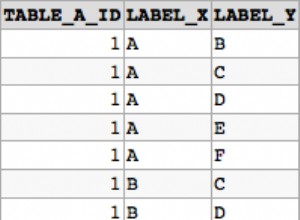
Frederik le résume bien, et c'est vraiment ce que Kimberly Tripp prêche également :la clé de regroupement doit être stable (ne change jamais), toujours croissante (IDENTITY INT), petite et unique.
Dans votre scénario, je préfère de loin placer la clé de clustering sur la colonne BIGINT plutôt que sur la colonne VARCHAR(80).
Tout d'abord, avec la colonne BIGINT, il est relativement facile d'imposer l'unicité (si vous n'appliquez pas et ne garantissez pas l'unicité vous-même, SQL Server ajoutera un "uniquefier" de 4 octets à chacune de vos lignes) et c'est BEAUCOUP plus petit en moyenne qu'un VARCHAR(80).
Pourquoi la taille est-elle si importante ? La clé de clustering sera également ajoutée à CHACUN et à chacun de vos index non clusterisés - donc si vous avez beaucoup de lignes et beaucoup d'index non clusterisés, avoir 40-80 octets contre 8 octets peut rapidement faire un ÉNORME différence.
Aussi, un autre conseil de performance :afin d'éviter les soi-disant recherches de signet (à partir d'une valeur dans votre index non clusterisé via la clé de clustering dans les pages feuille de données réelles), SQL Server 2005 a introduit la notion de "colonnes incluses" dans vos index non clusterisés. Ceux-ci sont extrêmement utiles et souvent négligés. Si vos requêtes nécessitent souvent les champs d'index plus seulement un ou deux autres champs de la base de données, pensez à les inclure afin d'obtenir ce que l'on appelle des "index de couverture". Encore une fois - voir l'excellent article de Kimberly Tripp - c'est la déesse de l'indexation SQL Server ! :-) et elle peut expliquer ce genre de choses bien mieux que moi...
Donc, pour résumer :placez votre clé de clustering sur une petite colonne stable et unique - et tout ira bien !
Marc