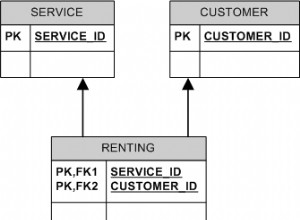
Je suis d'accord avec @marc_s et @KM que ce grand dessein est voué à l'échec dès le départ.
Des millions d'heures de développement de Microsoft ont été consacrées à la construction et au réglage fin d'un moteur de base de données robuste et puissant, mais vous allez tout réinventer en mettant tout dans un petit nombre de tables génériques et en réimplémentant tout ce que SQL Server est déjà. conçu pour faire pour vous.
SQL Server possède déjà des tables contenant des noms d'entités, des noms de colonnes, etc. Le fait que vous n'interagissiez normalement pas directement avec ces tables système est une bonne chose :c'est ce qu'on appelle l'abstraction. Et il est peu probable que vous fassiez un meilleur travail d'implémentation de cette abstraction que ne le fait SQL Server.
En fin de compte, avec votre approche (a), même les requêtes les plus simples seront monstrueuses ; et (b) vous ne vous approcherez jamais des performances optimales, car vous renoncez à toute l'optimisation des requêtes que vous obtiendriez autrement gratuitement.
Sans en savoir plus sur votre application ou vos besoins, il est difficile de donner des conseils spécifiques. Mais je dirais qu'une bonne vieille normalisation irait loin. Toute base de données non triviale et bien implémentée contient de nombreuses tables ; dix tables plus dix tables xtab ne devraient pas vous effrayer.
Et n'ayez pas peur de la génération de code SQL comme moyen d'implémenter des interfaces communes sur des tables disparates. Un peu peut aller loin.