couche sur couche sur couche d'éléments qui interagissent d'une manière ou d'une autre. Il n'est pas facile de prédire son comportement. Eh bien, vous pouvez dire qu'il est presque impossible de prédire avec précision le comportement de systèmes aussi complexes. C'est la raison pour laquelle l'exécution d'un test de référence n'est pas suffisante pour tirer les conclusions. Et si, à votre insu, un élément, totalement sans rapport avec ce que vous souhaitez tester, impactait la performance globale ? Charge élevée sur une autre machine virtuelle située sur le même hôte. Un autre serveur diffuse la sauvegarde sur le réseau. Cela peut avoir un impact temporaire sur les performances et fausser les résultats de référence. Si vous n'exécutez qu'un seul test de référence, vous obtiendrez des résultats incorrects. C'est pourquoi la meilleure pratique consiste à exécuter plusieurs passes d'un benchmark, puis à supprimer la plus lente et la plus rapide, en faisant la moyenne des autres.
-
Une image vaut des milliers de mots
Eh bien, c'est à peu près une description très précise de l'analyse comparative. Dans la mesure du possible, générez toujours des graphiques. Idéalement, suivez les métriques pendant le benchmark aussi souvent que possible. Une seconde de granularité devrait suffire dans la plupart des cas. Pour éviter d'écrire des milliers de mots, nous allons inclure cet exemple. Que pensez-vous est plus utile? Cet ensemble de résultats de référence représente le RPS moyen pour chacune des 10 passes, chaque passe prenant 600 secondes
11650.52
11237.97
11550.16
11247.08
11177.78
11163.76
11131.47
11235.06
11235.59
11277.25
Ou ce tracé :
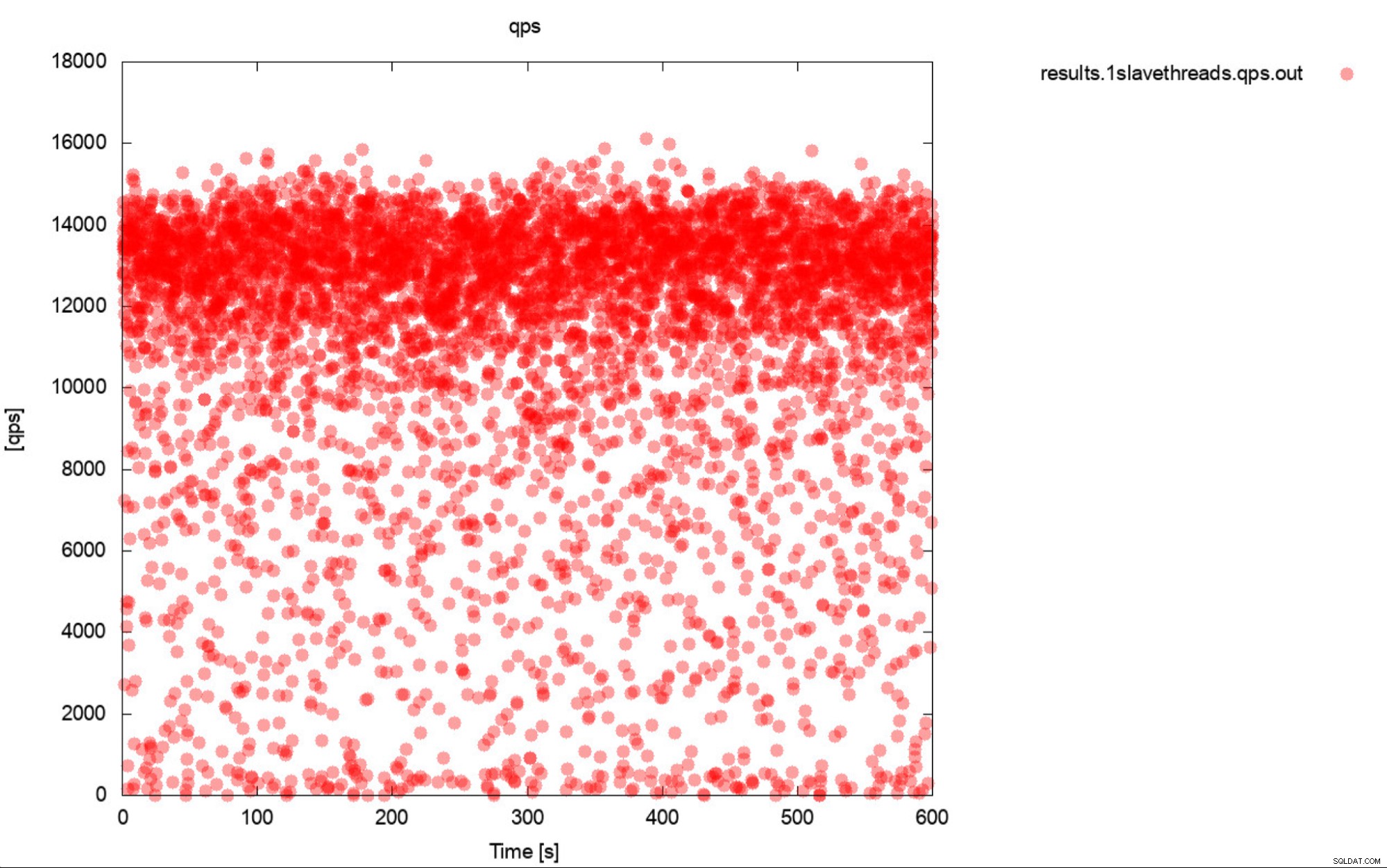
Le QPS moyen est de 11 000, mais la réalité est que les performances sont omniprésentes place, y compris les dips à 0 requêtes exécutées en une seconde, et c'est certainement quelque chose que vous voulez travailler et améliorer sur les systèmes de production.
-
Les requêtes par seconde ne sont pas la mesure la plus importante
Vous pensez peut-être que la requête par seconde est le Saint Graal de la performance car elle représente le nombre de requêtes qu'une base de données peut exécuter en une seconde. La vérité est que ce n'est pas la mesure la plus importante, surtout si nous parlons de la sortie moyenne d'un benchmark. QPS représente le débit mais ignore la latence. Vous pouvez essayer de pousser un grand nombre de requêtes, mais vous finissez par attendre qu'elles renvoient des résultats. Ce n'est pas ce que les utilisateurs attendent de l'application. Les utilisateurs s'attendent à des performances stables. Il n'est pas nécessaire que cela soit extrêmement rapide, mais lorsqu'une action prend une seconde pour se terminer, nous avons tendance à nous attendre à ce que l'exécution de cette action prenne toujours cette 1 seconde. Si, pour une raison quelconque, cela commence à prendre plus de temps, les humains ont tendance à devenir anxieux. C'est la principale raison pour laquelle nous avons tendance à préférer la latence, en particulier son P99 (99e centile) comme métrique plus fiable. La latence nous indique combien de temps l'application a dû attendre le résultat de la base de données. P99 nous indique une latence inférieure à 99 % des requêtes. Disons que nous avons un P99 de 100 ms, cela signifie que 99 % des requêtes renvoient des résultats pas plus lents que 100 ms. Si la latence P99 est faible, cela signifie que presque toutes les requêtes reviennent rapidement et s'exécutent de manière stable et prévisible. C'est quelque chose que nos utilisateurs veulent voir.
-
Comprendre ce qui se passe avant de tirer des conclusions
Dernier point que nous avons dans ce court blog mais nous dirions que c'est le plus important. Vous verrez différents résultats et comportements étranges et inattendus lors des benchmarks. Pire encore, vous pouvez voir des résultats assez standard, répétitifs mais toujours imparfaits. La plupart d'entre eux peuvent être liés au comportement de la base de données ou du matériel. C'est vraiment crucial - avant de prendre le résultat pour acquis, vous devriez être en mesure d'expliquer le comportement et de décrire ce qui s'est passé. Nous savons que ce n'est pas facile et nous savons que cela nécessite vraiment des connaissances spécifiques à la base de données, en particulier des connaissances liées aux composants internes de la base de données. Nous savons que dans le monde réel, les gens ne s'en soucient généralement pas, ils veulent juste obtenir des résultats. Le fait est que, en particulier dans les cas où vous essayez d'améliorer les performances grâce à la configuration ou à des ajustements matériels, comprendre ce qui s'est passé sous le capot vous permet de choisir la bonne manière dont votre réglage doit se dérouler. Il permet également de dire si le benchmark qui a été exécuté peut avoir un sens. Testons-nous réellement le bon élément ? Un exemple serait un test exécuté sur le réseau (car vous ne voudriez pas utiliser les cœurs de processeur locaux du nœud de base de données pour l'outil de référence). Il est fort probable que le réseau lui-même et la charge CPU de softirq soient le facteur limitant, bien avant que vous ne rencontriez des goulots d'étranglement "attendus" comme la saturation du CPU. Si vous n'êtes pas conscient de votre environnement et de son comportement, vous mesurerez les performances de votre réseau pour transférer de gros volumes de données, et non les performances du processeur.
Comme vous pouvez le voir, l'analyse comparative n'est pas la chose la plus facile à faire, vous devez avoir un niveau de conscience de ce qui se passe, vous devez avoir un plan approprié pour ce que vous allez faire et tu veux tester quoi ? Dans la prochaine partie de ce blog, nous allons passer en revue certains des cas de test du monde réel. Qu'est-ce qui peut mal tourner, quels problèmes nous allons rencontrer et comment les résoudre.